标签:rop code 移除 执行 object 过程 loading int mode
基于区域的CNN(R-CNN)
Region-based CNNs (R-CNNs)
基于区域的卷积神经网络或具有CNN特征的区域(R-CNN)是一种将深度模型应用于目标检测的开创性方法。在本节中,将讨论R-CNN及其一系列改进:Fast R-CNN[Girshick,2015]、Faster R-CNN和Mask R-CNN。由于篇幅的限制,将把讨论局限于这些模型的设计上。
1. R-CNNs
R-CNN模型首先从一幅图像中选择几个建议的区域(例如,锚框是一种选择方法),然后标记类别和边界框(例如偏移量)。然后,使用CNN进行前向计算,从每个提议的区域提取特征。然后,利用每个区域的特征来预测类别和边界框。图1显示了R-CNN模型。
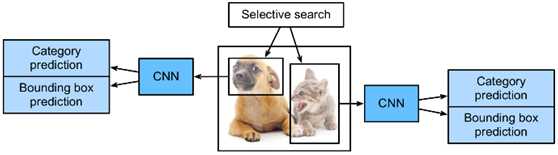
Fig. 1 R-CNN model.
具体而言,R-CNN由四个主要部分组成:
对输入图像执行选择性搜索以选择多个高质量的建议区域。这些建议的区域通常在多个尺度上选择,并且具有不同的形状和大小。对每个建议区域的类别和真实边界框进行标记。
一个预先训练的CNN被选择并以截短的形式放置在输出层之前。将每个提出的区域转换成网络所需的输入维数,并使用正向计算输出从该区域提取的特征。
以每个区域的特征和标记类别为例,训练多个支持向量机进行目标分类。在这里,每个支持向量机被用来确定一个例子是否属于某个类别。
以每个区域的特征和标记边界盒为例,训练了一个用于真实边界盒预测的线性回归模型。
虽然R-CNN模型使用预先训练的CNN来有效地提取图像特征,但其主要缺点是速度慢。正如所想象的,可以从一张图像中选择数千个建议区域,这需要CNN进行数千次前向计算来执行目标检测。这种巨大的计算负载意味着R-cnn在实际应用中并没有得到广泛的应用。
2. Fast R-CNN
R-CNN模型的主要性能瓶颈是需要为每个提出的区域独立提取特征。由于这些区域具有高度的重叠,独立的特征提取会导致大量的重复计算。快速R-CNN改进了R-CNN,只对图像进行CNN前向计算。
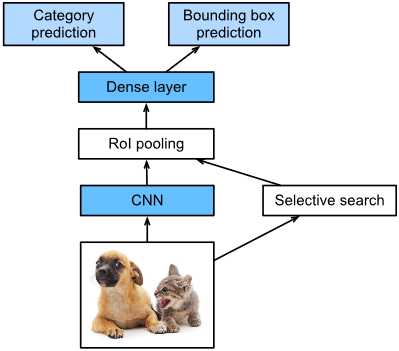
Fig. 2 Fast R-CNN model.
图2显示了快速R-CNN模型。主要计算步骤如下:
与R-CNN模型相比,快速R-CNN模型使用整个图像作为CNN的输入进行特征提取,而不是每个区域。此外,该网络通常被训练来更新模型参数。由于输入是一个完整的图像,CNN的输出形状是1×c×h1×w11×c×h1×w1。
假设选择性搜索生成 n建议的区域,不同形状表示CNN输出上不同形状的感兴趣区域(roi)。必须从这些ROI中提取相同形状的特征(这里假设高度为h2,宽度为w2)。快速R-CNN引入了RoI池,使用CNN输出和RoI作为输入,输出从每个建议区域提取的特征与形状的连接 n×c×h2×w。
一个全连接的层用于将输出形状转换为n×d,其中d由模型设计决定。
在类别预测期间,完全连接层输出的形状再次转换为n×q。使用softmax回归(q是类别的数量)。在边界盒预测期间,全连接层输出的形状再次转换为n×4。这意味着预测每个建议区域的类别和边界框。
Fast R-CNN中的RoI池层与之前讨论过的池化层有些不同。在普通的池层中,设置池化窗口、填充和步幅来控制输出形状。在RoI池化层中,可以直接指定每个区域的输出形状,例如将每个区域的高度和宽度指定为h2, w2. 假设窗口的宽度h和w,此窗口被划分为具有形状的子窗口的网格h2×w2。每个子窗口的大小约为(h/h2)×(w/w2)。子窗口的高度和宽度必须始终为整数,并且将最大元素用作给定子窗口的输出。这允许RoI池化层从不同形状的RoI中提取相同形状的特征。
在图3中,选择3×3区域作为投资回报率4×4输入。对于这个投资回报率,使用2×2 RoI池化层2×2输出。当将区域划分为四个子窗口时,分别包含元素0、1、4和5(5是最大的);2和6(6是最大的);8和9(9是最大的);和10。
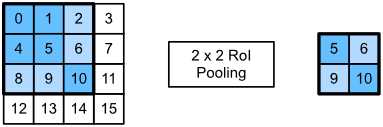
Fig. 3 2×22×2 RoI pooling layer.
