标签:系统 inter 样本 random 利用 and 分层 误差 ima
数据精简之数据记录精简方法
1.数据记录精简的需求
• 随着数据表中的数据记录愈来愈多,有两个问题会浮现出来
• 整个数据挖掘所需的时间将跟着拉长
• 所有统计的方法通通失效
2.数据记录精简对所获得的知识影响
• 求得之知识可能多少有些误差
• 然而当数据集合中存在无关、偏差的数据记录时,将数据记录作适当的精简,将能获得更准确有效的知识
3.数据记录精简常用方法
(1)统计方法中抽样(Sampling)的作法
• 数据集合中抽取部分的数据记录样本来代表整个数据集合母体
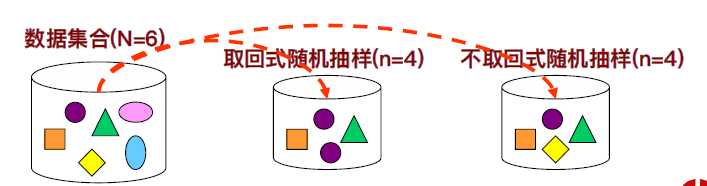
• 随机抽样(Random Sampling):有放回,无放回。
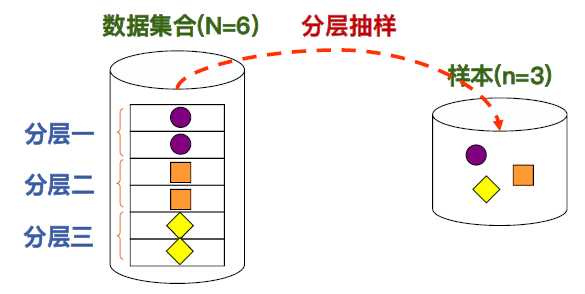
• 分层抽样(Stratified Sampling):针对数据集合中同构型高且互不重迭的分层,各自进行随机抽样。 将各分层的抽样结果结合成一个样本。
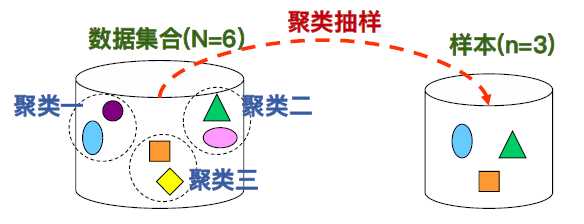
• 聚类抽样(Cluster Sampling):利用聚类技术,将整个数据集合分成数个群集,使得每个群集中的记录相似度很高,不同群集间的记录相似度很低随机由这些群集中选取数个群集形成样本。
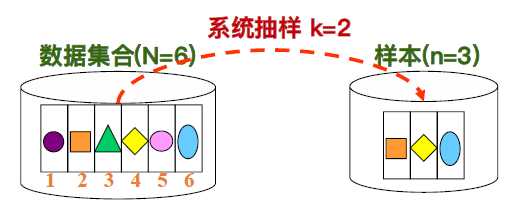
• 系统抽样(Systematic Sampling):假设数据集合中的数据记录笔数为N,而所需之样本数据记录笔数为n,则系统抽样的方式首先随机由1~N/n之间选取一个数字;假设所选取的数字为k, 以k开始,每N/n个间隔 (interval),将相对应的数据记录选取进样本之中。
• 两阶段式抽样(Two-Phase Sampling)
进行两个阶段的抽样选取以决定样本
• 第一阶段首先由数据集合中随机抽样出一个较大的样本,接着将第一阶段中所得到的样本当成数据集合,进行第二阶段的抽样
• 两阶段式抽样可以延伸成多阶段式抽样(Multi-Phase Sampling)
标签:系统 inter 样本 random 利用 and 分层 误差 ima
原文地址:https://www.cnblogs.com/liyuewdsgame/p/13200959.html