标签:意思 ons 切换 htm 效率 消费者 创建 首页 col
摘要
利用Python对MM131站点的分析,从而实现了整个站点的相关图片信息提取,并保存至本地硬盘。利用Python的multiprocessing库,threading库实现了高并发操作,大大加快对该站点的爬取效率。
1.引言
1.1背景
我们正处于飞速发展的大数据时代。不同于以往,现如今丰富的数据信息让我们有能力更好地了解消费者、顾客和竞争对手。通过电商网站评论收集可以及时知悉顾客对于产品的看法,通过对手网站信息收集可以及时知晓对手的实时动态,真正做到运筹帷幄之中,决胜千里之外。
在数据量爆发式增长的互联网时代,网站与用户的沟通本质上是数据的交换:搜索引擎从数据库中提取搜索结果,将其展现在用户面前;电商将产品的描述、价格展现在网站上,以供买家选择心仪的产品;社交媒体在用户生态圈的自我交互下产生大量文本、图片和视频数据。这些数据如果得以分析利用,不仅能帮助第一方企业(也就是拥有数据的企业)做出更好的决策,对于第三方企业也是有益的。
近几年来,随着大数据分析的火热,毕竟有数据才能分析,网络爬虫则是成为了大数据分析领域的第一个环节。此次我分析的站点是一个资源网站MM131,它的ALEXA全球排名为第298406位,预估日均IP:3000,预估日均PV:2.70万,重要的是它是一个静态网站非常适合用来做爬虫抓取的实践。
1.2意义
利用python去提取整站数据并加以保存。
1.3实现的功能
Python的高并发爬虫
2.系统架构:
2.1 分析网页架构
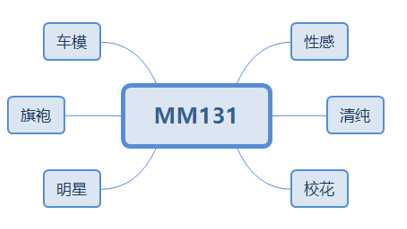
图1 MM131网页架构图
2.2 用户用例图
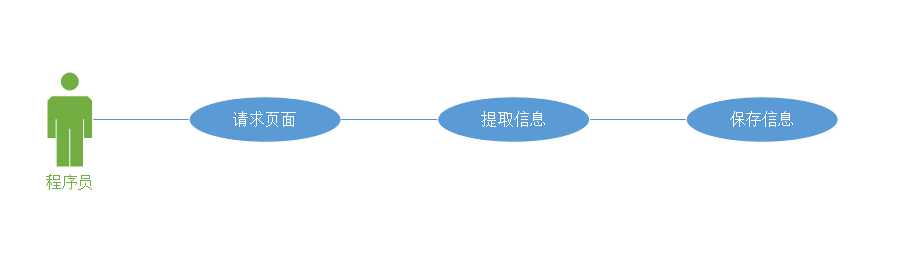
图2 用户用例图
2.3 系统架构图
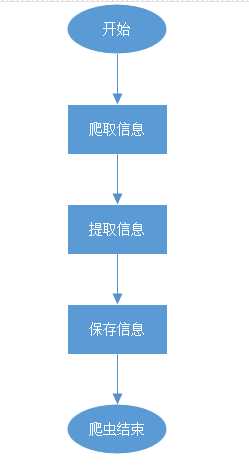
图3 系统架构图
爬虫模块:
相关技术:正则表达式,multiprocessing库(多进程),threading库(多线程),requests(请求库),自定义User_Agent池。
原理:请求网页,获得响应,然后对响应体信息进行提取并加以保存。
3. 实现代码
3.1 爬取MM131的具体过程:
1.分别对6个分类站点进行访问
2.分别提取这6个站点的首张图片所属的html信息
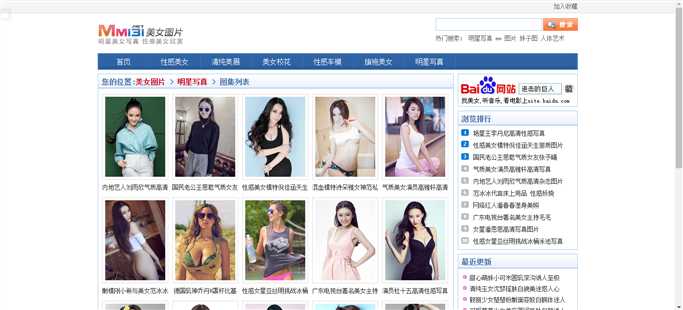
图4 站点图
得出通用html表达式:
https://www.mm131.net/分区号/图集号
存在问题:
经过观察发现,同类分区所在的图集号并不是步进为1的关系,可能当前图集是536,下一套图集却是584而不是537,因此我猜测可能是因为整个网站的网页进行了分类,537存在但和536不在同一分组,也即是分区不同。
解决方案:
我的解决方案相对简单,不去在意这个问题,只去请求,通过网页状态码来判断该页面是否存在,200则提取,其他则选择打印状态码和url。
3.建立进程池:
尽管爬虫是属于IO密集型任务,可我还是选择了尝试加入多进程的操作去尽可能的提升爬虫的效率。以下这段代码主要是建立了一个大小为6的进程池,并开启进程操作,这里的pool.join()是对进程进行阻塞,在当前进程结束后才运行主进程,而pool.apply_async则是多进程的异步非阻塞形式,意思就是:不用等待当前进程执行完毕,随时根据系统调度来进行进程切换。
1 pool = Pool(processes=6) # 建立6个进程池 2 for i in range(6): # 开启进程池 3 url = workQueue.get() 4 pool.apply_async(parse_module, args=(url, sort[i])) 5 6 print("Started processes") 7 pool.close() 8 pool.join()
4.建立多线程:
我的想法是实现利用多线程实现同时抓取大批量网页的操作,由于网站的结构简单,所以我利用range和分片操作组合拼接了每个分类的html,并将其存入Queue中。然后利用多线程对Queue中的元素进行请求与提取。
1 threads = [] 2 threadList = [] 3 for num in range(module_amount//8): 4 threadList.append("Thread-" + str(num)) 5 6 for tName in threadList: 7 thread = myThread(module_Name, module_Queue) 8 thread.start() 9 threads.append(thread) 10 11 for t in threads: 12 t.join()
5.请求与提取:
