标签:来电 nbsp 其他 不同的 tree src 现象 技术 loading
查找
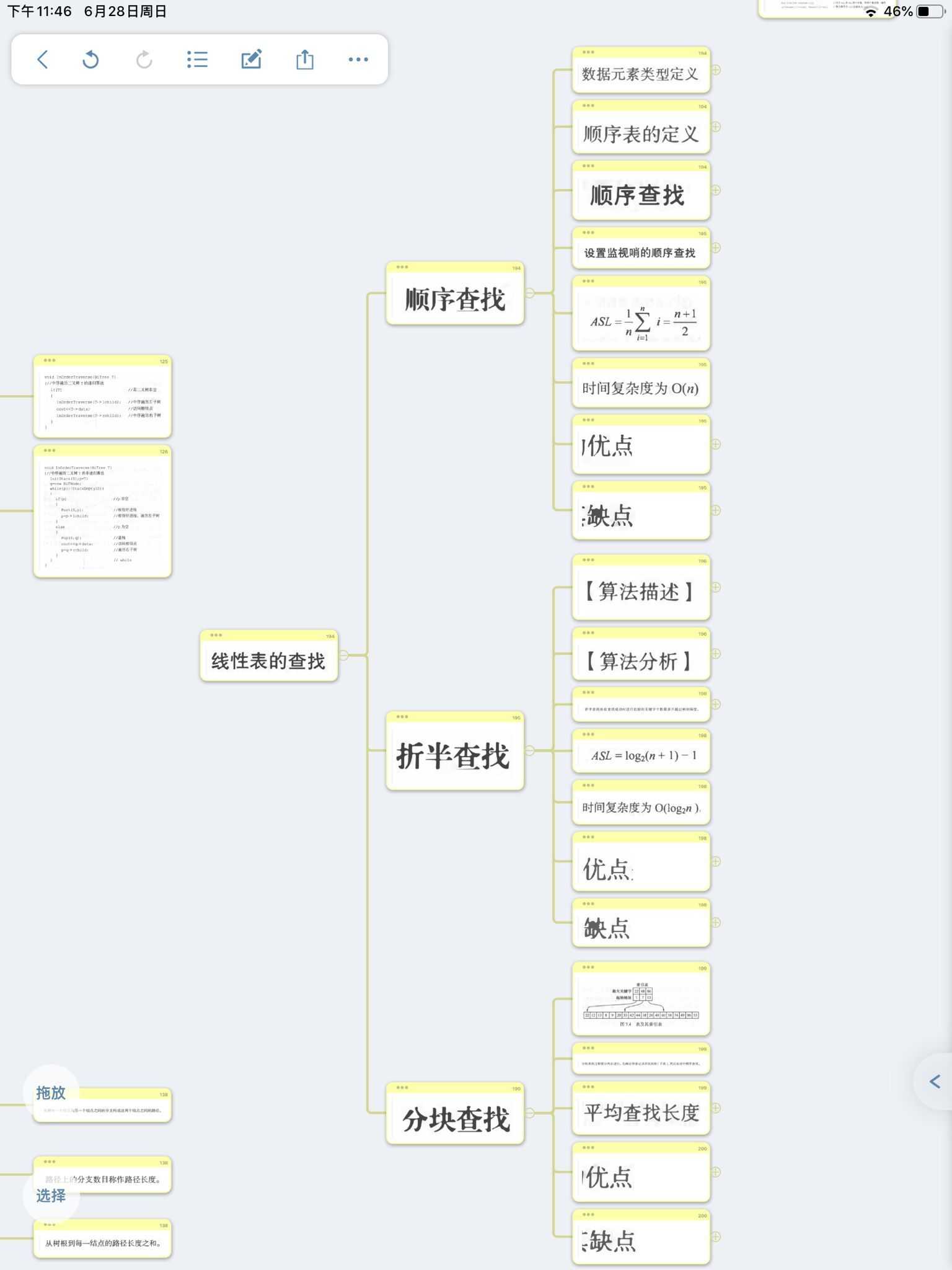
线性表
一、顺序查找
(一)数据类型定义

typedef struct { KeyType key; //关键字域 InfoType otherinfo; //其他域 }ElemType;
(二)顺序表定义
typedef struct { ElemType *R; //存储空间基地址 int length; //当前长度 }SSTable;
(三)顺序查找(普通)
int Search_Seq(SSTable ST, KeyType key) {//在顺序表ST中顺序查找其关键字等于key的数据元素。若找到,则函数值为该元素在表中的位置,否则为0 for(i = ST.length;i >= 1;--i) //从后往前找 if(ST.R[i].key == key) return i; return i; }
(四)设置监视哨的顺序查找
int Search_Seq(SSTable ST,KeyType key) {//在顺序表ST中顺序查找其关键字等于key的数据元素。若找到,则函数值为该元素在表中的位置,否则为0 ST.R[i].key = key; //设置“哨兵” for(i = ST.lengthl;ST.R[i].key != key;--i); //从后往前找 }
(五)ASL = (n + 1) / 2
(六)事件复杂度为O(n)
(七)优点:算法简单;对表结构无任何要求,既适合顺序结构,也适合链式结构
缺点:平均查找长度较大,查找效率低
二、折半查找(二分查找)
(一)方法
1. 初始化,low = 1,high = 表长
2. while(low <= high)
1)mid = (low + high) / 2
2)将key与mid对应的关键字进行比较,若查找成功,则返回mid值,
3)若不相等则利用中间位置将表对分成前、后两个子表。若key比中间位置记录的关键字小,则high = mid - 1,否则low = mid + 1
3.循环结束,说明查找区间为空,则查找失败,返回0
(二)算法
