标签:池化 例子 rgb loading lazy 最大的 isp different 内存
在介绍gumbel softmax之前,我们需要首先介绍一下什么是可微NAS。
可微NAS(Differentiable Neural Architecture Search, DNAS)是指以可微的方式搜索网络结构,比较经典的算法是DARTS,其算法示意图如下:
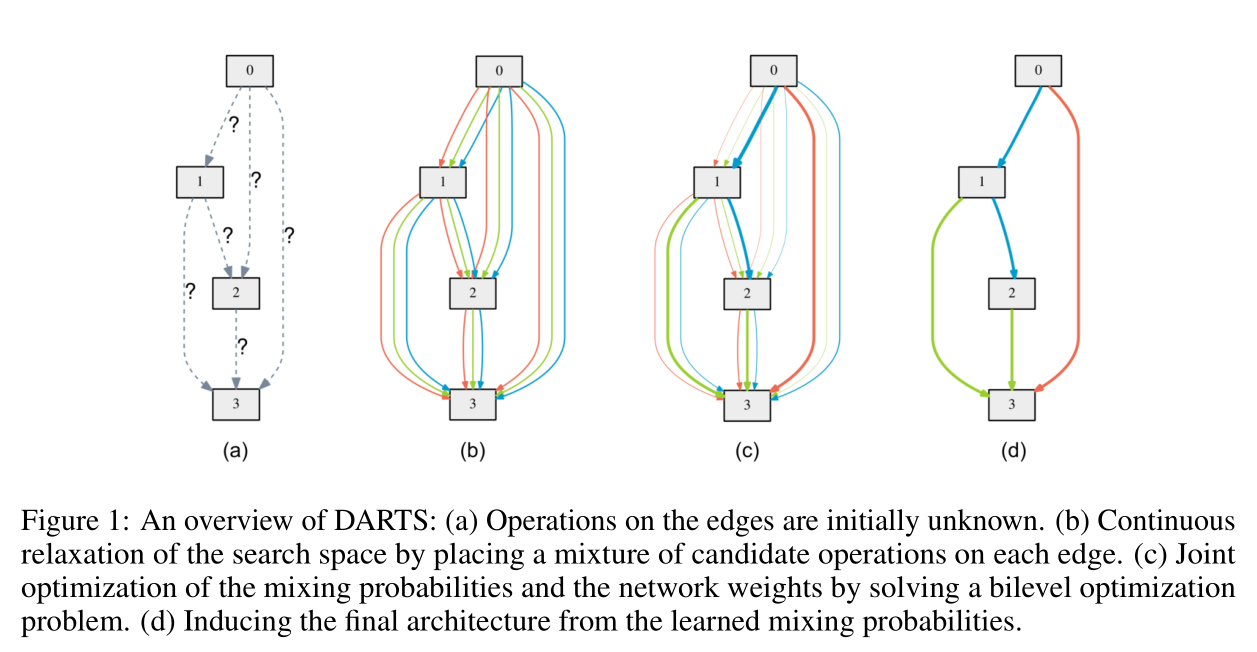
上图表示的是一个cell的结构。一个cell由若干个节点(node)组成,每组节点之间通过若干条边(edge)连接起来,每条edge表示不同的操作(用\(o\)表示),比如卷积或者池化操作等。DARTS的想法是每条edge都有一个权重(用\(\alpha\)表示),而且权重是可以通过梯度更新的,最后会根据权重来选择节点之间的操作,计算公式如下:
乍看起来好像挺好的,但是有一个问题。为方便讨论,我们仅讨论两个节点的情况,我们假设一共有3个候选操作,且三个操作的权重随机初始化为[0.2,0.3,0.5]。在经过一波训练后,权重得到了更新变成了[0.1,0.2,0.7],这表示第三个操作的可能效果更好,所以应该以更大的概率选择第三个操作。
可是DARTS算法在更新权重的过程中是并不是根据概率选择操作的,而是向上面的公式一样把所有操作乘上对应的权重得到mixed的结果,在权重更新结束后会简单地只保留每组节点之间权重最大的那个操作。这样一来有两个问题:
1)每次更新都是对所有操作进行更新,这导致内存消耗更大;
2)最后只是简单地选择权重最大的操作,那么[0.2,0.3,0.5]和[0.1,0.2,0.7]并没有本质的区别了,而且这样一来可能第一个和第二个操作根本就没有机会得到更新,但是从概率上来说这两个权重分布差别是巨大的。
所以一个很自然的想法就是我们希望以0.1的概率选择第一个操作,0.2的概率选择第二个操作,0.7的概率选择第三个操作。实现起来其实也挺简单的,直接用np.random.choice就可以按照一定概率随机选取操作。可是这样一来又产生了一个新的问题,即这种随机采样的方式没法计算梯度。
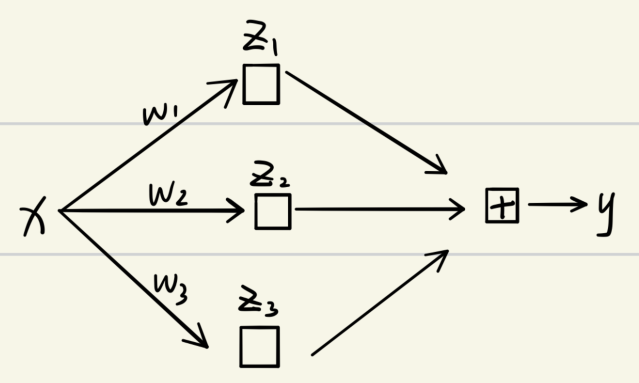
为什么没法计算梯度呢?我们考虑如下简单情况写一下表达式:
