标签:本地 source 提交 内存 技术 alt 分区 图片 mapreduce
工作流程1 Map Task
MR工作流程2 Reduce Task
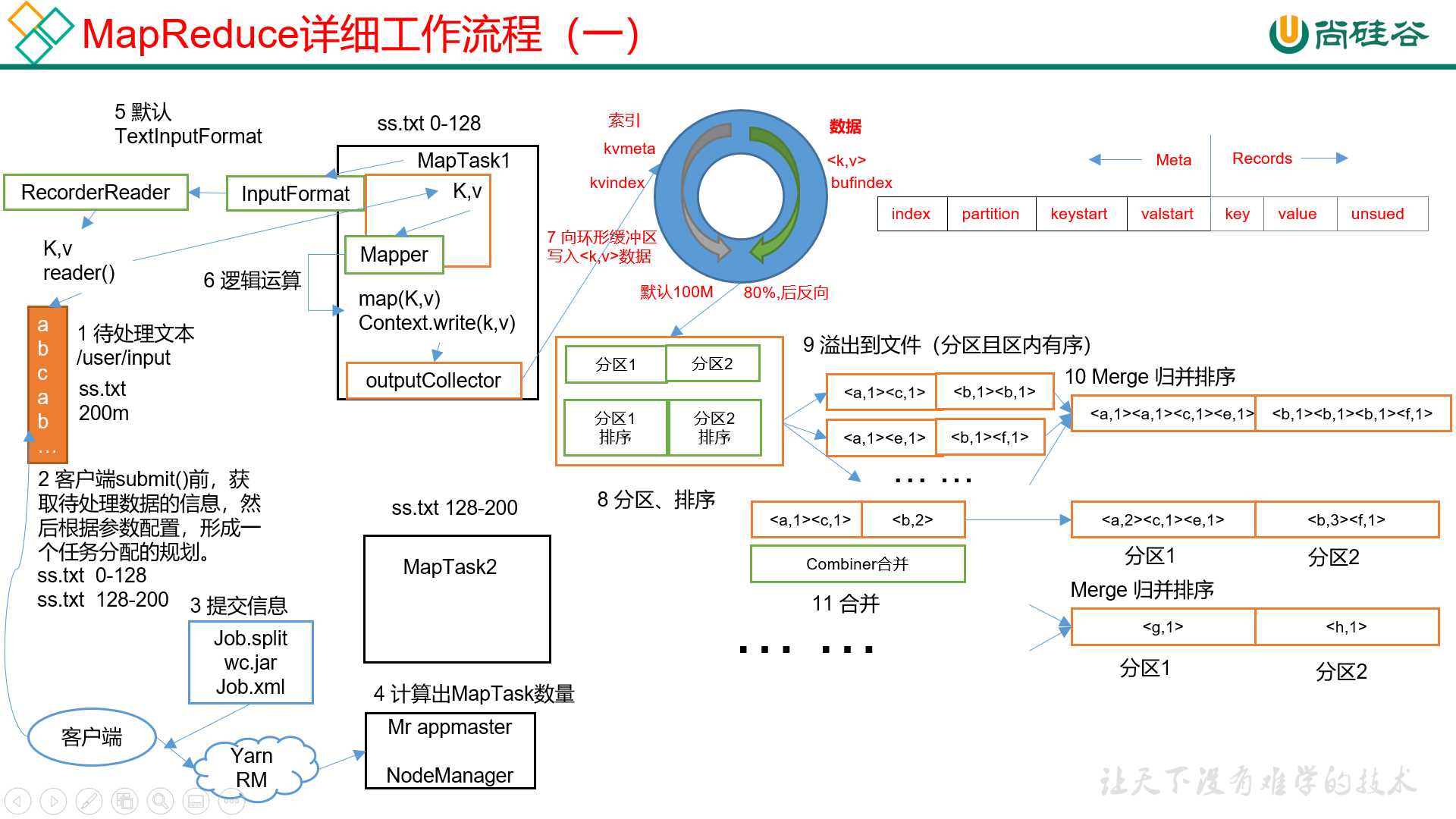
1)提交切片信息,jar包,和xml配置文件到yarn。
2)Yarn ResourceManager启动一个MR AppMaster。
3)AppMaster根据切片信息启动相应数量的Map Task。
4)Map Task取读取按照InputFormat去读取文件数据,交给map方法处理。
5)map方法处理完成后,将相应的kv数据写出到环形缓冲区。这个环形缓冲区默认100M,右边写实际数据(map方法输出的kv数据),左边写描述数据的索引。