使用ROIPooling函数来演示RoI池层的计算。假设CNN提取的特征X的高度和宽度都是4并且只有一个通道。
from mxnet import np, npx
npx.set_np()
X = np.arange(16).reshape(1, 1, 4, 4)
X
array([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
假设图像的高度和宽度都是40像素,并且选择性搜索在图像上生成两个建议的区域。每个区域用五个元素表示:区域的对象类别和其左上角和右下角的坐标x、 y。
rois = np.array([[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]])
因为X的高度和宽度是图像的高度和宽度的1/10,将两个区域的坐标按spatial_scale乘以0.1,然后在X上标记为X[:,:,0:3,0:3]和X[:,:,1:4,0:4]。最后,将两个ROI划分为一个子窗口网格,提取高度和宽度为2的特征。
npx.roi_pooling(X, rois, pooled_size=(2, 2), spatial_scale=0.1)
array([[[[ 5., 6.],
[ 9., 10.]]],
[[[ 9., 11.],
[13., 15.]]]])
3. Faster R-CNN
为了获得精确的目标检测结果,快速R-CNN通常要求在选择性搜索中生成多个建议区域。更快的R-CNN用区域建议网络代替选择性搜索。这样可以减少生成的建议区域的数量,同时确保精确的目标检测。
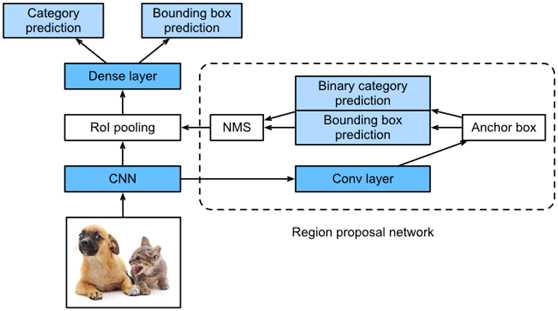
Fig. 4 Faster R-CNN model.
图4显示了一个更快的R-CNN模型。与快速R-CNN相比,更快的R-CNN只改变了生成区域的方法,从选择性搜索到区域建议网络。模型的其部分保持不变。详细的区域方案网络计算过程如下:
使用3×3卷积层,填充为1,用于转换CNN输出并将输出通道数设置为c。这样,CNN从图像中提取的特征映射中的每个元素都是一个长度为c的新特征。使用特征图中的每个元素作为中心来生成不同大小和高宽比的多个锚框,然后标记。使用长度元素的特征c在锚框的中心位置预测二进制类别(对象或背景)和各自锚框的边界框。然后,使用非最大值抑制来移除与“对象”类别预测相对应的类似边界框结果。最后,将预测的边界框输出为RoI池层所需的区域。
值得注意的是,作为快速R-CNN模型的一部分,区域提案网络与模型的其部分一起训练。此外,快速R-CNN目标函数包括目标检测中的类别和边界盒预测,以及区域建议网络中锚盒的二元类别和边界盒预测。最后,区域建议网络可以学习如何生成高质量的建议区域,从而在保持目标检测精度的同时减少建议区域的数量。
4. Mask R-CNN
如果训练数据被标记为图像中每个目标的像素级位置,则掩模R-CNN模型可以有效地利用这些细节标签进一步提高目标检测的精度。
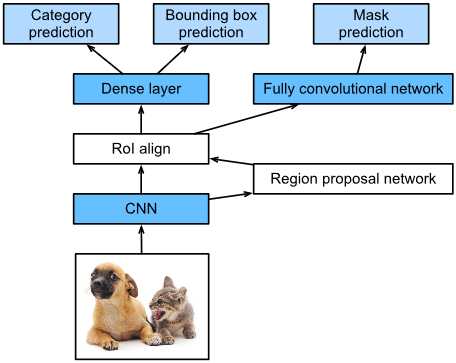
Fig. 5 Mask R-CNN model.
如图5所示,掩模R-CNN是对更快的R-CNN模型的改进。掩模R-CNN模型用RoI对齐层代替RoI池化层。这允许使用双线性插值来保留特征地图上的空间信息,使掩模R-CNN更适合像素级预测。RoI对齐层为所有RoI输出相同形状的特征映射。这不仅可以预测roi的类别和边界框,而且允许使用额外的完全卷积网络来预测对象的像素级位置。将在本章后面描述如何使用完全卷积网络来预测图像中的像素级语义。
5. Summary
标签:rop code 移除 执行 object 过程 loading int mode
原文地址:https://www.cnblogs.com/wujianming-110117/p/13215501.html