标签:cto 包围盒 tin 神经网络 dash 特性 range width pre
Single Shot Multibox Detection (SSD)实战(上)
介绍了边界框、锚框、多尺度对象检测和数据集。现在,我们将利用这些背景知识构建一个目标检测模型:单次多盒检测(SSD)。这种快速简便的模式已经被广泛应用。该模型的一些设计思想和实现细节也适用于其他对象检测模型。
1. Model
图1显示了一个SSD模型的设计。该模型的主要组成部分是一个基本网络块和若干个串联的多尺度特征块。在这里,基网络块用于提取原始图像的特征,一般采用深度卷积神经网络的形式。关于SSDs的论文选择在分类层之前放置一个截断的VGG,但现在这通常被ResNet取代。我们可以设计基础网络,使其输出更大的高度和宽度。这样,基于这个特征图生成更多的锚框,允许我们检测更小的对象。接下来,每个多尺度要素块都会减少上一层提供的要素映射的高度和宽度(例如,它可以将尺寸缩小一半)。然后使用特征映射中的每个元素来扩展输入图像上的感受野。这样,多尺度特征块越接近图1顶部,其输出特征图越小,基于特征图生成的锚框越少。此外,特征块越接近顶部,特征图中每个元素的感受野越大,越适合检测较大的物体。由于SSD根据基本网络块和每个多尺度特征块生成不同数量的不同大小的锚盒,然后预测锚盒的类别和偏移量(即预测的边界框),以检测不同大小的对象,因此SSD是一种多尺度目标检测模型。
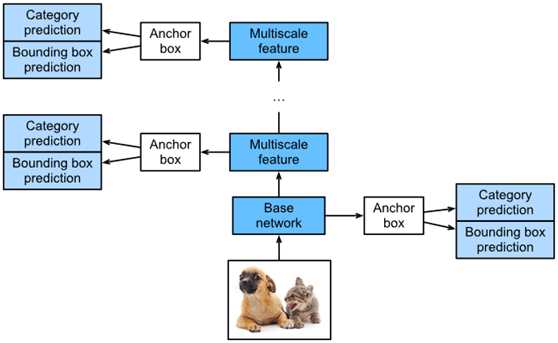
Fig. 1 The SSD is composed of a base network block and several multiscale feature blocks connected in a series.
接下来,我们将描述图1中模块的实现。首先,我们需要讨论类别预测和包围盒预测的实现。
1.1. Category Prediction Layer
将对象类别的数目设置为问问. 在这种情况下,锚盒类别的数量是q+1,0表示只包含背景的定位框。对于特定比例,将要素映射的高度和宽度分别设置为h和w。如果我们以每个元素为中心来生成锚箱,我们需要对hwa锚箱。如果我们使用全连接层(FCN)作为输出,这可能会导致模型参数过多。如何使用卷积层通道输出类别预测。SSD采用相同的方法来降低模型复杂度。具体地说,类别预测层使用保持输入高度和宽度的卷积层。因此,输出和输入与特征映射的宽度和高度的空间坐标一一对应。假设输出和输入具有相同的空间坐标(x,y),坐标的通道(x,y)在输出特征图上,包含使用输入特性图坐标生成的所有定位框的类别预测(x,y)作为中心。因此,有a(q+1)输出通道,输出通道索引为i(q+1)+ji(q+1)+j(0≤j≤q0≤j≤q)表示类别索引的预测j对于锚箱索引。我们将定义这种类型的类别预测层。在我们指定参数a和q之后,它使用3×3卷积层,填充为1。这个卷积层的输入和输出的高度和宽度保持不变。
%matplotlib inline
from d2l import mxnet as d2l
from mxnet import autograd, gluon, image, init, np, npx
from mxnet.gluon import nn
npx.set_np()
def cls_predictor(num_anchors, num_classes):
return nn.Conv2D(num_anchors * (num_classes + 1), kernel_size=3,
padding=1)
1.2. Bounding Box Prediction Layer
包围盒预测层的设计与类别预测层的设计相似。唯一的区别是,在这里,我们需要为每个锚框预测4个偏移量,而不是q+1类别。
def bbox_predictor(num_anchors):
return nn.Conv2D(num_anchors * 4, kernel_size=3, padding=1)
1.3. Concatenating Predictions for Multiple Scales
如前所述,SSD使用基于多尺度的特征映射来生成锚盒并预测其类别和偏移量。由于不同尺度的特征映射,同一元素中心锚盒的形状和数量不同,不同尺度下的预测输出可能具有不同的形状。
在下面的例子中,我们使用同一批数据构建两个不同比例的特征映射,Y1和Y2。在这里,Y2的高度和宽度是Y1的一半。以类别预测为例,我们假设Y1和Y2特征映射中的每个元素生成五个(Y1)或三个(Y2)锚定框。当有10个对象类别时,类别预测输出通道的数量为 5×(10+1)=55或3×(10+1)=33。预测输出的格式是(批次大小、通道数、高度、宽度)。如您所见,除了批量大小,其他维度的大小是不同的。因此,我们必须将它们转换成一致的格式,并将多个尺度的预测串联起来,以便于后续的计算。
def forward(x, block):
block.initialize()
return block(x)
Y1 = forward(np.zeros((2, 8, 20, 20)), cls_predictor(5, 10))
Y2 = forward(np.zeros((2, 16, 10, 10)), cls_predictor(3, 10))
(Y1.shape, Y2.shape)
((2, 55, 20, 20), (2, 33, 10, 10))
通道尺寸包含具有相同中心的所有锚定盒的预测。我们首先将通道维度移动到最后一个维度。我们可以将批量大小转换为相同的二进制大小(因为批量大小的预测是相同的)(batch size, height ×× width ×× number of channels),以便于后续在第一尺寸。
def flatten_pred(pred):
return npx.batch_flatten(pred.transpose(0, 2, 3, 1))
def concat_preds(preds):
return np.concatenate([flatten_pred(p) for p in preds], axis=1)
因此,尽管Y1和Y2的形态不同,我们仍然可以将同一批次的两个不同尺度的预测结果串联起来。
concat_preds([Y1, Y2]).shape
(2, 25300)
1.4. Height and Width Downsample Block
对于多尺度目标检测,我们定义了下面的下采样块,它将高度和宽度减少了50%。这个街区有两个3×3,填充为1和a的卷积层2×2,以串联方式连接的跨距为2的最大池化层。我们知道,3×3填充为1的卷积层不会改变特征映射的形状。然而,随后的池化层直接将特征图的大小缩小了一半。因为1×2+(3−1)+(3−1)=6,输出特征映射中的每个元素在形状的输入特征映射上都有一个接受域6×6。height和width downsample块放大了输出特征映射中每个元素的感受野。