int Search_Bin(SSTable ST,KeyType key) {//在有序表ST中这般查找七关键字等于key的数据元素。若找到,则函数值为该元素在表中的位置,否则为0 low = 1; high = ST.length; //初始化 while(low <= high) { mid = (high + low) / 2; if(key == ST.R[mid].key) return mid; //找到待查元素 else if(key < ST.R[mid].key) high = mid - 1; //继续在前一子表进行查找 else low = mid + 1; //继续在后一子表进行查找 } return 0; //表中不存在待查元素 }
(三)分析——可看做二叉树
树的每一结点代表一条记录,以mid = (1 + 表长) / 2为根节点,把当前查找区间的中间位置作为跟,左子表和右子表分别作为根的左子树和右子树,由此得到的二叉树为此折半查找的判定树
(四)查找成功是进行比较的关键字个数最多不超过树的深度——log2n + 1(当有n个结点时)
(五)ASL = log2(n + 1) - 1
(六)时间复杂度为O(log2n)
(七)优点:比较次数少,查找效率高
缺点:对表结构要求高,只能用于顺序存储的有序表;为保持有序性,对表进行插入和删除时,平均比较和移动表中一般算法,费时
三、分块查找(索引顺序查找)
(一)方法
1.在索引表中确定带查找记录所在的块
2.在块中顺序查找
(二)ASL = Lb + Lw (Lb为查找索引表确定所在块的平均查找长度,Lw为在块中查找圆度的平均查找长度
ASL = (n/s + s)/2 + 1(n:表的长度为n;s:每块含有的记录)
(三)优点:由于块内是无序的,故插入和删除比较简单
缺点:需要增加一个索引表的存储空间并对索引表进行排序运算
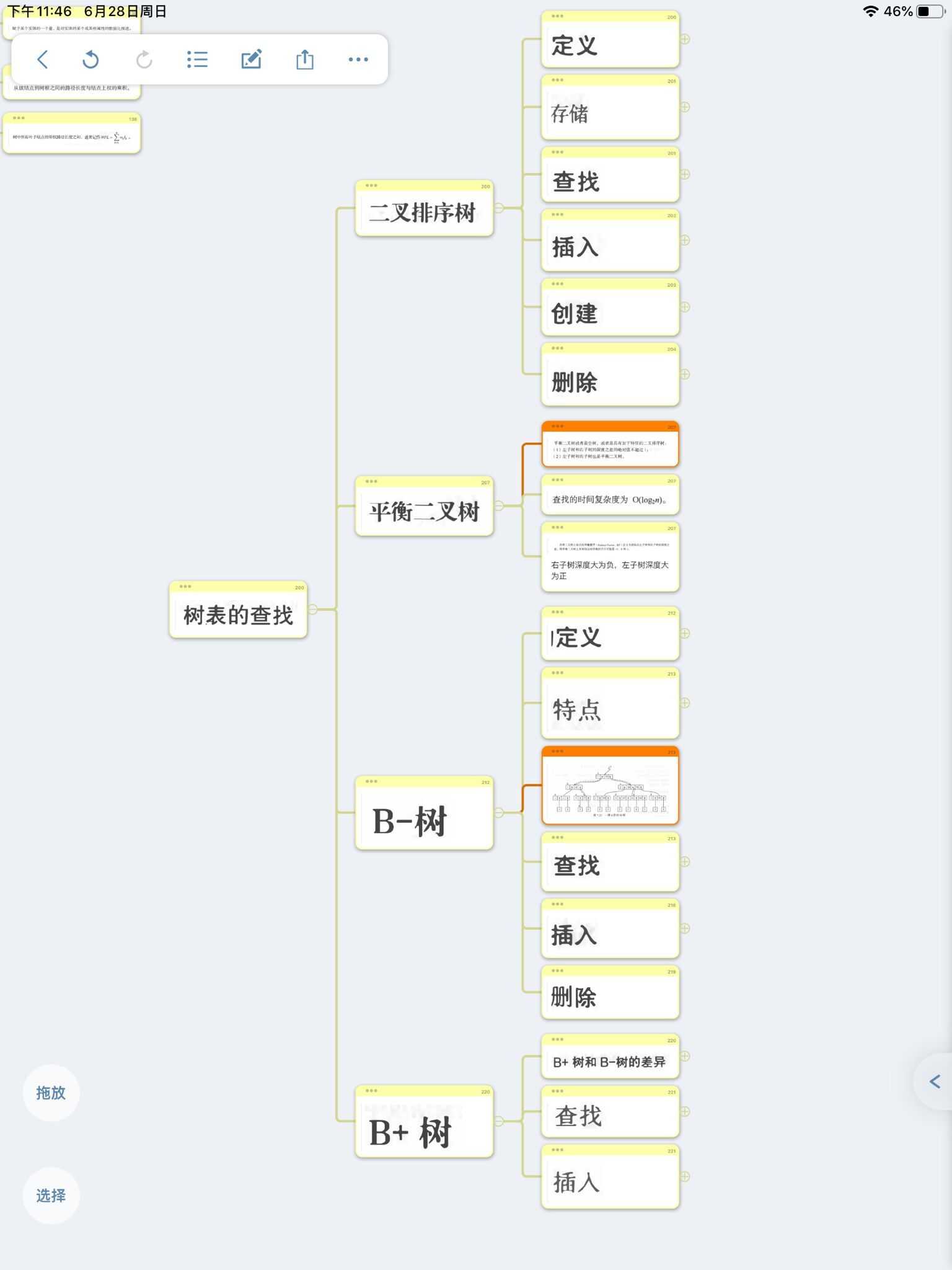
树表
一、二叉排序树(二叉查找树)
(一)定义
为空树或具备下列性质
1.左子树不空,则左子树上所有结点的值均小于它的根节点的值
2.有指数不空,则右子树上所有结点的值均小于它的根节点的值
3.它的左、右子树也分别为二叉排序树
(二)存储
