标签:address str ble 初始化 出栈 多个 遇到 空间 期望
先上图,妈的说个题外话,工作真的难找,吐血!!!!
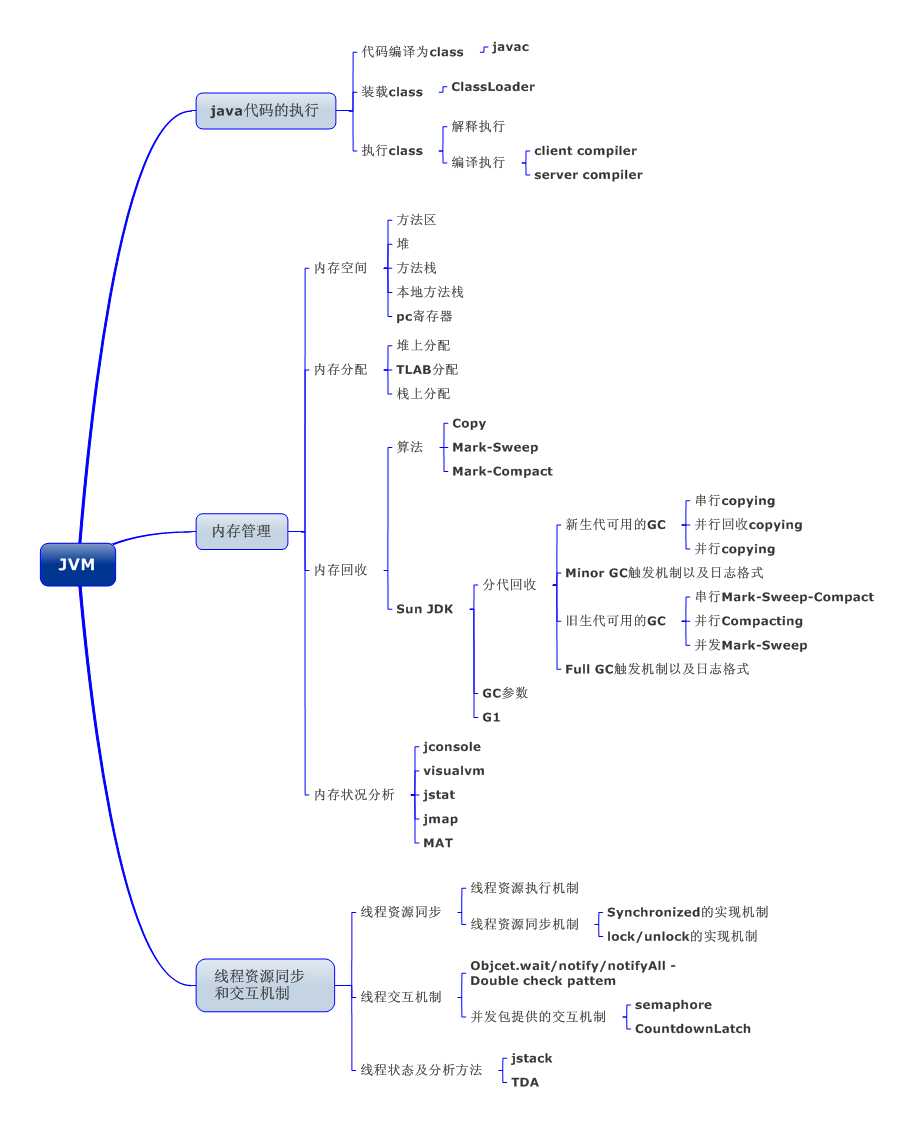
首先JVM 是可运行 Java 代码的假想计算机 , 括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收,堆 和 一个存储方法域。JVM 是运行在操作系统之上的,它与硬件没有直接的交互。
之所以说可以跨平台就是因为JVM的存在。
通过这个路径就可以实现跨平台
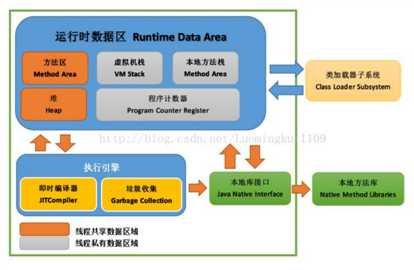
这是一张经典图,里面记录了JVM中的内存基础模型,同时也画出了基本的流程。
当我们的class文件进入到JVM中的时候,首先会有一个初始化的过程,当线程本地存储、缓冲区分配、同步对象、Java虚拟机栈、程序计数器等准备好以后,就会创建一个操作系统原生线程。Java 线程结束,原生线程随之被回收。操作系统负责调度所有线程,并把它们分配到任何可用的 CPU 上。当原生线程初始化完毕,就会调用 Java 线程的 run() 方法。当线程结束时,会释放原生线程和 Java 线程的所有资源。
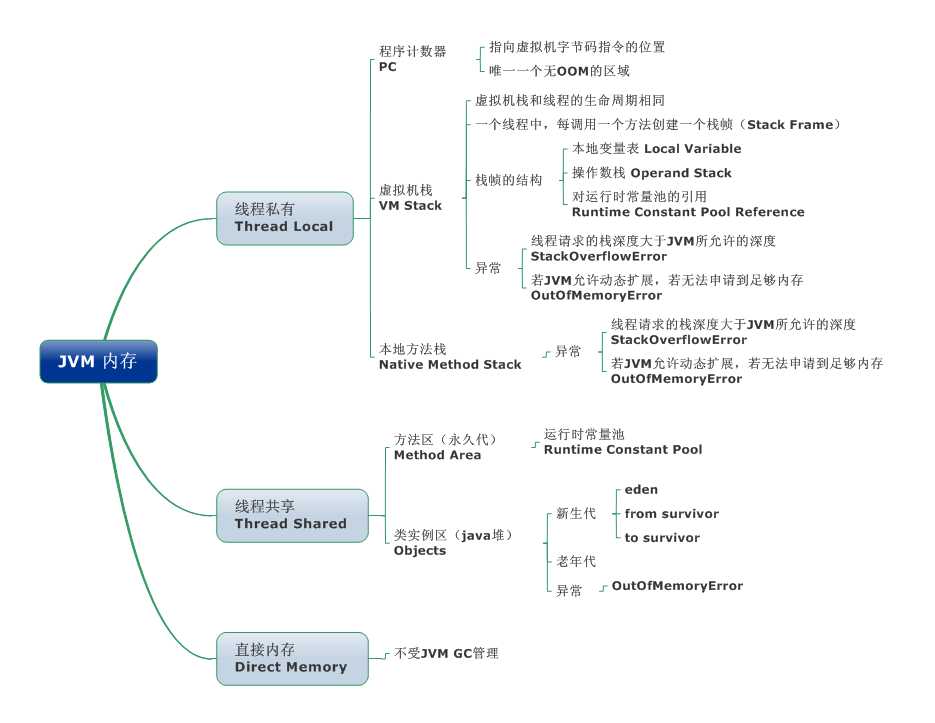
上图为JVM内存的详细模型图,具体的含义可以看我之前的文章《自动内存管理机制》这边要注意的是方法区其实真正意义上的永久代,另外栈一般指的是虚拟机栈,堆指的是数据区
详细说一下之前没写到的。