def down_sample_blk(num_channels):
blk = nn.Sequential()
for _ in range(2):
blk.add(nn.Conv2D(num_channels, kernel_size=3, padding=1),
nn.BatchNorm(in_channels=num_channels),
nn.Activation(‘relu‘))
blk.add(nn.MaxPool2D(2))
return blk
通过在height和width下采样块中测试正向计算,我们可以看到它改变了输入通道的数目,并使高度和宽度减半。
forward(np.zeros((2, 3, 20, 20)), down_sample_blk(10)).shape
(2, 10, 10, 10)
1.5. Base Network Block
基本网络块用于从原始图像中提取特征。为了简化计算,我们将构造一个基础小网络。该网络由三个高度和宽度的下采样块串联而成,因此在每一步中它的通道数加倍。当我们用输入原始256×256图像时,基础网络块输出具有该形状的特征映射32×32。
def base_net():
blk = nn.Sequential()
for num_filters in [16, 32, 64]:
blk.add(down_sample_blk(num_filters))
return blk
forward(np.zeros((2, 3, 256, 256)), base_net()).shape
(2, 64, 32, 32)
1.6. The Complete Model
SSD型号共包含五个模块。每个模块输出一个特征映射,用于生成锚框并预测这些锚框的类别和偏移量。第一个模块是基本网络块,模块2到4个是高度和宽度下采样块,第五个模块是一个全局最大池化层,它将高度和宽度减小到1。因此,模块2到5都是图1所示的多尺度特征块。
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 4:
blk = nn.GlobalMaxPool2D()
else:
blk = down_sample_blk(128)
return blk
定义每个模块的正向计算过程。与前面描述的卷积神经网络相比,该模块不仅返回卷积计算输出的特征映射Y,而且返回由Y生成的当前尺度的锚盒及其预测的类别和偏移量。
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = npx.multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
当我们在图7.1中提到的更大的目标块时,它必须生成一个更大的锚框。在这里,我们首先将0.2到1.05的间隔分成五个相等的部分,以确定不同比例的较小锚箱的尺寸:0.2、0.37、0.54等,然后根据SQRT(0.2×0.37)= 0.272,SQRT(0.37×0.54)= 0.447,
以及类似的公式,确定了不同尺度下较大锚箱的尺寸。
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) – 1
可以定义完整的模型,TinySSD。
class TinySSD(nn.Block):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
for i in range(5):
# The assignment statement is self.blk_i = get_blk(i)
setattr(self, ‘blk_%d‘ % i, get_blk(i))
setattr(self, ‘cls_%d‘ % i, cls_predictor(num_anchors,
num_classes))
setattr(self, ‘bbox_%d‘ % i, bbox_predictor(num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self, ‘blk_%d‘ % i) accesses self.blk_i
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, ‘blk_%d‘ % i), sizes[i], ratios[i],
getattr(self, ‘cls_%d‘ % i), getattr(self, ‘bbox_%d‘ % i))
# In the reshape function, 0 indicates that the batch size remains
# unchanged
anchors = np.concatenate(anchors, axis=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
现在,我们创建一个SSD模型实例,并使用它对图像minibatchx执行正向计算,它的高度和宽度为256像素。如前所述,第一个模块输出带有形状的特征映射32×32。因为模块2到4是高度和宽度的下采样块,模块5是一个全局池化层,并且特征图中的每个元素都被用作4个锚框的中心,总共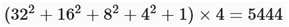 ,在五个比例下为每个图像生成锚框。
,在五个比例下为每个图像生成锚框。
net = TinySSD(num_classes=1)
net.initialize()
X = np.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print(‘output anchors:‘, anchors.shape)
print(‘output class preds:‘, cls_preds.shape)
print(‘output bbox preds:‘, bbox_preds.shape)
output anchors: (1, 5444, 4)
output class preds: (32, 5444, 2)
output bbox preds: (32, 21776)
Single Shot Multibox Detection (SSD)实战(上)
标签:cto 包围盒 tin 神经网络 dash 特性 range width pre
原文地址:https://www.cnblogs.com/wujianming-110117/p/13213428.html