标签:软件 nbsp style pen 接下来 规则 一个 基础上 空间
CVPR2020:端到端学习三维点云的局部多视图描述符
End-to-End Learning Local Multi-View Descriptors for 3D Point Clouds
论文地址:
摘要
在这项工作中,我们提出了一个端到端的框架来学习三维点云的局部多视图描述符。为了采用类似的多视图表示,现有的研究在预处理阶段使用手工构建的视点进行渲染,而预处理阶段是从随后的描述符学习阶段分离出来的。在我们的框架中,我们通过使用可微渲染器将多视图渲染集成到神经网络中,使得视点成为可优化的参数,以获取更多信息的兴趣点的局部上下文。为了获得有区别的描述符,我们还设计了一个软视图池模块来集中融合视图间的卷积特征。在已有的三维配准基准上进行的大量实验表明,该方法在数量和质量上都优于现有的局部描述子。
1.介绍
三维几何的局部描述子被广泛认为是许多计算机视觉和图形任务(如建立对应关系、配准、分割、检索等)的基石之一,特别是随着消费者级RGB-D传感器的普及,大量的扫描数据需要健壮的局部描述符来进行场景对齐和重建[59,4]。然而,这样的三维数据往往是噪声和不完整的,这给局部描述符的设计带来了挑战。在过去的几十年中,已有的手工设计的局部描述符[20,11,46,45,53,52,48]大多是建立在低层次三维几何特性的直方图上的。深神经网络的最新趋势促使研究人员以数据驱动的方式开发基于学习的局部描述符[66、8、24、19、6、57、12]。研究了三维局部几何的几种输入表示法,如原始点云块[24,6]、体素网格[66,12]和多视图图像[19,67]。目前,在3DMatch[66]的几何配准基准上,大多数基于学习的方法都是建立在点云贴片的PointNet[4]或体素网格的3dcnns上,3dsmouthnet[12]通过平滑的密度值体素化实现了最新的性能。尽管体素表示取得了令人印象深刻的进展,但有关三维形状识别和检索的文献[50,42,56]表明多视图图像的性能优于体素网格,并且已经进行了一些初步的尝试[19,67]将类似的思想扩展到三维局部描述符。同时,最近的一系列研究已经在从单个图像块学习局部描述符方面提高了2D CNNs的水平[15,51,34,63,23,35,32]。这促使我们对三维点及其局部几何的多视图表示进行进一步的研究。
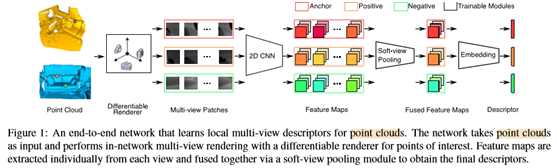
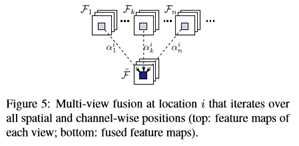
采用多视图表示学习描述符的主要挑战如下。首先,为了获得多视图图像,在预处理阶段3D图形渲染管道需要一组视点(虚拟摄像机)[50,19]。在现有的研究中[50,42,19,56,9,17],这些观点要么是随机抽样,要么是启发式的手工挑选。然而,如何以数据驱动的方式确定视点,从而为神经网络生成更多的信息渲染仍然是一个问题。其次,需要一个有效的融合操作来将多个视图的特征集成到一个紧凑的描述符中。最大视图池是一种占主导地位的融合方法[50,42,19,56],但此操作可能会忽略一些细微的细节[67,56],从而导致次优性能。 在这项工作中,我们提出了一种新的网络架构,该架构以端到端的方式学习3D点云的本地多视图描述符,如图1所示。我们的网络主要包括三个阶段:(1)点云感兴趣点的多视图绘制;(2)每个渲染视图中的特征提取;(3)视图间的特征融合。具体来说,我们首先使用网络内可微渲染器[30]将特定点的三维局部几何体投影为多视图面片。渲染器使用的视点是训练期间可优化的参数。渲染器可以将监视信号从渲染像素反向传播到视点,从而实现渲染阶段与其他两个阶段的联合优化。接下来,为了在每个呈现视图中提取特征,我们利用在学习单个补丁描述符的任务中已经成熟的现有cnn[51,34]。