typedef struct { KeyType key; //关键字项 InfoType otherinfo; //其他数据项 }ElemType; //每个结点的数据域的类型 typedef struct BSTNode { ElemType data; //每个结点的数据域包括关键字项和其他数据项 struct BSTNode *lchild,*rchild; //左右孩子指针 }BSTNode,*BSTree;
(三)查找(递归)
1. 方法
1)二叉排序树为空,查找失败,返回空指针
2)二叉排序树非空,将key与根节点的关键字T->data.key进行比较
a. key = T->data.key,查找成功,返回根节点地址
b. key < T->data.key,递归查找左子树
c. key > T->data.key,递归查找右子树
2. 算法
BSTree SearchBST(BSTree T,KeyType key) {//在根指针T所指二叉排序树种递归查找某该关键字等于key的数据元素 //查找成功,则返回指向该数据元素结点的指针,否则返回空指针 if((!T)||key == T->data.key) return T; //查找结束 else if(key < T->data.key) return SearchBST(T->lchild,key); //在左子树继续查找 else return SearchBST(T->rchild,key); //在右子树继续查找 }
3. 最差情况(单只树):ASL = (n + 1)/2(n:树的深度)
最好情况(判定树相似):ASL与log2n成正比
平均情况:ASL与log2n同数量级
(四)插入
1. 方法
1)二叉树为空,待插入结点*S作为根节点插入到空树
2)二叉树非空,将key与根节点的关键字T->data.key进行比较
a. key < T->data.key,将*S插入到左子树
b. key > T->data.key,将*S插入到右子树
2. 算法
void InsertBST(BSTree &T, ElemType e) {//当二叉排序树T种不存在关键字等于e.key的数据元素时,则插入该元素 if(!T) { //找到插入位置,递归结束 S = new BSTNode; //生成新结点*S S->data = e; //新结点*S的数据域置为e S->lchild = S->rchild = NULL; //新结点*S作为叶子结点 T = S; } else if(e.key < T->data.key) InsertBST(T->lchild,e); //将*S插入左子树 else if(e.key > T->data.key) InsertBST(T->rchild,e); //将*S插入右子树 }
3. 时间复杂度为O(log2n)
(五)创建
1.方法
1)将二叉排序树T初始化为空树
2)读入一个关键字为key的结点
3)如果读入的关键字key不是输入结束标志,则循环执行以下操作
a.将此节点插入二叉排序树T种
b.读入一个关键字为key的关键字
2. 算法
void CreatBST(BSTree &T) {//依次输入一个关键字为key的结点,将此结点插入二叉排序树中 T = NULL; //将二叉排序树T初始化为空树 cin >> e; while(e.key != ENDFLAG) //ENDFLAG为自定义常量,作为输入结束标志 { InsertBST(T,e); //将此结点插入二叉排序树T中 cin >> e; } }
3. 时间复杂度为O(nlog2n)
(六)删除
1.方法
2.算法
(我打过后来电脑重启全没了,再打一边来不及,这个好像也不重要。。。吧)
3.时间复杂度为O(log2n)
二、平衡二叉树(AVL树)
(一)定义
空树或具备以下特征的二叉排序树
1. 左子树和右子树的深度之差的绝对值不超过1
2. 左子树和右子树也是平衡二叉树
(二)平衡因子(BF):该结点左子树和右子树的深度之差,则平衡二叉树上所有结点的平衡因子之可能是-1、0、1
(三)时间复杂度为O(log2n)
三、B-树
(一)定义
m阶的B-树为空树或满足以下特性
1. 树中每个结点之多有m棵子树
2. 若根节点不是叶子结点,则至少有两棵子树
3. 除跟之外的所有非终端结点至少有[m/2]棵子树
4. 所有叶子结点都出现在统一层次上,并且不带信息,通常称为失败结点(不存在,引入是为了便于分析B-树的查找性能)
5. 所有非终端结点最多有m - 1个关键字,
(二)特征:平衡、有序、多路
(三)查找
1. 结点类型
