标签:包含 形式 for turn dbf UNC 很多 span cti



V:传函数名调用
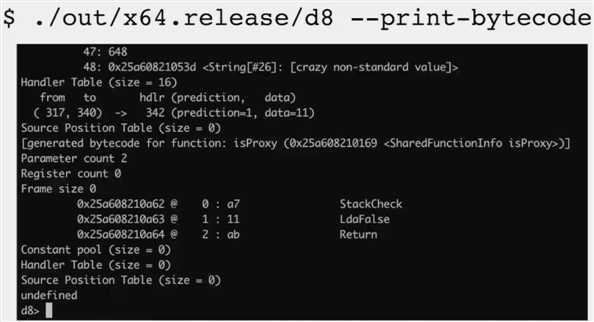
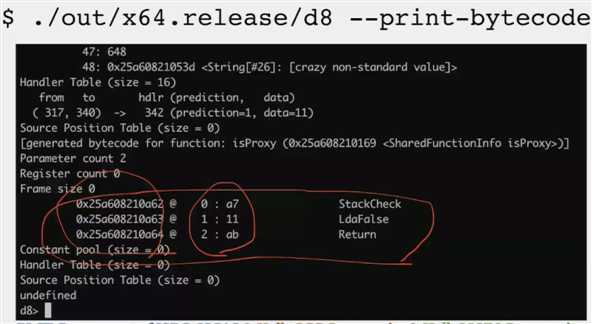
第一列是地址
相对偏移
a7 11 对应的是字节码(字节码对应的二进制数字实例,转化成16进制的样子)
助记符:LdaFalse —— LD 是 load,a 是accumulator,False/Zero 等都专门分配了一个字节码,进行过特殊化的处理
原文:Understanding V8’s Bytecode
作者:Franziska Hinkelmann
译者:justjavac
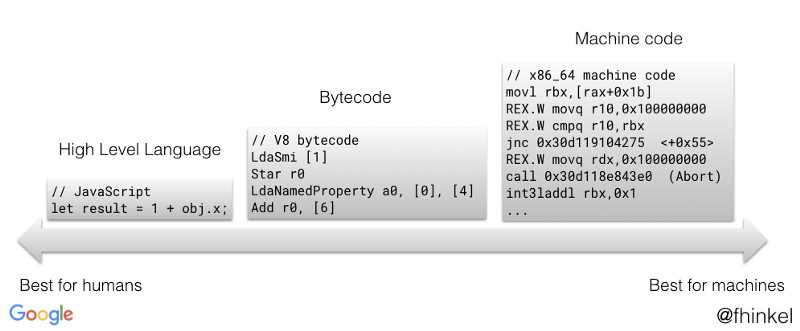
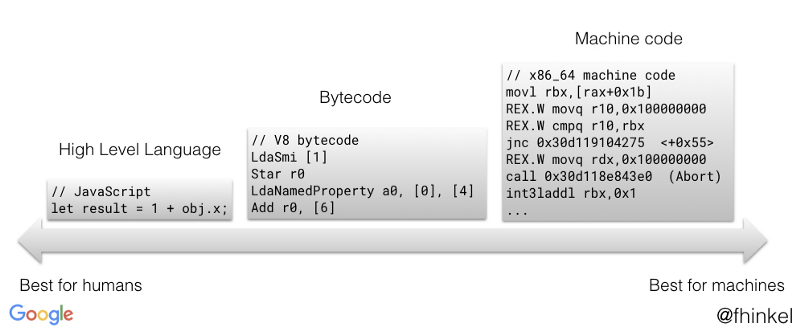
V8 是 Google 开发的开源 JavaScript 引擎。 Chrome、Node.js和许多其他应用程序都在使用 V8。本文介绍了 V8 的字节码格式—— 如果你了解关于字节码的基本概念,读起来会更加轻松。

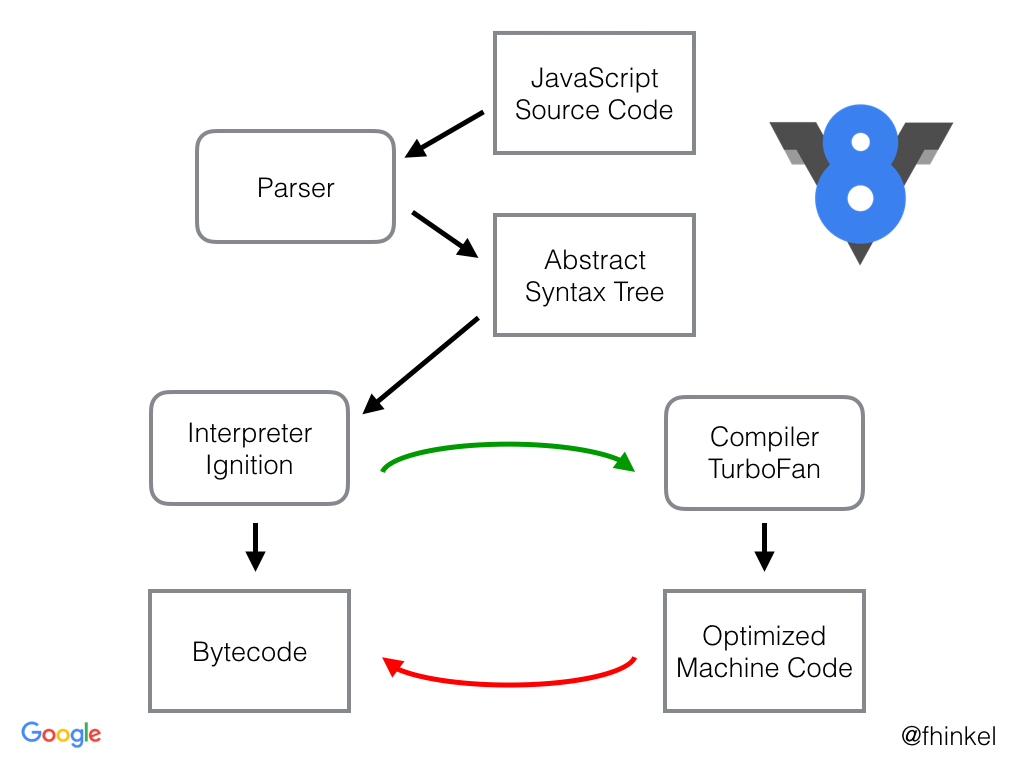
当 V8 编译 JavaScript 代码时,解析器(parser)将生成一个抽象语法树。语法树是 JavaScript 代码的句法结构的树形表示形式。解释器 Ignition 根据语法树生成字节码。TurboFan 是 V8 的优化编译器,TurboFan 将字节码生成优化的机器代码。
如果想知道为什么会有两种执行模式,可以从 JSConfEU 查看我(原作者)的视频(YouTube需科学地上网):
Franziska Hinkelmann: JavaScript engines - how do they even? | JSConf EU 2017
字节码是机器代码的抽象。如果字节码采用和物理 CPU 相同的计算模型进行设计,则将字节码编译为机器代码更容易。这就是为什么解释器(interpreter)常常是寄存器或堆栈。 Ignition 是具有累加器的寄存器。