6)当环形缓冲区写到80%时,将数据溢写到磁盘,然后开始反向写。在溢写之前,会先将数据进行区内排序。如果有多个溢写文件,每个分区的文件最终会归并成一个。
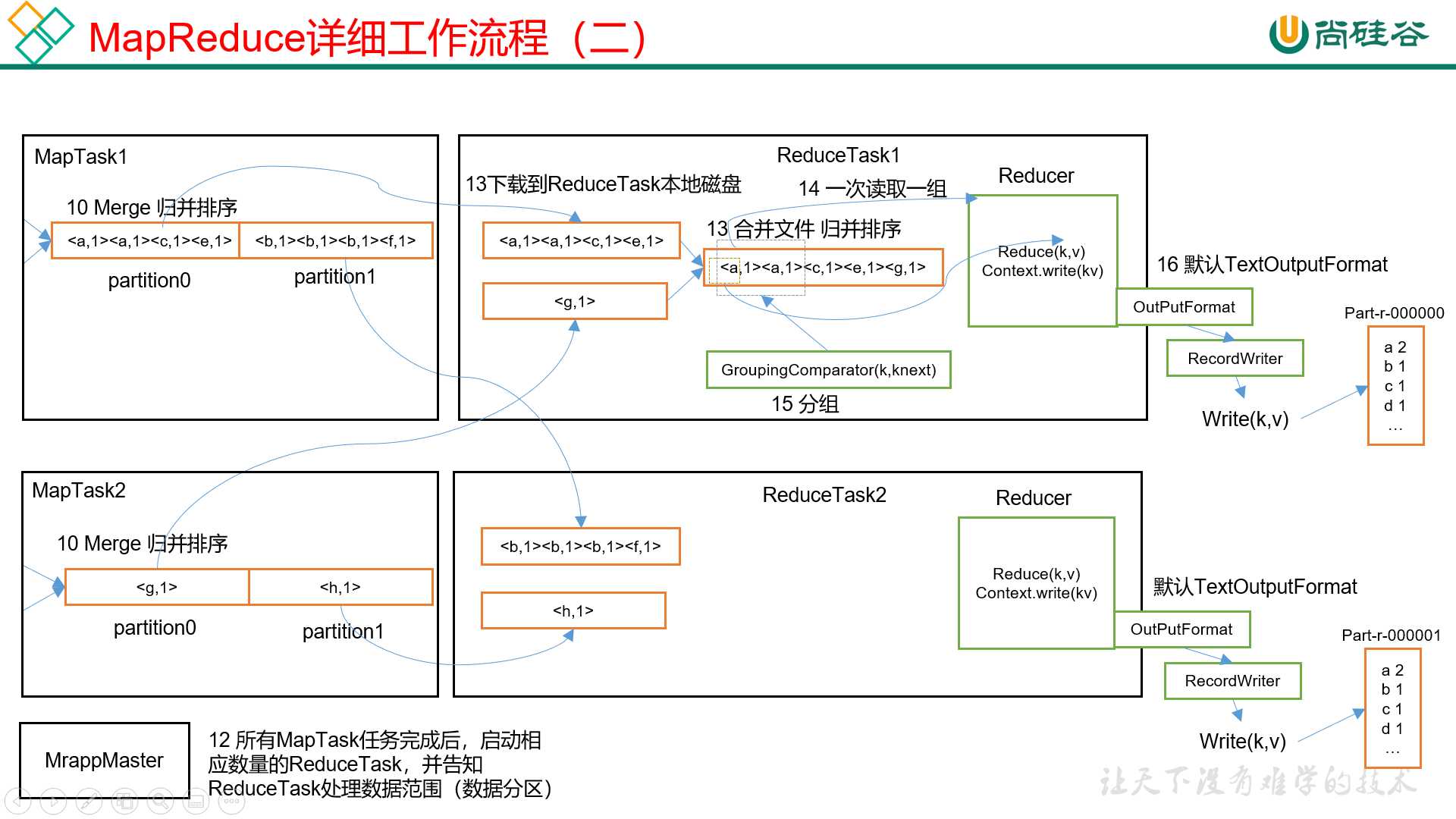
7)所有的Map Task完成后,AppMaster会根据分区数,启动相应的Reduce Task。
8)Reduce Task将多个Map Task的结果拷贝到本地,如果数据不大就放在内存,否则放在磁盘,并将多个文件进行归并排序。然后,相同Key的数据一起进入reduce方法,并将结果写出到文件。
其中map方法之后,reduce方法之前这段处理过程叫做shuffle。
标签:本地 source 提交 内存 技术 alt 分区 图片 mapreduce
原文地址:https://www.cnblogs.com/noyouth/p/13232975.html