标签:联合类 图表 content 规则 随机 lin inf std clu
首先工作经验告诉我们,定义结构体时,变量类型从小到大的顺序比较好,并且相同类型的变量尽量放一块。部分来自抄袭:
1、类
1、这是类为空的情况:
2、注意下面这种情况:
2、sizeof和strlen
sizeof():是运算符,在头文件中typedef为unsigned int,其值在编译时即计算好了,
参数可以是数组、指针、类型、对象、函数等。
功能是:获得保证能容纳实现所建立的最大对象的字节大小。
strlen():是函数,要在运行时才能计算。参数必须是字符型指针(char*)。当数组名作为参数传入时,
实际上数组就退化成指针了。
功能是:返回字符串的长度。该字符串可能是自己定义的,也可能是内存中随机的,该函数实际
完成的功能是从代表该字符串的第一个地址开始遍历,直到遇到结束符NULL。
返回的长度大小不包括NULL。
1、
char* ss = "0123456789";
sizeof(ss); //结果 4 ;
sizeof(*ss); //结果 1;*ss其实是获得了字符串的第一位‘0‘所占的内存空间;
strlen(ss); //结果是10 ;
char str[20] = "0123456789"
sizeof(str) = 20
strlen(str) = 10
char str[] = "abc\0"
strlen(str) = 3;
sizeof(str) = 5;
char*str="i am ok!"
sizeof(str)=4, 因为str是个指针变量,
sizeof("i am ok!")=9;这里有5个字符,2个空格,1个叹号,还有字符串的结束符‘/0‘;
2、
int *p = NULL; // sizeof(p)=4, sizeof(*p)=4
int a[100]; // sizeof(a)=400, sizeof(&a)=4 , sizeof(a[100])=4 , sizeof(&a[0])=4
int b[100];
void fun(int b[100])
{ sizeof(b); } // sizeof(b)=4
char (*pArray1)[4]={0}; sizof(pArrya1)=4,
char (*pArray2[10])[4]={0}; sizof(pArrya2)=40,
char (*pArray3[100])[4]={0}; sizof(pArrya3)=400
3、
int *p=malloc(100); // sizeof(p) = 4 sizeof(p) 只能测定 指针大小,32位机上得4。
sizeof 不能测定动态分配的数组大小
int b[ ][3] = {{1},{3,2},{4,5,6},{0}};中,sizeof(b) = 48
3、字节对齐
对齐规则说起来太麻烦,直接用图表示,一眼就懂。
默认情况下4字节对齐
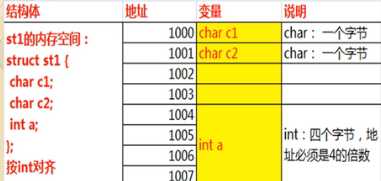
1
1
4
=8
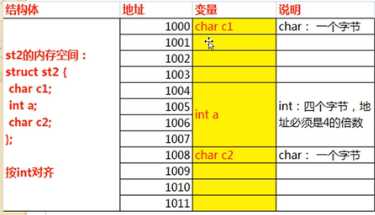
1
4
1
=12
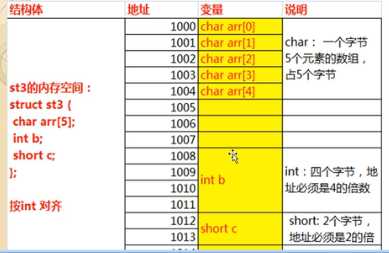
5
4
2
=16

1
8
1
=24
好了,举例够多了,,,
另外,#pargma pack(n)表示约定n字节对齐,这个一般很少用。
4、大小端
提到字节对齐,就没道理不说大小端。
大端:较高的有效字节存放在较低的存储器地址,较低的有效字节存放在较高的存储器地址。
小端:较高的有效字节存放在较高的的存储器地址,较低的有效字节存放在较低的存储器地址。
假设从内存地址0x0000开始有以下数据:
内存地址:0x0000 0x0001 0x0002 0x0003
对应数据:0x12 0x34 0x56 0x78
如果我们去读取一个地址为0x0000的4字节变量
若字节序位为小端模式,读出为:0x78563412
若字节序位为大端模式,读出为:0x12345678
一般来说:X86系列的CPU都是小端字节序,powerPC通常是大端字节序。
int _tmain(int argc, _TCHAR* argv[])
{
char *sz = "0123456789";
int *p = (int *)sz;
cout<<hex<<*++p<<endl;
}
运行结果为:37363534
分析:这里是小端字节序
地址从0x0000开始,那么sz在内存中的存储为:
内存地址: 0x00 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x09
对应的值: 0 1 2 3 4 5 6 7 8 9
对应的值: 48 49 50 51 52 53 54 55 56 57
对应的16进制:0x30 0x31 0x32 0x33 0x34 0x35 0x36 0x37 0x38 0x39
sz ++p
所以读取为:0x37363534。
那么,给你一个系统,怎么知道它是大端还是小端呢?
判断方法一:利用联合类型判断
union类型的主要特点如下:
union中可以定义多个成员,union的大小由最大的成员的大小决定;
union成员共享同一块大小的内存,一次只能使用其中的一个成员;
对某一个成员赋值,会覆盖其他成员的值;
联合体union的存放顺序是所有成员都从低地址开始存放。
所以我们可以定义联合体如下:
//method 1
union bit
{ //对齐原则,char与int指向的均是低位地址
int a;
char b;
};
这个时候我们赋值 a = 0x12345678,如果低位字节的b存放的是0x78,则说明是小端模式,若为0x12则为大端模式:
#include <stdio.h>
union bit{//对齐原则,char与int指向的均是低位地址
int a;
char b;
};
int main(){
bit test;
test.a = 0x12345678;
if(test.b == 0x78) //如果低位地址保存的是1,即低位字节在低位地址,为小端
printf("本机为小端模式\n");
else
printf("本机为大端模式\n");
return 0;
}
判断方法二:利用强制类型转换判断
这种方式需要定义一个字节指针,指向int型的低位地址,因为要用到强制类型转换,故而称为利用强制类型转换的判断方法:
//method 2
void judge(void)
{
int i = 0x12345678;
char *p;
p = (char *)&i; //强制类型转换成char*型指针,指向的位置为低位地址
if(*p == 0x78) //低位地址存储的是低位字节,则为小端
printf("本机为小端模式\n");
else
printf("本机为大端模式\n");
}
其实,知道了也没用!
字节对齐
标签:联合类 图表 content 规则 随机 lin inf std clu
原文地址:https://www.cnblogs.com/fangzheng-nie/p/13233043.html

