标签:基础上 mon 权重 cin squeeze 就是 图片 none sel
矩阵分解
Matrix Factorization
矩阵因子分解[Koren等人,2009]是推荐系统文献中一个成熟的算法。矩阵分解模型的第一个版本是由simonfunk在一篇著名的博客文章中提出的,在文章中描述了将交互矩阵分解的思想。后来由于2006年举行的Netflix竞赛而广为人知。当时,流媒体和视频租赁公司Netflix宣布举办一场竞赛,以提高推荐系统的性能。在Netflix基线(即Cinematch)基础上提高10%的最佳团队将获得100万美元奖金。正因如此,本次大赛引起了推荐系统研究领域的广泛关注。随后,BellKor的实用主义混沌团队赢得了大奖,该团队由BellKor、语用理论和BigChaos组成(现在不需要担心这些算法)。虽然最终得分是一个整体解决方案(即,许多算法的组合)的结果,矩阵分解算法在最终的混合中起着关键作用。技术报告Netflix Grand Prize solution【Toscher等人,2009年】对采用的模型进行了详细介绍。在本文中,将深入研究矩阵分解模型及其实现的细节。
1. The Matrix Factorization Model
矩阵分解是一类协同过滤模型。具体而言,该模型将用户-项目交互矩阵(如评分矩阵)分解为两个低秩矩阵的乘积,捕捉用户-项目交互的低秩结构。


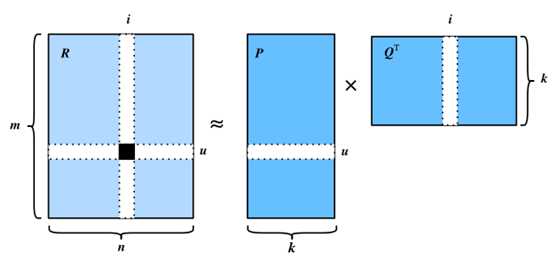
Fig. 1 Illustration of matrix factorization model
在本节的其余部分中,将解释矩阵分解的实现,并在MovieLens数据集上训练模型。
from d2l import mxnet as d2l
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
import mxnet as mx
npx.set_np()
2. Model Implementation
首先,实现了上面描述的矩阵分解模型。用户和项目的潜在因素可以用nn.Embedding。input_dim是items/users and the (output_dim)的数量,(output_dim)是潜在因素的维度(k). 也可以使用nn.Embedding通过将output _dim设置为1来创建items/users偏差。在forward函数中,用户和项目id用于查找嵌入项。
class MF(nn.Block):
def __init__(self, num_factors, num_users, num_items, **kwargs):
super(MF, self).__init__(**kwargs)
self.P = nn.Embedding(input_dim=num_users, output_dim=num_factors)
self.Q = nn.Embedding(input_dim=num_items, output_dim=num_factors)
self.user_bias = nn.Embedding(num_users, 1)
self.item_bias = nn.Embedding(num_items, 1)
def forward(self, user_id, item_id):
P_u = self.P(user_id)
Q_i = self.Q(item_id)
b_u = self.user_bias(user_id)
b_i = self.item_bias(item_id)
outputs = (P_u * Q_i).sum(axis=1) + np.squeeze(b_u) + np.squeeze(b_i)
return outputs.flatten()
3. Evaluation Measures
然后,实施RMSE(均方根误差)测量,该测量通常用于测量模型预测的评级分数与实际观察的评级(基本真实情况)之间的差异。RMSE定义为:
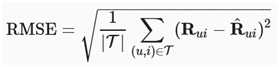
其中T是由要对其求值的用户和项对组成的集。|T|就是这数据集的大小。可以使用mx公制。
def evaluator(net, test_iter, ctx):
rmse = mx.metric.RMSE() # Get the RMSE
rmse_list = []
for idx, (users, items, ratings) in enumerate(test_iter):
u = gluon.utils.split_and_load(users, ctx, even_split=False)
i = gluon.utils.split_and_load(items, ctx, even_split=False)
r_ui = gluon.utils.split_and_load(ratings, ctx, even_split=False)
r_hat = [net(u, i) for u, i in zip(u, i)]
rmse.update(labels=r_ui, preds=r_hat)
rmse_list.append(rmse.get()[1])
return float(np.mean(np.array(rmse_list)))
4. Training and Evaluating the Model
在训练模块中,采用L2级权重loss。权重衰减机制与L2级正规化。
#@save
def train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs,
ctx_list=d2l.try_all_gpus(), evaluator=None,
**kwargs):
timer = d2l.Timer()
animator = d2l.Animator(xlabel=‘epoch‘, xlim=[1, num_epochs], ylim=[0, 2],
legend=[‘train loss‘, ‘test RMSE‘])
for epoch in range(num_epochs):
metric, l = d2l.Accumulator(3), 0.