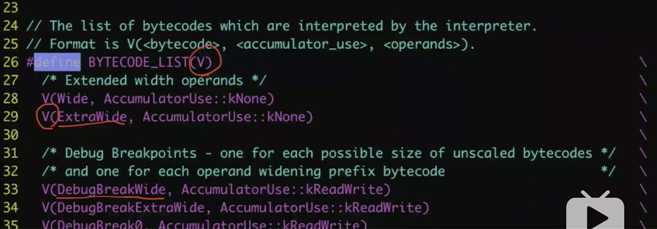
您可以将 V8 的字节码看作是小型的构建块(bytecodes as small building blocks),这些构建块组合在一起构成任何 JavaScript 功能。V8 有数以百计的字节码。比如 Add 或 TypeOf 这样的操作符,或者像 LdaNamedProperty 这样的属性加载符,还有很多类似的字节码。 V8还有一些非常特殊的字节码,如 CreateObjectLiteral 或 SuspendGenerator。头文件 bytecodes.h 定义了 V8 字节码的完整列表。
每个字节码指定其输入和输出作为寄存器操作数。Ignition 使用寄存器 r0,r1,r2,... 和累加器寄存器(accumulator register)。几乎所有的字节码都使用累加器寄存器。它像一个常规寄存器,除了字节码没有指定。 例如,Add r1 将寄存器 r1 中的值和累加器中的值进行加法运算。这使得字节码更短,节省内存。
许多字节码以 Lda 或 Sta 开头。Lda 和 Stastands 中的 a 为累加器(accumulator)。例如,LdaSmi [42] 将小整数(Smi)42 加载到累加器寄存器中。Star r0 将当前在累加器中的值存储在寄存器 r0 中。
以现在掌握的基础知识,花点时间来看一个具有实际功能的字节码。
function incrementX(obj) {
return 1 + obj.x;
}
incrementX({x: 42}); // V8 的编译器是惰性的,如果一个函数没有运行,V8 将不会解释它
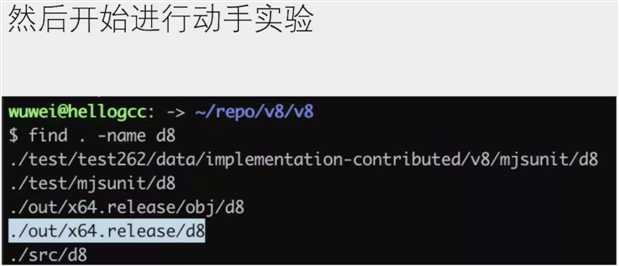
如果要查看 V8 的 JavaScript 字节码,可以使用在命令行参数中添加 --print-bytecode 运行 D8 或Node.js(8.3 或更高版本)来打印。对于 Chrome,请从命令行启动 Chrome,使用 --js-flags="--print-bytecode",请参考 Run Chromium with flags。
$ node --print-bytecode incrementX.js
...