最后,为了融合所有视图的特征,我们研究了max-view-pooling[50]的梯度流问题,并设计了一个新的软视图池模块。前者只考虑特征图中每个位置在视图间的最强响应,而我们的设计则通过子网络估计注意权重自适应地聚合所有响应。在后向通道中,我们的设计允许监控信号更好地流入每个输入视图进行优化。在3DMatch基准上进行的实验表明,我们的方法优于现有的手工制作和学习的描述符,并且对旋转和点密度也具有鲁棒性。本文的主要工作概括如下:(1)提出了一种新的端到端的三维点云局部多视图描述学习框架,具有良好的性能;(2)在网络可微绘制中,视点是可优化的;(3) 一个软视图池模块融合了跨视图的功能和更好的渐变效果。我们将公开我们的代码。
2.相关工作
手工制作的3D本地描述符。在过去的几十年里,大量文献研究了用于编码三维点的局部邻域几何信息的描述符。全面的回顾超出了本文的范围。经典的描述符包括旋转图像[20]、三维形状上下文[11]、PFH[46]、FPFH[45]、SHOT[53]和唯一形状上下文[52]。这些手工制作的描述符大多是由低级几何性质的直方图构成的。尽管这些描述符取得了进展,但它们可能无法很好地处理实际扫描数据中常见的干扰,如噪声、不完整性和低分辨率[13]。学习了三维局部描述。随着深部神经网络(deep neural networks,简称deep neural networks,简称deep neural networks,简称deep neural networks,简称deep neural networks,简称deep neural networks,简称deep neural networks,简称deep neural networks,简称deep。一般来说,这些方法根据输入表示分为三类,包括点云贴片、体素网格和多视图图像。点云面片是点的局部邻域的最直接表示。PointNet,一个由Qi等人完成的开创性工作。[41]专门设计用于处理点云的非结构化性质。像[6,5,61]这样的研究建立在点网的基础上,学习点云补丁的描述符。还有一些基于点网的工作可以与其他任务(如关键点检测[62]和姿势预测[7])联合学习局部描述符。体素网格,在3DMatch[66]和3dsmouthNet[12]等作品中使用,是三维点云的常见结构化表示[33、58、42]。为了减少噪声和边界效应,Gojcic等人 [12] 提出在3dsmouthnet中使用平滑密度值体素化。
他们的方法在3DMatch基准上实现了最先进的性能[66],大大优于前面提到的基于点网的方法[6,5,7]。由于多视图图像能够提供丰富的三维几何信息,因此在三维形状识别和检索任务中表现出比体素网格更好的性能[50,42,43]。基于全局形状分析的成功,研究人员将多视图表示扩展到了三维局部描述学习[19,67]。Huang等人[19] 根据[50,26]重新设计CNN架构,从多视图图像中提取3D形状(如飞机或椅子)的局部描述,这些图像是用聚集的视点渲染的。已有的研究,如[843]使用二维滤波从点云生成网络图像。相比之下,我们的工作将视点视为可优化参数,并在神经网络中使用可微渲染器[30]执行多视图渲染。为了将视图特征融合到一个紧凑的表示中,最大视图池由于其计算效率和视图顺序不变性而被广泛使用[50、42、56、19、43、67],但它往往忽略了在[56、67、34、65、37]中讨论的细微细节。Zhou等人[67]提出了一种用于特征融合的残差学习模块Fuseption,但其模块不是视图顺序不变的,其参数个数随着输入视图个数的增加而增加。还探索了其他方法,例如使用NetVLAD[2]和RNN[16]进行特征聚合,但需要过多的计算或视图排序。