本地变量表:是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。局部变量表的容量以变量槽(Variable Slot)为最小单位,Java虚拟机规范并没有定义一个槽所应该占用内存空间的大小,但是规定了一个槽应该可以存放一个32位以内的数据类型。最简单的例子就是方法内定义的数据。一个局部变量可以保存一个类型为boolean、byte、char、short、int、float、reference和returnAddress类型的数据。reference类型表示对一个对象实例的引用。returnAddress类型是为jsr、jsr_w和ret指令服务的,目前已经很少使用了。虚拟机通过索引定位的方法查找相应的局部变量,索引的范围是从0~局部变量表最大容量。如果Slot是32位的,则遇到一个64位数据类型的变量(如long或double型),则会连续使用两个连续的Slot来存储。
操作数栈:也常称为操作栈,它是一个后入先出栈(LIFO)。同局部变量表一样,操作数栈的最大深度也在编译的时候写入到方法的Code属性的max_stacks数据项中。操作数栈的每一个元素可以是任意Java数据类型,32位的数据类型占一个栈容量,64位的数据类型占2个栈容量,且在方法执行的任意时刻,操作数栈的深度都不会超过max_stacks中设置的最大值。当一个方法刚刚开始执行时,其操作数栈是空的,随着方法执行和字节码指令的执行,会从局部变量表或对象实例的字段中复制常量或变量写入到操作数栈,再随着计算的进行将栈中元素出栈到局部变量表或者返回给方法调用者,也就是出栈/入栈操作。一个完整的方法执行期间往往包含多个这样出栈/入栈的过程。
JVM运行时的内存