我选择requests库进行请求操作,而提取选择的是正则表达式,选择正则表达式的原因是因为它更小巧与快捷。我以下的代码主要是实现了对于页面相关信息的提取操作,我使用User-Agent池来随机构建我的请求头,得益于网页结构的简单,它的图片的url也是可推导出的,我通过获取每一张图集的首张照片url,和图集的照片数量构建出了该图集的全部照片的url,想比起逐页请求再获取照片url的操作,我的方法更加高效和便捷。
1 def parse_page(module_Name, q): 2 """ 3 根据url提取图集的编号 4 提取出图集的照片数量 5 提取出图集的标题 6 提取首页图片的url 7 """ 8 url = q.get() 9 try: 10 r = requests.get(url, headers=headers, verify=False, timeout=5) 11 if r.status_code == 200: 12 atlas_number = re.search(‘(\d*).html‘, url) # 提取编号 13 atlas_number = str(atlas_number.group(1)) 14 r.encoding = r.apparent_encoding # 转码 15 atlas_amount = re.search(‘page-ch.*?([0-9]{1,2})‘, r.text) # 提取该页所属图集的照片数量 16 atlas_amount = int(atlas_amount.group(1)) 17 atlas_title = re.search(‘<h5>(.*?)</h5>‘, r.text) # 提取出单页的照片标题 18 atlas_title = str(atlas_title.group(1)) 19 img_url = re.search(‘\)" src="(.*?)"‘, r.text) # 提取首页的图片url 20 img_url = str(img_url.group(1)) 21 atlas_url = [] # 构建一个照片的url队列 22 module_info = {} 23 module_info[‘atlas_number‘] = atlas_number 24 module_info[‘atlas_title‘] = atlas_title 25 module_info[‘module_Name‘] = module_Name 26 27 for num in range(1, atlas_amount+1): # 拼接照片的url并放入队列中 28 base_url = img_url[:-5] + str(num) + ‘.jpg‘ # 照片地址 29 atlas_url.append(base_url) 30 31 for p in atlas_url: 32 download_img(p, module_info) 33 34 # print(os.getpid(), threadName, r.status_code, atlas_title, url, atlas_amount) # os.getpid获取进程号 35 else: 36 print(r.status_code, url) 37 except Exception as e: 38 print(os.getpid(), url, ‘Error: ‘, e)
6.保存:
保存操作需要注意的就是存放路径和文件操作,为了方便对文件的管理,我在文件ming 上加入了图集对应的html的编号。
1 def download_img(img_url, info): 2 resp = requests.get(img_url, headers=headers, verify=False, timeout=5) # 请求照片获得的响应 3 title = info[‘module_Name‘] + ‘/‘ + info[‘atlas_number‘] + ‘-‘ + info[‘atlas_title‘] # 照片的标题 4 title = title.replace(":", " ") 5 i = re.search(‘(\d*).jpg‘, img_url) 6 i = i.group(1) 7 file_path = ‘D:/MM131/‘ + title + ‘/‘ # 存放图片的路径 8 if not os.path.exists(file_path): 9 os.makedirs(file_path) 10 try: 11 with open(file_path + ‘/‘ + str(i) + ‘.jpg‘, ‘wb‘)as jpg: 12 jpg.write(resp.content) 13 print("冲冲冲" + str(i)) 14 except BaseException: 15 print("出错了,hxd!")