不同的是,通过分析最大视图池的梯度流,我们提出了一种软视图池,它以视图顺序不变的方式自适应地聚集具有注意权重的特征。可微呈现。传统的三维图形绘制流水线涉及光栅化和可见性测试,这是相对于投影点坐标和视相关深度的不可微的离散化操作[30]。因此,监控信号不能从二维图像空间流向三维形状空间,从而阻止了将此管道集成到用于端到端学习的神经网络中。最近,研究人员设计了几个可微绘制框架[31,21,29,28,39,64,3,30],其中包含了用于离散化操作的近似梯度公式。其中,软光栅(SoftRas)是由刘等人开发的一种最先进的可微渲染器。[30]将网格绘制视为三角形概率聚集的过程。在这项工作中,我们修改了SoftRas,将其应用扩展到点云绘制,并采用了一种硬前向软后向的方案。
3.方法论
在给定三维点云P的情况下,我们旨在训练一个神经网络f,该网络f能够以端到端的方式提取点P∈P的判别性局部描述符。为此,我们使用多视图表示对p的局部几何进行投影分析。与点云补丁或体素网格相比,多视图表示可以更容易地捕获不同级别的局部上下文[19,42]。我们的网络f由三个阶段组成,如图1所示。首先,网络f直接以点云P和感兴趣点P为输入,采用SoftRas[30]将P的局部邻域作为多视点面片进行渲染。其次,我们通过一个轻量级的2D CNN从每个渲染视图补丁中提取卷积特征映射。最后,通过一个新的软视图池模块将提取的所有视图特征紧密地融合在一起,得到局部描述。f的三个阶段以端到端的方式联合训练,使得几何上和语义上相似的对应点的描述符彼此接近,而非对应点的描述符彼此距离较远。
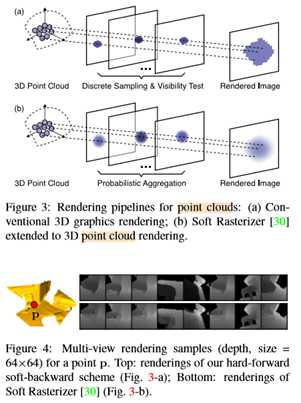
虽然等式1的可微性使得在网络渲染中成为可能,但我们在渲染输出中观察到伪影,例如在具有大深度不连续的区域处的模糊像素(参见图4)。为了减少伪影对后续特征提取的影响,我们采用了一种硬前向软后向的软后向方案来绘制点云,与[21]有着相似的想法。具体来说,在前向通道中,我们执行光栅化和可见性测试,以获得与传统渲染管道相同的渲染结果(图3-a)。在后向过程中,我们使用软件的公式1计算渲染的近似梯度。我们发现这个近似方案在我们的实验中效果很好。
等式1中的这种线性公式近似于传统渲染管道(图3)中的光栅化和可见性测试,并且它是自然可微的。由于输入点云可能缺少颜色信息,因此我们使用与视图相关的深度作为Cj[8,60],该深度对照明变化不变。有关Dj和w(·)的详细实现和讨论,请参阅[30]。
可微渲染
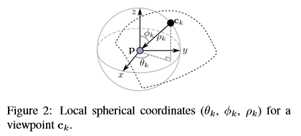
为了解决传统三维图形绘制管道(图3-a)的不可区分问题,SoftRas将网格绘制视为二维中三角形概率聚集的过程。要将点云P渲染为具有{ck}的视图面片,一种方法是通过曲面重建将P精确地转换为网格[22],然而,很难集成到我们的端到端框架中,并且可能无法很好地处理噪声(例如,在室外场景的激光扫描中)。取而代之的是,我们修改了SoftRas,使其能够进行点云渲染(图3-b)。

5. 实验测试
数据集
我们对3DMatch[66]中广泛采用的几何配准基准进行了评估。基准测试包括62个室内场景的RGB-D扫描,一组现有的RGBD数据集[55、49、59、27、14]。数据分为54个场景进行训练和验证,8个场景进行测试。在每个场景中,通过融合50个连续深度帧获得点云碎片。对于测试集中的每个片段,提供一组5000个随机采样点作为描述符提取的关键点。
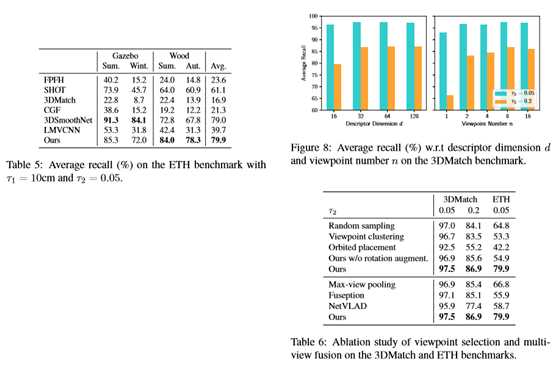
描述符维度和视点编号
在图8中,我们用不同的描述维度d和视点数n绘制了我们的方法的平均召回率。发现增加的描述维度(d≥32)和视点数(n≥8)导致饱和性能。因此,我们在实验中采用d=32和n=8作为我们的方法。
