标签:输入数据 load int 鉴别器 lang 生效 关联 dfa 扩展
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
用户自定义函数类别分为以下三种
UDF(User-Defined-Function)
一进一出
UDAF(User-Defined Aggregation Function)
多进一出;如聚集函数
UDTF(User-Defined Table-Generating Functions)
一进多出;如炸裂函数(explode)
临时函数:只存在当前会话,切换或断开就没有了,和当前use的库没有关系
删除临时函数:drop temporary function 函数名 或者 断开会话
永久函数:和库关联,在创建的时候需要指定库a.函数名,在使用的时候如果当前使用的库就是
(1)官方文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
(2)继承Hive提供的类
? 3.x逐渐弃用UDF类,推荐用下面的
? org.apache.hadoop.hive.ql.udf.generic.GenericUDF
? org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
(3)实现类中的抽象方法
(4)在hive的命令行窗口创建函数
添加jar
add jar linux_jar_path
创建function
create [temporary] function [dbname.]function_name AS class_name;
(5)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
MyLen.java
package com.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* @description: 自定义UDF函数类, 求输入数据长度,只能处理一个hive的基本类型参数
* @author: HaoWu
* @create: 2020/6/30 11:39
*/
//hive3.X的UDF类已废除,推荐用GenericUDF
public class MyLen extends GenericUDF {
/**
* 初始化
*
* @param objectInspectors 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
//判断输入参数的个数
if (objectInspectors.length != 1) {
throw new UDFArgumentLengthException("input args nums Error...");
}
//判断输入参数的类型是否为hive基本类型
if (!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(0, "input args type Error...");
}
//函数本身返回int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数处理逻辑
*
* @param deferredObjects
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
if (deferredObjects[0].get() == null) {
return 0;
}
Object obj = deferredObjects[0];
int len = obj.toString().length();
return len;
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
打包插件
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 指定主类 -->
<mainClass>com.hive.udf.MyLen</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
打包package,然后改名为mylen_udf.jar
[atguigu@hadoop102 datas]$ tree /opt/module/hive/datas/
/opt/module/hive/datas/
└── my_len.jar
add jar /opt/module/hive/datas/mylen_udf.jar
create temporary function mylenudf as "com.hive.udf.MyLen"
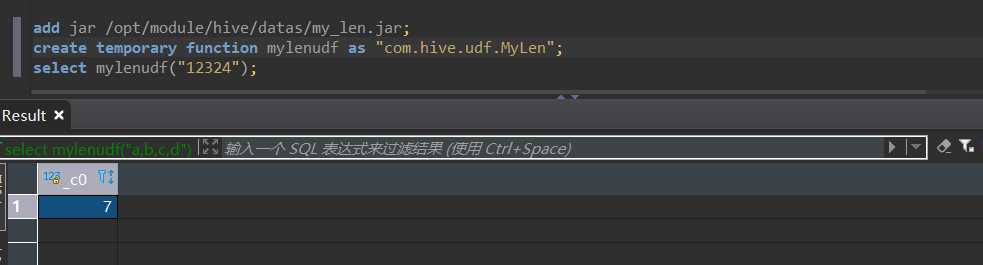
添加jar包的类路径给hive,注意是临时生效
add jar /opt/module/hive/datas/myudf.jar;
创建临时函数
create temporary function my_len as "com.atguigu.hive.udf.MyStringLength";
删除临时函数
drop temporary function my_len;
注意:临时函数只跟会话有关系,只要会话不断,在当前会话下,任意一个库都可以使用。其他会话全都不能使用。
注意:因为永久函数是永久生效的,我们推出当前会话以后,其他会话也要使用永久函数,因此我们就不能简单的使用add jar来添加hive的类路径了
创建永久函数
注意:此时要使用USING JAR的方式来添加函数的jar包类路径,并且这个路径必须是hdfs路径
create function my_len2 as "com.atguigu.hive.udf.MyStringLength" USING JAR ‘hdfs://hadoop102:9820/hivejar/myudf.jar‘;
删除永久函数
drop function my_len2;
注意:永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
然后使用永久函数的时候,需要在指定的库里面操作,或者在其他库里面使用的话得加上 库名.函数名
标签:输入数据 load int 鉴别器 lang 生效 关联 dfa 扩展
原文地址:https://www.cnblogs.com/wh984763176/p/13215452.html