#define m 3; //B-树的阶,暂设为3 typedef struct BTNode { int keynum; //结点中关键字的个数,即结点的大小 struct BTNode *parent; //指向双亲结点 KeyType key[m + 1]; //关键字向量,0单元未用 struct BTNode *ptr[m + 1]; //子树指针向量 Record *recptr[m + 1]; 记录指针向量,0号单元未用 }BTNode,*BTree; typedef struct { BTNode *pt; //指向找到的结点 int i; //l...m,在结点中的关键字序号 int tag; //1:查找成功,0:查找失败 }Result; //B-树的查找结果类型
2. 算法
Result SearchBTree(BTree T,KeyType key) {//在m阶B-树上查找关键字key,返回结果(pt,i,tag) //若查找成功,则特征值tag = 1,指针pt所指结点中第i和关键字等于key //否则特征值tag = 0,等于key的关键字应插入在指针pt所指结点第i和第i+1个关键字之间 p = T;q = NULL;found = FALSE;i = 0; //初始化,p指向待查结点,q指向p的双亲 while(p && !found) { i = Search(p,key); //在p->key[1...keynum]中查找i,使得:p->key[i] <= key < p->key[i+1] if(i > 0 && p->key[i] == key) found = TRUE; //找到待查关键字 else { q = p; p = p->ptr[i]; } } if(found) return(p,i,1); //查找成功 else return(q,i,0); //查找失败 }
(四)插入
(五)删除
四、B+树
(一)B-和B+树的差异
(二)查找
(三)插入
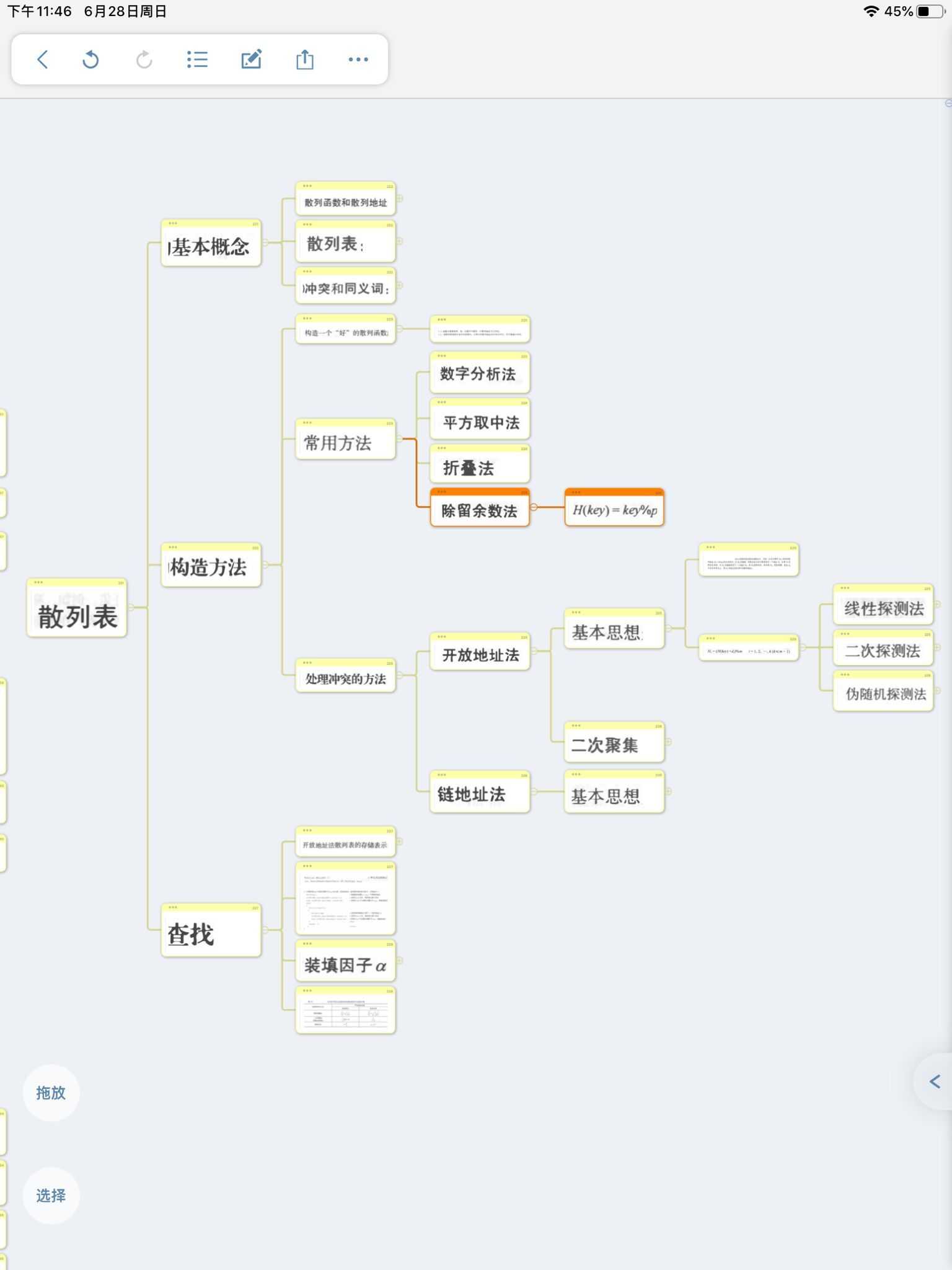
散列表
一、基本概念
(一)散列函数和散列地址:在记录的存储位置p和其关键字key之间建立一个确定的对应关系H,使p = H(key),成这个对应关系H为散列函数,p为散列地址
(二)散列表:一个有限连续的地址空间,用以存储按散列函数计算得到相应散列地址的数据记录。通常散列表的存储空间是一个一维空间,散列地址使数组的下标