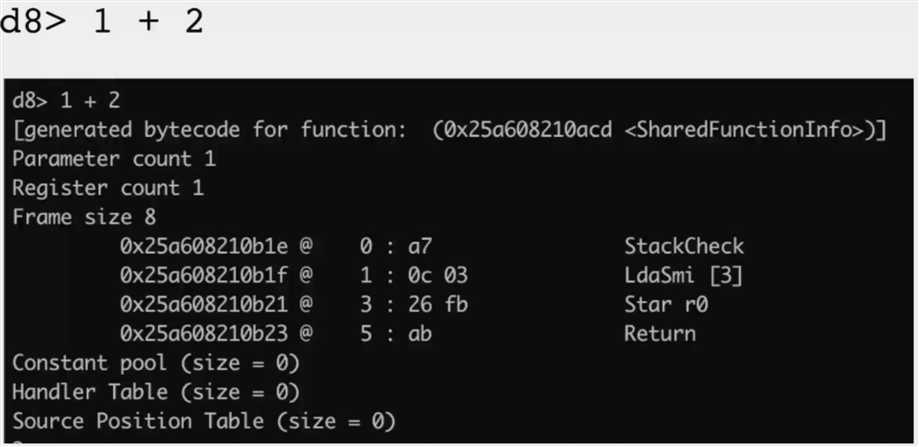
[generating bytecode for function: incrementX]
Parameter count 2
Frame size 8
12 E> 0x2ddf8802cf6e @ StackCheck
19 S> 0x2ddf8802cf6f @ LdaSmi [1]
0x2ddf8802cf71 @ Star r0
34 E> 0x2ddf8802cf73 @ LdaNamedProperty a0, [0], [4]
28 E> 0x2ddf8802cf77 @ Add r0, [6]
36 S> 0x2ddf8802cf7a @ Return
Constant pool (size = 1)
0x2ddf8802cf21: [FixedArray] in OldSpace
- map = 0x2ddfb2d02309 <Map(HOLEY_ELEMENTS)>
- length: 1
0: 0x2ddf8db91611 <String[1]: x>
Handler Table (size = 16)我们忽略大部分输出,专注于实际的字节码。
这是每个字节码的意思,每一行:
LdaSmi [1] 将常量 1 加载到累加器中。
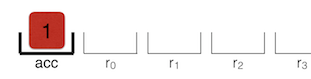
接下来,Star r0 将当前在累加器中的值 1 存储在寄存器 r0 中。
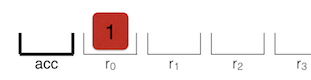
LdaNamedProperty 将 a0 的命名属性加载到累加器中。ai 指向 incrementX() 的第 i 个参数。在这个例子中,我们在 a0 上查找一个命名属性,这是 incrementX() 的第一个参数。该属性名由常量 0 确定。LdaNamedProperty 使用 0 在单独的表中查找名称:
- length: 1
0: 0x2ddf8db91611 <String[1]: x>可以看到,0 映射到了 x。因此这行字节码的意思是加载 obj.x。
那么值为 4 的操作数是干什么的呢? 它是函数 incrementX() 的反馈向量的索引。反馈向量包含用于性能优化的 runtime 信息。
现在寄存器看起来是这样的:
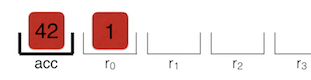
最后一条指令将 r0 加到累加器,结果是 43。 6 是反馈向量的另一个索引。
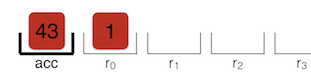
Return 返回累加器中的值。返回语句是函数 incrementX() 的结束。此时 incrementX() 的调用者可以在累加器中获得值 43,并可以进一步处理此值。
乍一看,V8 的字节码看起来非常奇怪,特别是当我们打印出所有的额外信息。但是一旦你知道 Ignition 是一个带有累加器寄存器的寄存器,你就可以分析出大多数字节码都干了什么。
Learned something? Clap your ? to say “thanks!” and help others find this article.