爬虫完整代码:
1 from multiprocessing import Pool, Manager # 多进程 2 import queue # 队列 3 import os 4 import re # 正则 5 import time # 计时 6 import requests 7 import User_Agent # 自定义的User_Agent池 8 import threading # 多线程 9 import urllib3 10 import CheckRight 11 12 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) 13 """ 14 进程池的测试 15 """ 16 17 headers = (User_Agent.get_user_agent()) # 构建请求头 18 headers.update({‘Connection‘: ‘close‘, 19 ‘Referer‘: ‘https://www.mm131.net‘}) 20 21 22 class myThread(threading.Thread): 23 """ 24 线程类,用于创建线程 25 """ 26 def __init__(self, name, q): 27 threading.Thread.__init__(self) 28 self.name = name 29 self.q = q 30 31 def run(self): 32 try: 33 parse_page(module_Name=self.name, q=self.q) 34 except Exception as e: 35 print(self.name, url) 36 37 38 def parse_page(module_Name, q): 39 """ 40 根据url提取图集的编号 41 提取出图集的照片数量 42 提取出图集的标题 43 提取首页图片的url 44 """ 45 url = q.get() 46 try: 47 r = requests.get(url, headers=headers, verify=False, timeout=5) 48 if r.status_code == 200: 49 atlas_number = re.search(‘(\d*).html‘, url) # 提取编号 50 atlas_number = str(atlas_number.group(1)) 51 r.encoding = r.apparent_encoding # 转码 52 atlas_amount = re.search(‘page-ch.*?([0-9]{1,2})‘, r.text) # 提取该页所属图集的照片数量 53 atlas_amount = int(atlas_amount.group(1)) 54 atlas_title = re.search(‘<h5>(.*?)</h5>‘, r.text) # 提取出单页的照片标题 55 atlas_title = str(atlas_title.group(1)) 56 img_url = re.search(‘\)" src="(.*?)"‘, r.text) # 提取首页的图片url 57 img_url = str(img_url.group(1)) 58 atlas_url = [] # 构建一个照片的url队列 59 module_info = {} 60 module_info[‘atlas_number‘] = atlas_number 61 module_info[‘atlas_title‘] = atlas_title 62 module_info[‘module_Name‘] = module_Name 63 64 for num in range(1, atlas_amount+1): # 拼接照片的url并放入队列中 65 base_url = img_url[:-5] + str(num) + ‘.jpg‘ # 照片地址 66 atlas_url.append(base_url) 67 68 for p in atlas_url: 69 download_img(p, module_info) 70 71 # print(os.getpid(), threadName, r.status_code, atlas_title, url, atlas_amount) # os.getpid获取进程号 72 else: 73 print(r.status_code, url) 74 except Exception as e: 75 print(os.getpid(), url, ‘Error: ‘, e) 76 77 78 def download_img(img_url, info): 79 resp = requests.get(img_url, headers=headers, verify=False, timeout=5) # 请求照片获得的响应 80 title = info[‘module_Name‘] + ‘/‘ + info[‘atlas_number‘] + ‘-‘ + info[‘atlas_title‘] # 照片的标题 81 title = title.replace(":", " ") 82 i = re.search(‘(\d*).jpg‘, img_url) 83 i = i.group(1) 84 file_path = ‘D:/MM131/‘ + title + ‘/‘ # 