(三)冲突和同义词:对不同关键字可能得到统一散列地址,即key1 != key2,而H(key1) = H(key2),这种现象称为冲突。具有相同函数值的关键字对该散列函数来说称作同义词,key1和key2互称为同义词
二、构造方法
(一)“好”散列函数的原则
1. 函数计算要简单,每一个关键字只能由一个散列地址与之对应
2. 函数的值域需在表长的范围内,计算出的散列地址的分布均匀,尽可能减少冲突
(二)常用方法
1. 数字分析法
2. 平方取中法
3. 折叠法
4. 除留余数法:H(key) = key % p
(三)处理冲突的方法
1. 开放地址法
1)基本思想:把记录都存储在散列表数组中,当某一记录关键字key的初始散列地址H0 = H(key)发生冲突时,以H0为基础,采取合适方法计算得到另一地址H1,如果H1仍然发生冲突,以H1为基础再求下一个地址H2,以此类推,直到不发生冲突为止,则Hk为该记录再表中的散列地址
2)Hi = (H(key) + di) % m i = 1,2,...,k(k <= m - 1)
3)“二次聚集”:再处理冲突过程中发生的两个第一个散列地址不同的记录争夺同一后继散列地址的现象称为“二次聚集”,即再处理同义词的冲突过程中又添加了非同义词的冲突
4)常见方法
a. 线性探测法
①di = 1,2,3,...,m - 1
②优点:只要散列表未填满,总能找到一个部发生冲突的地址
③缺点:会产生“二次聚集”
b.二次探测法
①di = 12,-12,22,-22,...,+k2,-k2(k <= m/2)
②优点:避免“二次聚集”现象
③缺点:不能保证一定找到不发生冲突的地址
c.伪随机探测法
①di = 伪随机数序列
②优点:只要散列表未填满,总能找到一个部发生冲突的地址
③缺点:会产生“二次聚集”
2. 链地址法
基本思想:把具有相同散列地址的记录放在统一单链表中,称为同义词链表。有m个散列地址,就有m个单链表,同时用数组HT[0...m-1]存放各个链表的头指针,凡是散列地址为i的记录都以结点方式插入到以HT[i]为头结点的单链表中
标签:来电 nbsp 其他 不同的 tree src 现象 技术 loading
原文地址:https://www.cnblogs.com/tyas/p/13205083.html