注意:此处描述的字节码来自 V8 版本 6.2,Chrome 62 以及 Node 9(尚未发布)版本。我们始终致力于 V8 以提高性能和减少内存消耗。在其他 V8 版本中,细节可能会有所不同。
------------------
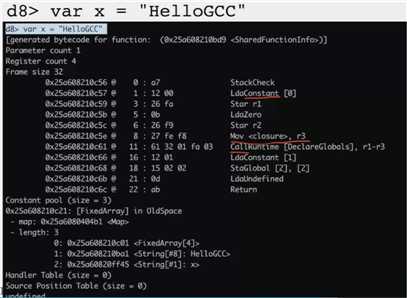
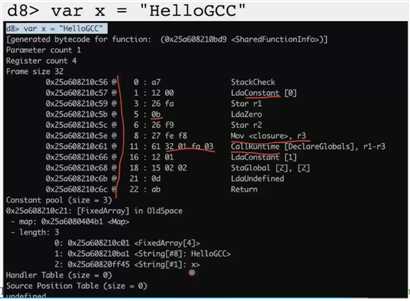
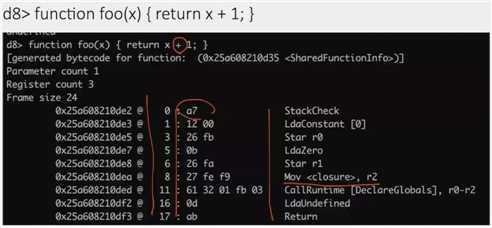
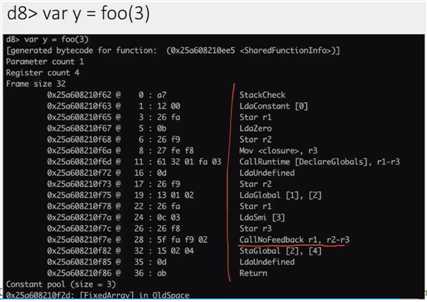
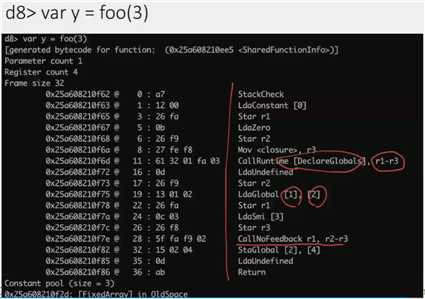

是整数加
还是字符串拼接加
是不知道的
字符串 + 数字:数字转字符串
数字 + 字符串:可能就报错了

简单的:LD ST
复杂的:callruntime、 jit 、tracing 相关的操作
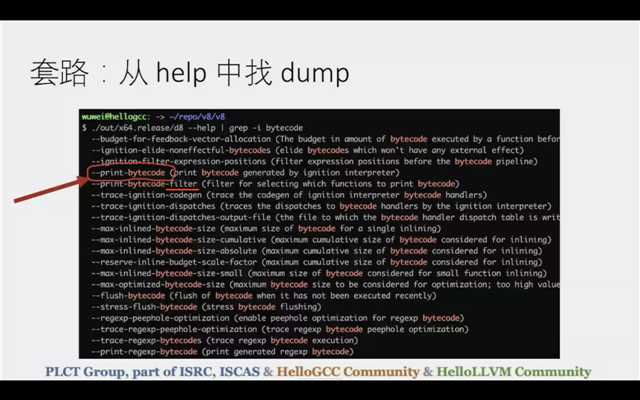
d8 -help
dump 可以 dump出/trace:bytecode、ast、cfnotes?、各种IR的结果、包括到最后二进制的结果、整个内存GC的过程
静态:dump,观察堆栈是否出错
动态:gdb
标签:包含 形式 for turn dbf UNC 很多 span cti
原文地址:https://www.cnblogs.com/cx2016/p/13197199.html