标签:地址 生成 flush 模式 输出 自己 允许 硬件 策略
集群搭建好之后网络,raid卡策略,磁盘都会影响集群的性能。为了避免因上述问题使得集群的性能受到影响,我们依次进行测试,最后得到基本的集群性能。
首先是网络,ceph集群一大堆让人摸不着头脑的问题都出在网络上,所以我们在建立集群之前就可以测试网络,看其是否有问题,可以通过ping命令来测试网络的连通性,但最好使用iperf,测试下网络传输速度。
遇到有不少现场情况,因为光模块导致万兆网络只有百兆的速度,如果等集群建好之后性能不如意,花费大量时间排查发现是这个问题就太冤了。
选择一个节点作为iperf server
iperf -s
选择其他节点作为iperf client,比如server IP地址为192.168.12.4
iperf -c 192.168.12.4 -i 1 -t 5
# -i: 间隔多少秒报告一次结果
# -t: 向服务器发送多少秒
# 结果如下
[ 3] 0.0- 1.0 sec 575 MBytes 4.83 Gbits/sec
[ 3] 1.0- 2.0 sec 361 MBytes 3.03 Gbits/sec
[ 3] 2.0- 3.0 sec 618 MBytes 5.18 Gbits/sec
[ 3] 3.0- 4.0 sec 423 MBytes 3.55 Gbits/sec
[ 3] 4.0- 5.0 sec 519 MBytes 4.35 Gbits/sec
[ 3] 0.0- 5.0 sec 2.44 GBytes 4.19 Gbits/sec
# 最后一行为 0-5秒的平均速度
iperf -c 192.168.12.4 -i 1 -t 10 |awk ‘/sec/ {print $8,9}‘
一般ceph的内部通信网络是万兆网络,那通过iperf测试的速度为8-9Gbits/sec为正常,一次测试每个节点,没问题后接下来检查raid卡cache策略
基于megacli的raid相关操作可参考我的《Raid操作与坏盘诊断》
总之,如果有BBU,设置raid cache为No Write Cache if Bad BBU
# 查看是否存在BBU
/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -aAll
# 设置为No Write Cache if Bad BBU,即BBU损坏或learning时变为Write Through
/opt/MegaRAID/MegaCli/MegaCli64 -LDSetProp -NoCachedBadBBU -Immediate -Lall -aAll