为了解决上面无法求导的问题,Gumbel softmax登场。它主要是使用了重参数技巧(Re-parameterization Trick)。
举个简单的栗子来帮助理解重参数技巧(gumbel softmax比这要稍微复杂一点,不过原理是一样的):
假设现在求得的权重分布是\(W=[0.1,0.2,0.7]\)。
然后再假设我们可以根据某种分布对每个权重采样一个随机值,比如三个权重对应的采样的随机值分别是\(\epsilon=[0.5,0.6,0.05]\),我们把这些随机值和权重相加之后得到\(\hat{W}=[0.1+0.5,0.2+0.6,0.7+0.05]=[0.6,0.8,0.75]\)。所以\(\hat{W}=W+\epsilon, \epsilon \thicksim P(某种分布)\),一般这个分布可以是0到1之间的均匀分布,即\(\epsilon \thicksim U(0,1)\)。
之后我们对采样随机值后的权重分布取\(argmax(\hat{W})\)的话应该是选择第二个操作,当然这种概率是比较小的,这个也叫Gumbel-Max trick。可是argmax也有无法求导的问题,因此可以使用softmax来代替,也就是Gumbel-Softmax trick,那么有如下计算公式(\(\tau\)表示温度系数,类似于知识蒸馏里的温度系数,也是用来控制分布的平滑度)
我们现在再来看看使用gumbel softmax后的求导表达式:
所以gumbel softmax成功地引入了随机性,使得每个操作都能以一定的概率被选中,不过貌似也并没有减少内存的消耗,因为还是和DARTS一样计算的mixed值。所以在GDAS这篇论文里作者在选择操作的时候使用的是argmax,而在更新权重的时候采用的是softmax的梯度值,这个可以通过修改pytorch的backward部分代码实现。
总结起来Gumbel-softmax在具体实践上和上面的例子有一丢丢不一样,总结起来步骤如下:
为什么gumbel-softmax技巧有效的证明可以参考如下文章
标签:池化 例子 rgb loading lazy 最大的 isp different 内存
原文地址:https://www.cnblogs.com/marsggbo/p/13227992.html