标签:最大 包含 附件 overlay tps page form 因此 ice
在刚刚结束的“2020虚拟开发人员和测试论坛”上,来自瞻博网络的工程师Kiran KN和同事,介绍了在Tungsten Fabric数据平面上完成的一组性能改进(由Intel DDP技术提供支持),以下为论坛技术分享的精华:在深入到DDP技术之前,首先介绍一下vRouter,它是什么,以及在整个Tungsten Fabric框架中的位置。
实际上,vRouter可以部署在常规X86服务器上,也可以在OpenStack或K8s的计算节点当中。vRouter是主要的数据平面组件,有两种部署的模式,分别是vRouter:kernel module,以及vRouter:DPDK模式。
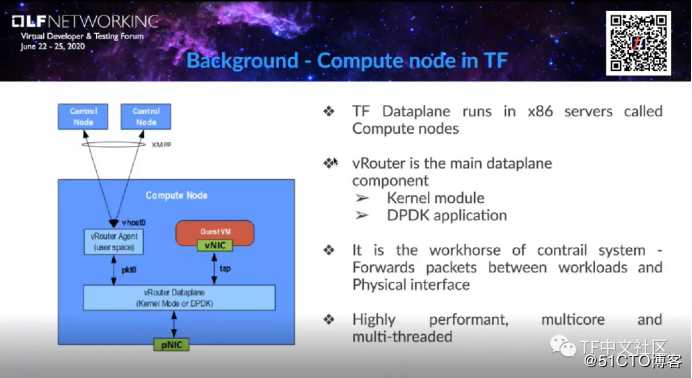
在用DPDK改善性能之前,此用例将涉及DPDK应用和vRouter。vRouter的职责是数据平面,用于数据包转发和由vRouter代理在计算节点上编程的数据包转发,但实际上,整个配置是通过控制器上的XMPP提供的。我们使用XMPP通过vRouter agent与控制器通信,并且有一个专门的接口来对vRouter数据平面进行编程以转发软件包。
在DPDK中,vRouter是一个高性能、多核和多线程的应用程序,这里想强调一下,它是专用于多核的DPDK应用,我们需要寻找多核的正确用法。
我们可以从示例中看到,网卡具有与vRouter相同数量的队列,已为数据包或链接分配了核心。
首先,数据包需要由网卡平均地分配到所有路由器转发核心。为此,使用了带有5元组哈希的算法,在所有内核之间正确分配流量。而且,适当的负载平衡是基于数据包的,并且要实现该数据包需要具有5元组,多个源的目标端口IP地址。如果该协议正确,则该协议可以确定所有内核之间的流量平均分配,并且我们可以利用它分配给vRouter DPDK的所有内核的性能。尽管此流量包分布在各个处理内核上,但可以通过TX接口队列,将它们适当地放置到虚拟机中。
如果此流量在各个内核之间没有得到适当的平衡,则vRouter将在没有内核的情况下进行重新平衡,但是对于内核来说,通过内核重新哈希化它们的代价很高,这意味着它们会消耗CPU周期并带来额外的延迟。
这就是我们面临的问题,但在今天得到了很大程度的解决,我们可以期待网卡能够完成此任务,并适当地平衡vRouter核心之间的流量。
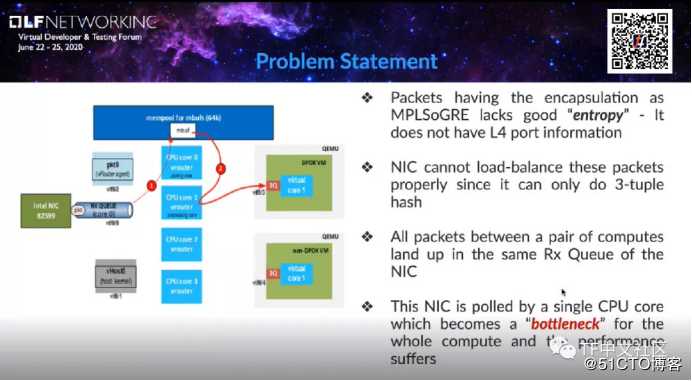
也就是说,具有MPLSoGRE的计算类型没有足够的熵(entropy)。由于熵的存在,我们的报头中没有足够的信息,或无法正确平衡数据包的负载。
具体来说,数据包应该具有完整的端口信息,包含完整的5个要素,即源IP、目标IP、源端口、目标端口和协议。但是在MPLSoGRE只有源IP、目标IP和协议三元组信息。因此,网卡无法适当地平衡数据包的负载,由于该CPU内核,一对计算节点之间的所有数据包都落在瓶颈中的同一区域,这将导致网卡队列成为整个计算的瓶颈,并且性能受到影响。