带宽和IOPS测试的时候要同时使用atop来看当前测试压力的瓶颈在哪里,以三节点集群为例,通常使用两台节点同时往集群写入数据就可以测出最大性能,但是如果硬件设备配置很高,这时候atop观察发现两台同时给压力集群还是没有满负荷跑,可以使用三个节点同时压:
通常带宽使用1M的数据块来顺序写测试,IOPS使用4K小文件随机写来测试
带宽测试的瓶颈往往在万兆网卡上,atop命令可以看到万兆卡被压红
IOPS的瓶颈往往在磁盘上,atop可以看到不同节点的磁盘轮番被压红,或者同时压红则正常。如果发现有一个节点始终没有太大的变化,就需要去排查分析是否有问题
注意无论是dd命令还是fio命令,都不要对系统盘写,尤其是直接对系统块设备写,会直接抹掉系统数据。
以集群提供的NAS文件夹为例,如果为3节点集群,可以利用其中两个节点向同一文件夹同时写入,最后将结果相加
以顺序写为例:
进入nas目录里(同时写入的两个节点of文件名取不同的,否则测试结果偏高),同时从两个节点写数据,带宽为1.7GB/s(两个节点测试结果之和)


# 测nas文件夹写速率
dd if=/dev/zero of=dd.client1 bs=1M count=40960 conv=fsync
# of:要写到哪个文件
# bs:同时设置读入/输出的数据块大小为1M
# count:共复制多少个bs 此处:bs=1M count=40960,则一共写入40G数据
# conv=fsync:在完成dd命令前需要确保文件的data和metadata都flush到后端存储,如果不加这个选项,可能还没写到存储上,只存在于客户端的memory里就结束了,这样的结果会偏高。
一般使用fio工具来测试IOPS,fio也可以测试带宽。
- 测试IOPS一般使用4K的数据块
- 测试带宽建议使用大于等于1M的数据块
我们使用集群提供的块服务(iscsi),如块名为rbd0
下图为同时从两个节点向/dev/rbd0写如数据的IOPS测试结果,同理,将两个IOPS的值相加即粗略得到集群的IOPS,记得上面说到的用atop查看三个节点的磁盘状态,最直观的就是是否压红
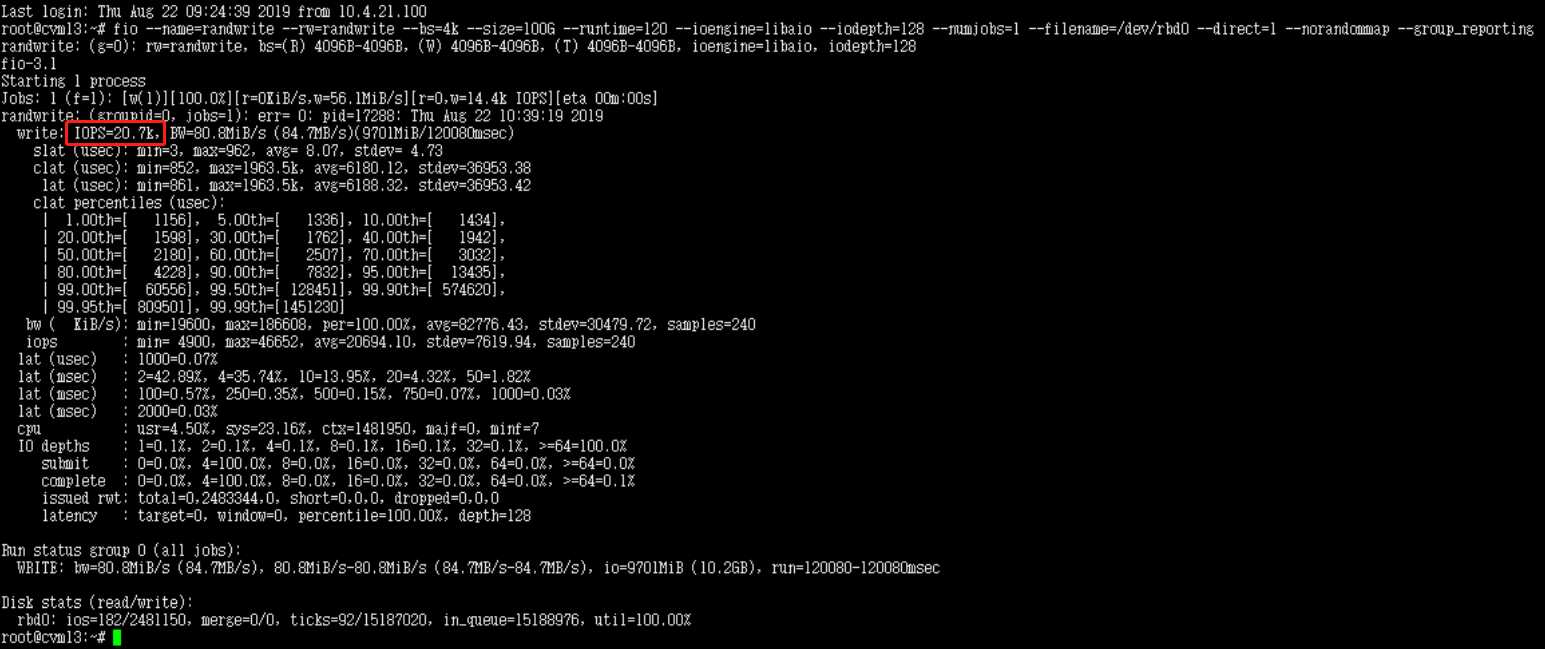
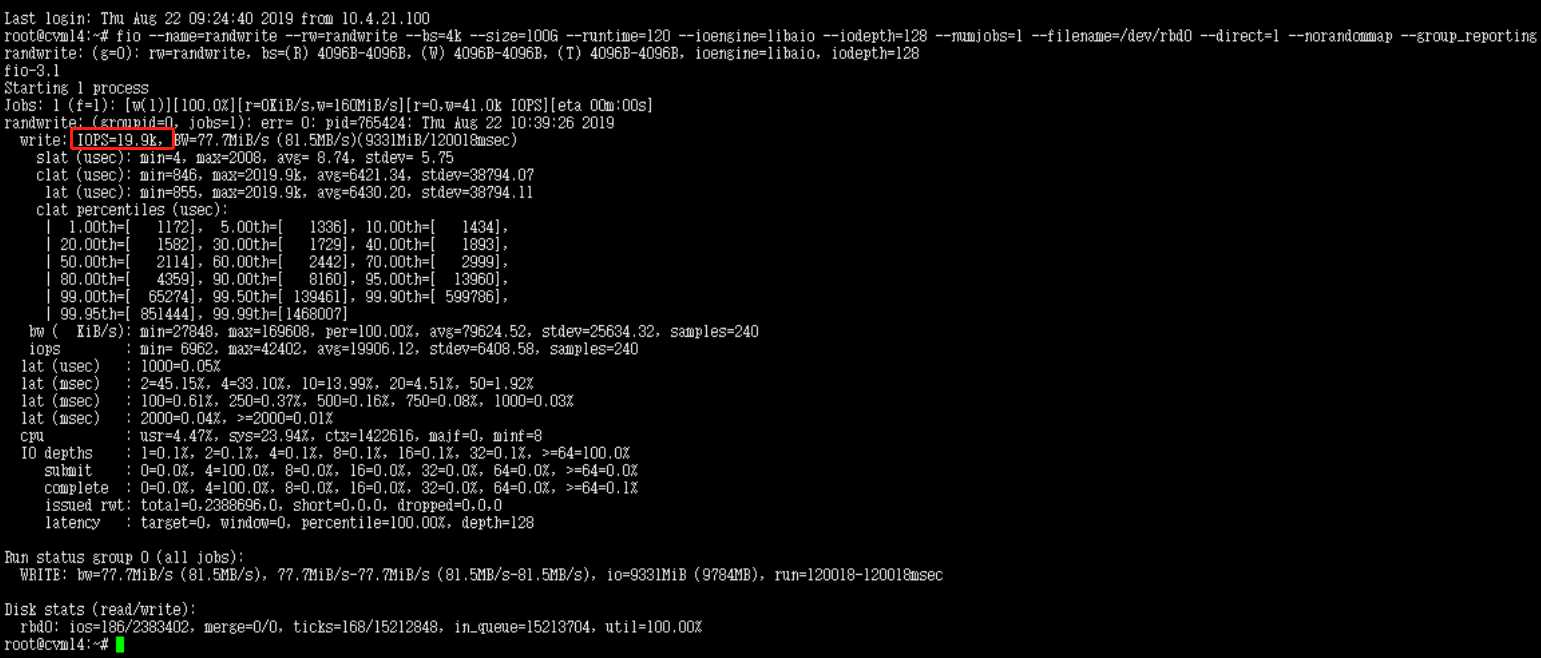
# 测rbd IOPS
fio --name=randwrite --rw=randwrite --bs=4k --size=100G --runtime=120 --ioengine=libaio --iodepth=128 --numjobs=1 --filename=/dev/rbd0 --direct=1 --norandommap --randrepeat=0 --group_reporting
