标签:book pen item tps else open except -- load
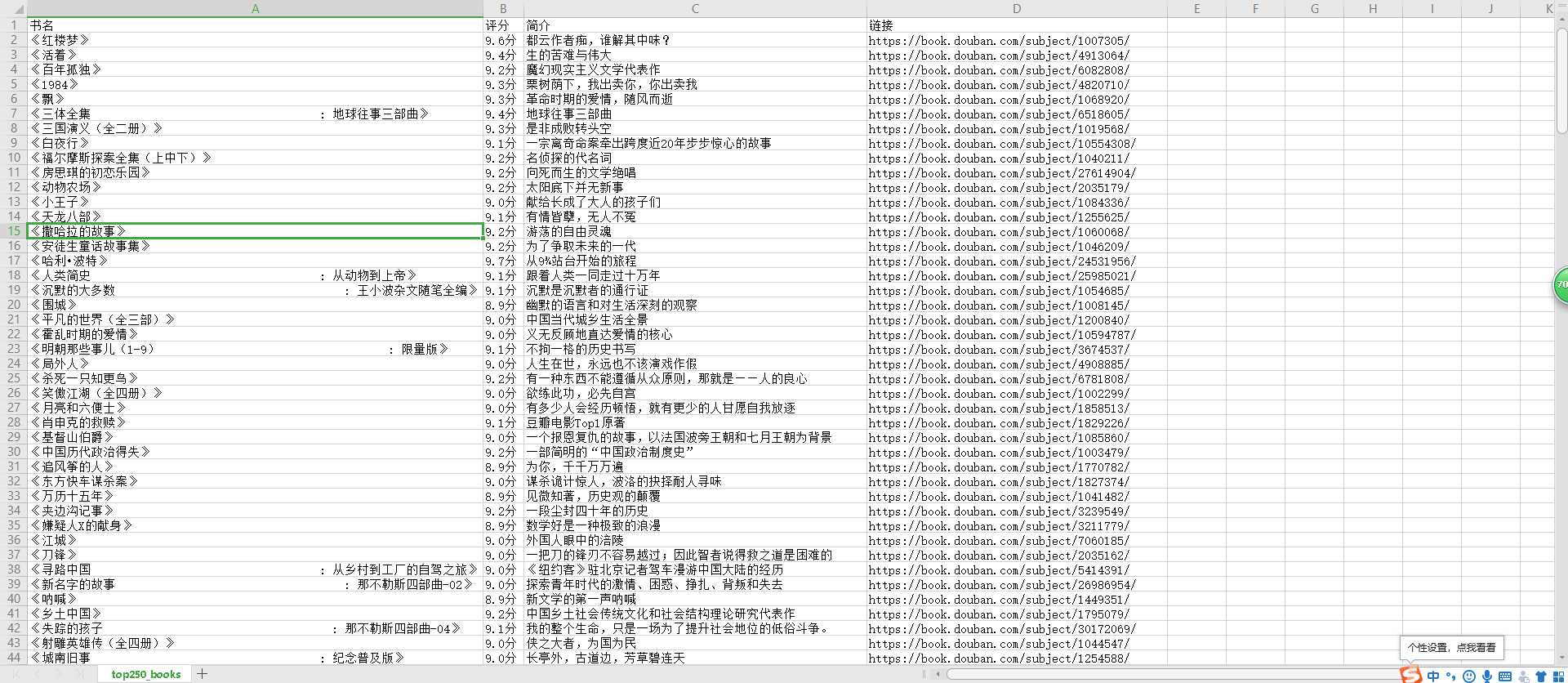
‘‘‘爬取豆瓣top250书籍‘‘‘ import requests import json import csv from bs4 import BeautifulSoup books = [] def book_name(url): headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘ } res = requests.get(url=url, headers=headers) html = res.text soup = BeautifulSoup(html, ‘html.parser‘) items = soup.find(‘div‘,attrs={‘class‘:‘grid-16-8 clearfix‘}).find(‘div‘,attrs={‘class‘:‘indent‘}).find_all(‘table‘) for i in items: book = [] title = i.find(‘div‘,attrs={‘class‘:‘pl2‘}).find(‘a‘) book.append(‘《‘ + title.text.replace(‘\n‘, ‘‘).strip() + ‘》‘) star = i.find(class_="star clearfix").find(class_="rating_nums") book.append(star.text + ‘分‘) try: brief = i.find(class_="quote").find(class_="inq") except AttributeError: book.append("~暂无简介~!") else: book.append(brief.text) link = i.find(class_="pl2").find(‘a‘)[‘href‘] book.append(link) global books books.append(book) print(book) try: next = soup.find(class_="paginator").find( class_="next").find(‘a‘)[‘href‘] # 翻到最后一页 except TypeError: return 0 else: return next next = ‘https://book.douban.com/top250?start=0&filter=‘ count = 0 while next != 0: count += 1 next = book_name(next) print(‘-----------以上是第‘+str(count)+‘页的内容-----------‘) csv_file=open(‘top250_books.csv‘,‘w‘,newline=‘‘,encoding=‘utf-8‘) w=csv.writer(csv_file) w.writerow([‘书名‘,‘评分‘,‘简介‘,‘链接‘]) for b in books: w.writerow(b)

标签:book pen item tps else open except -- load
原文地址:https://www.cnblogs.com/memory-ccy/p/13225055.html