例如,假设一对计算节点之间有数千个流(flows)。理想情况下,我们希望将流平衡分布在所有的内核上,以便可以由不同的CPU将其拾取,以进行数据包处理。但是对于MPLSoGRE,已知端口的信息没有足够的熵,来自特定计算节点的所有数据包都会发生,即使有很多流量,网卡也不会将它们分发到所有队列。因此,这里不再像我们所知道的那样,实际上数据包不会像这样分散在多个内核中,它只会分配给一个内核。
因此,尽管有很多CPU内核,但由于所有数据包必须经过C1,C1本质上成为了瓶颈。数据包无法直接流经C2、C3、C4,是因为它们没有在硬件上加载,所有其它内核必须从C1获取数据包,显然C1将会过载。
我们为Tungsten Fabric数据平面引入了一项新功能,该功能消除了MPLSoGRE数据包的瓶颈,使得性能与CPU内核数成正比。这意味着没有单个CPU内核会成为瓶颈,并且网卡硬件将数据包平均分配给所有CPU内核。
我们的解决方案由Intel DDP(dynamic device personalization)技术提供支持,使用以太网700系列的产品来提供。英特尔转向可编程管线模型后,确保它们引入了诸如固件可升级之类的功能,DDP允许在运行时动态重新配置网卡中的数据包处理管道,而无需重启服务器。软件可以将自定义配置文件应用到网卡,我们可以将这些配置文件视为附件,可以由最终用户自己构建。这些配置文件可以通过软件刷新到网卡上,以便它们可以开始在线识别和分类新的数据包类型,并将这些数据包分配到不同的Rx队列。
这是MPLSoGRE实施的情况,首先是这是一个没有DDP提取功能的MPLSoGRE数据包,它没有获得在当前数据包中听到的内部实际存在的启动信息,因此它没有足够的信息来正确分配数据包。在第二个图例中启用了DDP,配置文件便可以开始识别内部数据包标头,以及内部IP标头和内部UDP标头,因此它可以开始使用该信息来计算哈希。
如何使DDP成为最终用户需要为其数据包类型创建配置文件的方式?
可以通过使用Intel的配置文件编辑器(profile editor)工具来创建,Intel在其上发布了一些标准配置文件,可以直接从Intel网站下载。配置文件编辑器可用于创建新条目,或者修改分析器的现有条目,这是第1步。第2步,为MPLSoGRE数据包创建一个新的配置文件,该配置文件在不同的层上定义数据包头的结构。第3步,是编译并创建一个二进制程序包,可以应用于网卡。第4步,我们可以使用DPDK API在每个工具接口将这些配置文件加载到网卡。接下来第5步,网卡就能够识别MPLSoGRE数据包。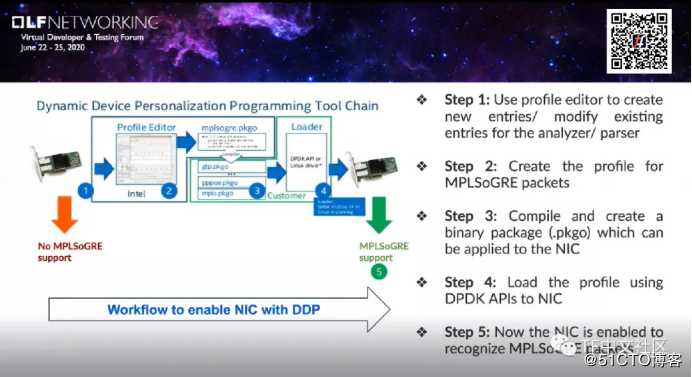
接下来,我们需要测试并确认,DDP可以提供帮助带来性能提升。