for i, values in enumerate(train_iter):
timer.start()
input_data = []
values = values if isinstance(values, list) else [values]
for v in values:
input_data.append(gluon.utils.split_and_load(v, ctx_list))
train_feat = input_data[0:-1] if len(values) > 1 else input_data
train_label = input_data[-1]
with autograd.record():
preds = [net(*t) for t in zip(*train_feat)]
ls = [loss(p, s) for p, s in zip(preds, train_label)]
[l.backward() for l in ls]
l += sum([l.asnumpy() for l in ls]).mean() / len(ctx_list)
trainer.step(values[0].shape[0])
metric.add(l, values[0].shape[0], values[0].size)
timer.stop()
if len(kwargs) > 0: # it will be used in section AutoRec.
test_rmse = evaluator(net, test_iter, kwargs[‘inter_mat‘],
ctx_list)
else:
test_rmse = evaluator(net, test_iter, ctx_list)
train_l = l / (i + 1)
animator.add(epoch + 1, (train_l, test_rmse))
print(‘train loss %.3f, test RMSE %.3f‘
% (metric[0] / metric[1], test_rmse))
print(‘%.1f examples/sec on %s‘
% (metric[2] * num_epochs / timer.sum(), ctx_list))
最后,让把所有的东西放在一起训练模型。这里,将潜在因子维度设置为30。
ctx = d2l.try_all_gpus()
num_users, num_items, train_iter, test_iter = d2l.split_and_load_ml100k(
test_ratio=0.1, batch_size=512)
net = MF(30, num_users, num_items)
net.initialize(ctx=ctx, force_reinit=True, init=mx.init.Normal(0.01))
lr, num_epochs, wd, optimizer = 0.002, 20, 1e-5, ‘adam‘
loss = gluon.loss.L2Loss()
trainer = gluon.Trainer(net.collect_params(), optimizer,
{"learning_rate": lr, ‘wd‘: wd})
train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs,
ctx, evaluator)
train loss 0.067, test RMSE 1.051
70619.5 examples/sec on [gpu(0), gpu(1)]
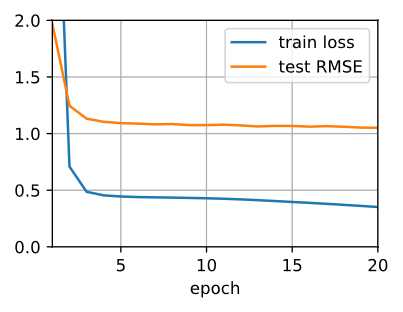
下面,使用经过训练的模型来预测用户(ID 20)可能对项目(ID 30)的评分。
scores = net(np.array([20], dtype=‘int‘, ctx=d2l.try_gpu()),
np.array([30], dtype=‘int‘, ctx=d2l.try_gpu()))
scores
scores = net(np.array([20], dtype=‘int‘, ctx=d2l.try_gpu()),
np.array([30], dtype=‘int‘, ctx=d2l.try_gpu()))
scores
5. Summary
标签:基础上 mon 权重 cin squeeze 就是 图片 none sel
原文地址:https://www.cnblogs.com/wujianming-110117/p/13221022.html