观点
在表6(顶部)中,我们展示了在多视图渲染中使用不同视点选择规则训练的网络f的性能。具体地说,直接随机抽样规则将视点随机地放置在等式5的范围内。
多视图融合
我们进行了实验,将我们的软视图池与几种可选的多视图融合方法进行比较,包括max-view-pooling[19]、Fuseption[67]和NetVLAD[2]。我们在表6(底部)中列出了使用上述融合方法训练的网络f的性能。虽然在3DMatch数据集上,与max视图池相比,软视图池的改进很小,但是我们的方法在ETH室外数据集上表现出了显著的更好的泛化效果。
平均召回结果如表5所示。我们的方法(79.9%)达到了与3dsmouthNet(79.0%)相当的性能。同时,我们的方法显著优于LMVCNN(39.7%)和SHOT(61.1%),其他描述符(包括CGF、3DMatch和FPFH)都低于25%。
运行时间
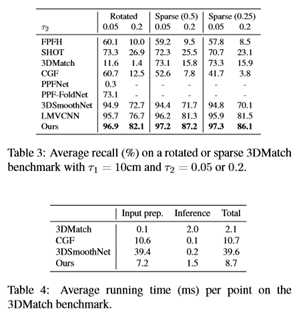
表4总结了在标准3DMatch基准上学习的描述符的运行时间。所有的实验都是在一台PC机上进行的,该PC机具有Intel Core i7@3.6GHz、32GB RAM和NVIDIA GTX 1080Ti GPU。表4中的输入准备是使用TDF[66]进行3DMatch的体素化,使用球形直方图计算[24]进行CGF的体素化,使用LRF计算和SDV体素化[12]进行3DSmoothNet的体素化,使用我们的方法进行多视图渲染。表4中的推断是用神经网络从准备好的输入中提取描述符。结果表明,输入准备阶段控制了算法的运行时间。此外,对于基于球体的渲染,使用FLANN[36]通过邻域查询来确定点半径需要0.16ms(在我们的实现中使用),而使用固定半径可以避免计算,如[19]。尽管如此,我们的方法仍然显示出具有竞争力的运行时性能。
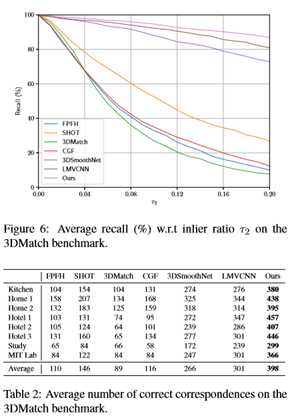
在图6中,我们绘制了与τ2范围相关的平均召回,说明了在不同内生比率条件下,我们的方法相对于比较描述符带来的改进的一致性。此外,表2列出了每个描述符找到的正确对应的平均数量。
旋转3DMatch基准
为了评估描述符对旋转的鲁棒性,我们通过旋转具有随机采样轴和角度的测试片段在[0,2π]中构造了旋转的3DMatch基准[5,12]。每个片段的关键点索引保持不变。表3给出了旋转列中每个描述符的平均回调。
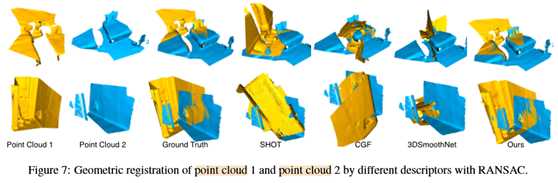
此外,图7用RANSAC可视化由不同描述符获得的一些点云配准结果。特别是,我们的描述符在具有大面积区域(第二行)的片段的配准中是稳健的。
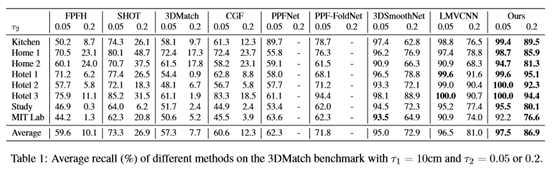
表1显示了基准测试的比较结果。对于τ2=0.05,我们的方法达到了97.5%的平均召回率,优于所有竞争描述符。然而,τ2=0.05是3DMatch的一个相对宽松的阈值,因为3dmoothnet(95.0%)、LMVCNN(96.5%)和我们的方法都达到了几乎饱和的性能,且差别较小。尽管如此,我们的方法在大多数测试场景中获得了比3DSmoothNet和LMVCNN更高的召回率。更值得注意的是,对于更严格的条件τ2=0.2,我们的方法比其他竞争对手有显著改进。具体来说,我们的方法保持了86.9%的高平均召回率,而3DSmoothNet和LMVCNN分别下降到72.9%和81.0%。FPFH、SHOT、3DMatch和CGF的性能均低于30%。
标签:软件 nbsp style pen 接下来 规则 一个 基础上 空间
原文地址:https://www.cnblogs.com/wujianming-110117/p/13206822.html