首先,我们的测试框架广泛用于开发和测试vRouter。我们使用代理方式以拥有快速概念验证的能力,并收集信息。测试vRouter性能的所有方法,包括封装和计算节点之间的封装,并且总是会包含overlay网络,就像在图例中的所看到的那样,我们通过第三个对象(rapid jump VM),该对象只有控制流量(不通过其它任何流量),向VM发送指令并收集信息。为了实现测试目标,我们采用丢包率只有0.001%的二进制搜索,使用标准的测试框架和规范。
在vRouter中,我们可以找到脚本,显示每个内核CPU数据包处理的统计信息,以证明网卡正确地集中了所有内核之间的流量。这些统计信息来自VM0接口,这意味着连接与物理网卡之间的接口。
在左侧,你可以看到内核1没有在处理软件包,这实际上意味着该内核未接收到任何由vRouter处理的软件包。此内核只是忙于轮询程序包,并在vRouter上的其它可用内核之间分配程序包。这意味着vRouter将成为瓶颈,因为首先需要将所有进入vRouter的流量从网卡队列中拉出,然后将其进行重新分配(跨其它核心)以转发到VM。
而在右侧,你可以看到使用DDP的网卡已经正确分配了流量,Rx队列中所有内核之间的流量几乎相等。证明网卡完成了自己工作,并平均分配了流量。
可以看到,是否使用DDP,在性能结果中统计数据上的差别。在不大于3个内核的情况下,使用DDP并没有得到任何好处——因为对于轮询内核和跨内核重新分配流量,目前网卡处理这样的队列还是足够快的。
但是一旦增加内核数量,然后提高整体性能,那么网卡就成为了瓶颈——在没有DDP的情况下性能不会提高,即使增加了内核数也是如此,因为总有一个内核在拉动流量,并且你可以看到,在没有DDP的部分中6.5mpps左右是一个内核从网卡队列中轮询的最大值。
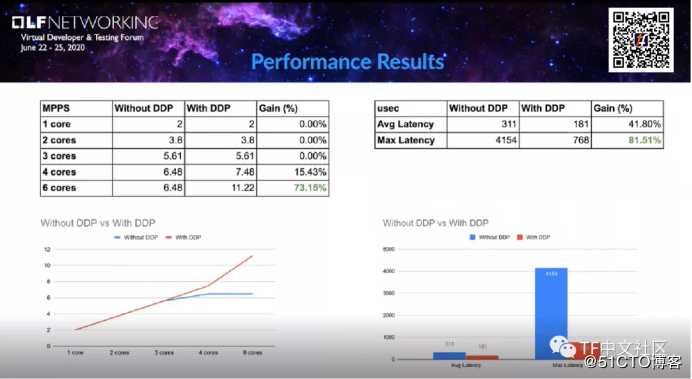
随着内核的数量增加,每个内核都从网卡接收了相同数量的流量。一旦内核数量超过6个,则收益将变得更高。正如我们所看到的,具有6个内核的增益大约为73%,这确实是个很酷的数字。不仅可以提高性能,使用DDP还可以得到更好的降低延迟。这是因为我们不需要平衡内核之间的流量,也不需要计算每个数据包的哈希值。在vRouter上,这将由网卡完成,收益的增加平均为40%,最多为80%,这已经是非常棒的数字了。
综上,对于拥有多个内核的用例,我们可以借助DDP技术获得很大的收益。另外,对于5G用例而言,DDP能够减少延迟这一点非常重要。在所有我们希望使用MPLSoGRE情况下,借助vRouter,我们已经准备好在多核中进行5G应用部署。
【本文相关资料pdf文档下载】
https://tungstenfabric.org.cn/assets/uploads/files/tf-vrouter-performance-improvements.pdf
【视频链接】
https://v.qq.com/x/page/j3108a4m1va.html


利用DDP技术提升Tungsten Fabric vRouter性能
标签:最大 包含 附件 overlay tps page form 因此 ice
原文地址:https://blog.51cto.com/14638699/2508275