存放图片的路径 85 if not os.path.exists(file_path): 86 os.makedirs(file_path) 87 try: 88 with open(file_path + ‘/‘ + str(i) + ‘.jpg‘, ‘wb‘)as jpg: 89 jpg.write(resp.content) 90 print("冲冲冲" + str(i)) 91 except BaseException: 92 print("出错了,hxd!") 93 94 95 def parse_module(module_url, module_Name): 96 r = requests.get(module_url, headers=headers, verify=False, timeout=5) 97 r.encoding = r.apparent_encoding 98 module_amount = int(re.search(‘<dd.*?/(\d{4})‘, r.text).group(1)) # 提取该模块的最大图集数量 99 module_Queue = queue.Queue() 100 for x in range(1, (module_amount+1)): # 拼接出所有图集的url并放入队列 101 page_url = module_url + str(x) + ‘.html‘ 102 if CheckRight.check(page_url): 103 module_Queue.put(page_url) 104 else: 105 print("跳过") 106 107 threads = [] 108 threadList = [] 109 for num in range(module_amount//8): 110 threadList.append("Thread-" + str(num)) 111 112 for tName in threadList: 113 thread = myThread(module_Name, module_Queue) 114 thread.start() 115 threads.append(thread) 116 117 for t in threads: 118 t.join() 119 120 121 if __name__ == ‘__main__‘: 122 start = time.time() 123 manger = Manager() 124 workQueue = manger.Queue(6) 125 sort = (‘xinggan‘, ‘qingchun‘, ‘xiaohua‘, ‘chemo‘, ‘qipao‘, ‘mingxing‘) 126 127 for url in sort: # 获取分类页的url 128 url = ‘https://www.mm131.net/‘ + url + ‘/‘ 129 workQueue.put(url) 130 131 pool = Pool(processes=6) # 建立6个进程池 132 for i in range(6): 133 url = workQueue.get() 134 pool.apply_async(parse_module, args=(url, sort[i])) 135 136 print("Started processes") 137 pool.close() 138 pool.join() 139 140 end = time.time() 141 print(‘Pool + Queue + threading 多进程多线程爬虫的总时间为: ‘, end - start) 142 print(‘Main Process Ended!‘)
4.实验结果:
爬虫结果:
图5 各分区文件夹
图6 分区内各分组文件夹
图7 图集内图片
性能结果:
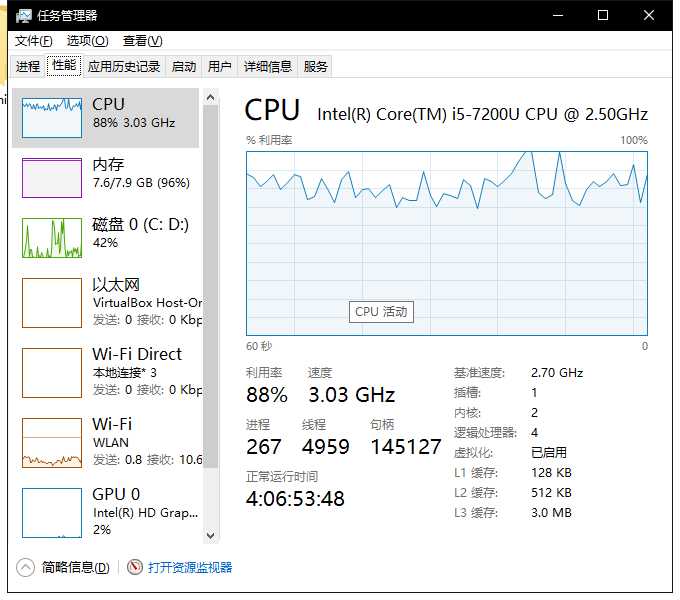
图8 CPU利用率
图9 内存情况
图10 磁盘
5. 总结和展望:
本来以为只是一个简单的尝试,但是刚开始上手还是问题多多,这次尝试让我对爬虫的理解应用有了更多的体会,而且基本上完成了功能的实现。回顾一开始,我连防盗链的知识都还不了解,以致于看见整个文件夹里都是推广图片时,整个人的内心是崩溃的。再到后来的高并发爬取的学习,我对于python的多进程多线程多协程有了更深刻的认识理解和应用。不足之处有许多点:未使用多协程,尽管我很想使用多协程,但实际测试时由于对多协程掌握程度的不足,导致加入多协程功能后程序会处于长时间无响应状态,只好作罢。 未使用ip代理池,因为单ip对服务器的连接是有限制的,如果使用ip代理池可以真正意义上的实现高并发处理,而不至于对遇到ReadtimeOut的无能为力,截至到写这篇文章,我始终无法解决高并发所带来的读取超时,尽管加入了延时操作,但是最终结果还是差强人意,只能说是可用。对于异常处理能力的不足,项目的实施过程中遇到过很多次异常处理,大多数情况都是百度或者谷歌,但是没有建立自己去寻找异常,思考异常,自我解决异常的能力,需要补足。
参考文献:
[1]唐松,陈智铨.Python网络爬虫从入门到实践[M].北京:机械工业出版社,2017
[2]谢乾坤.Python爬虫开发:从入门到实践(微课版)[M].上海:人民邮电出版社,2018
标签:意思 ons 切换 htm 效率 消费者 创建 首页 col
原文地址:https://www.cnblogs.com/lcs-1503647333/p/13205888.html