--name=randwrite # Job的名称,命令行模式下的必填项,如果没有指定filename,那么将会根据这个name来生成filename
--rw=randwrite # IO pattern的类型,允许的值包括: read/write/randwrite/randread/rw/randrw,具体意义可以直接从字面看出来
--bs=4k # 每次IO的块大小,默认是4k,如果是带宽测试,建议至少1m
--size=100G # 文件大小,fio将会传输完整个文件大小,除非设置了运行时间runtime
--runtime=120 # 本次fio测试最多会运行这么长时间,和size共同决定fio运行的时间
--ioengine=libaio # 定义了job如何发送IO请求,本质上对应了不同的系统IO函数调用,常见的有sync/psync/libaio,新版本还有直接针对ceph的rbd
--iodepth=128 # IO深度,即同一时刻在途的IO个数,这个参数只在ioengine是异步的时候有用,如果是sync/psync,那么不管设多少只能是1
--numjobs=1 # Job的个数,即多进程运行fio,如果同时给出thread表示多线程运行
--filename=/dev/rbd0 # 如果指定filename,那么所有的job都会读写这个file,否则会根据name和numjobs启动生成file
--direct=1 # 如果是1,表示使用non-buffered IO,即读写均不经过本地内存
--norandommap # fio测试时会维护一张表来记着写过的地方,默认不会重复的写一块地方,添加此选项,会在任何块随机写,这样更接近业务情景。一般在随机读写的时候加这个参数
--randrepeat=0 # 设置产生的随机数是不可重复的,目的是增加读写的随机性
--group_reporting # 如果有多个job,不加这个参数就会单独显示每个job的输出,有这个参数就会汇总显示
# 测NAS带宽
fio --name=seqwrite --rw=write --bs=1M --size=5G --runtime=1200 --numjobs=20 --ioengine=libaio --iodepth=16 --direct=1 --group_reporting
以上简单的测试只是根据经验交付完的临时测试,机房的环境与客户现场是相当复杂的,通常环境也不是很好,但是搭建好集群后还是稍微坚持下花点时间进行简单的测试。
即便客户没有问到相关问题,但这样做首先是负责,其次将测试结果记录在案,方便后面自己与同事的维护工作。
标签:地址 生成 flush 模式 输出 自己 允许 硬件 策略
原文地址:https://www.cnblogs.com/tongh/p/13223995.html