其实按照严格的意义上讲,GC的算法不同对于区的分配是不同的,就像远古时期的时候,直接一个计数器就可以分出新生和老年代。但是随着算法的进步以及JVM的完善,现在目前我们使用的JDK1.8使用的GC算法,把新生代再一次划分成了三个不同的区用来存放新生的对象。一般占据堆的 1/3 空间。由于频繁创建对象,所以新生代会频繁触发MinorGC 进行垃圾回收。新生代又分为 Eden 区、ServivorFrom、ServivorTo 三个区。
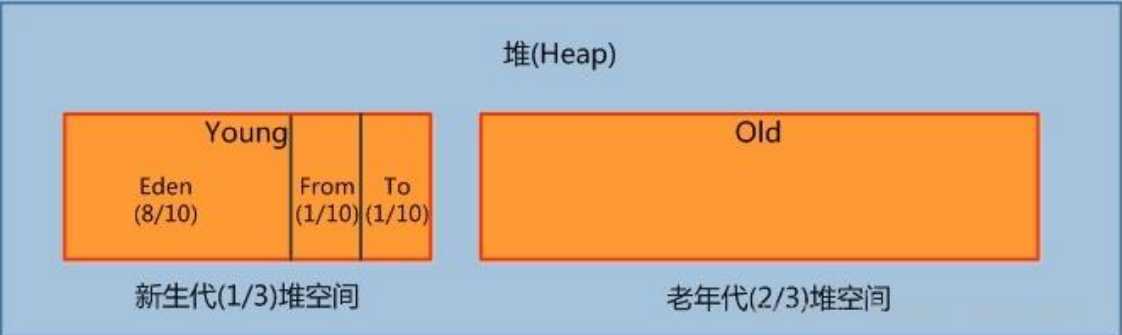
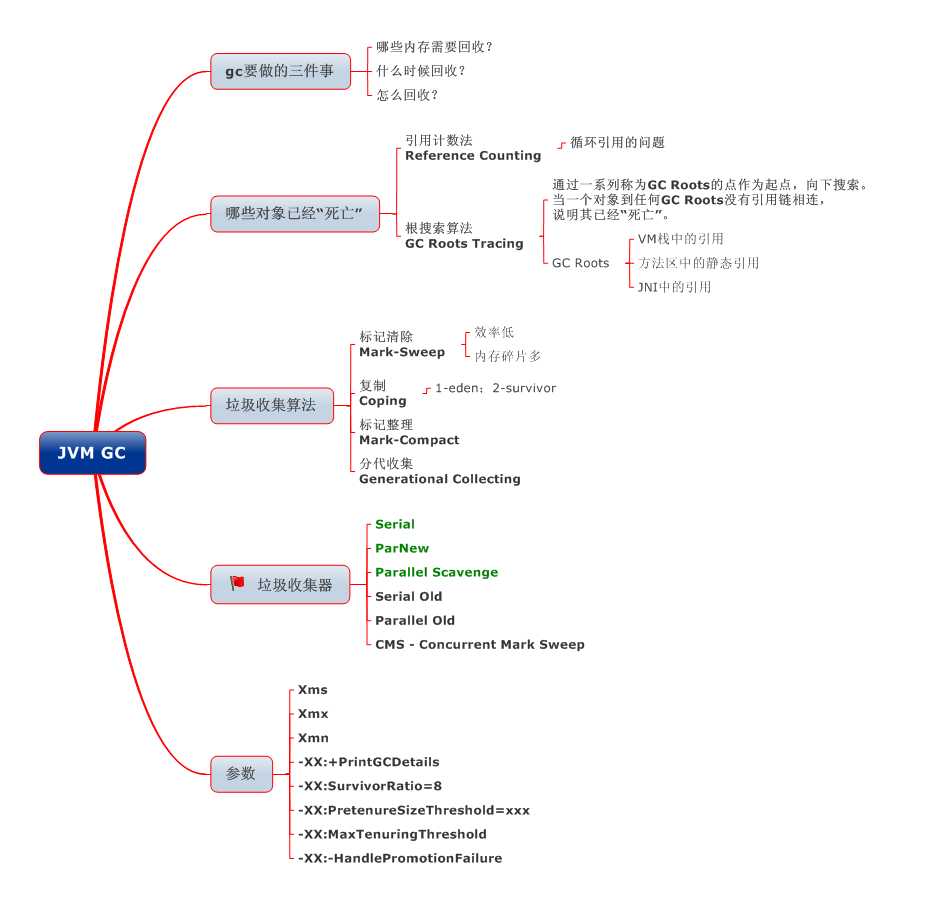
这一张是GC需要复习到的图。
引用计数法:这是一个简单而高效的方法,就像“大道至简”,其实我个人对这个的看法是不一样的,包括python目前也是使用这一种的方法来进行回收。我只需要找这个内存有没有被引用就可以知道有没有被使用,如果没有被使用那么自然可以被回收。其实这我怀疑也是最早JVM设计时候的想法。JVM那时候提出的期望就是:无需程序员去操作内存并且JVM会是一个通用的语言虚拟机,事实证明JVM目前已经可以支持多种语言了,例如Jython。
可达性分析算法:从字面其实我们就可以看得出,可达=>可以达到。将GC roots(a.虚拟机栈栈桢中的本地变量表b.方法区中的类静态属性引用的对象c.方法区中的常量引用的对象d.本地方法栈中JNI的引用的对象)作为根,从上到下的找,这个GC roots所需要的东西中的引用的对象.不可达对象不等价于可回收对象,不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
JAVA 四中引用类型
标签:address str ble 初始化 出栈 多个 遇到 空间 期望
原文地址:https://www.cnblogs.com/SmartCat994/p/13221062.html