标签:测试 com 直接 计算 inf 图片 做了 转化 关系
生日悖论: 是指在不少于 23 个人中至少有两人生日相同的概率大于 50%。例如在一个 30 人的小学班级中,存在两人生日相同的概率为 70%。对于 60 人的大班,这种概率要大于 99%。从引起逻辑矛盾的角度来说,生日悖论并不是一种 “悖论”。但这个数学事实十分反直觉,故称之为一个悖论。
生日悖论是有个有趣的概念,但这和我省上百G的内存有什么关系?
首先介绍下背景,工作中我负责了一个广告数据系统,其中一个功能就是对同一次请求的广告曝光去重,因为我们只需要知道这次请求这个广告的一次曝光就行了,那些同一次请求产生的重复曝光记录下来没有意义,而且还耗会增加我们的存储成本。所以这里就需要有个逻辑去判断每条新到的曝光是否只之前已经记录过的,旧的方案是在redis中存储请求唯一标识(uuid)和广告ID(adid),每次数据过来我们就看redis里有没有uuid+adid这个key,有就过滤掉,没有就不过滤并在redis记录下来已出现。
问题就来了,redis记录的这份数很大(两天数据超过400G),而且随着我们业务的增长,我们的Redis集群快盛不下了…… 当然花钱加机器是最简单的方式,毕竟能用钱解决的问题都不是问题。而优秀的我,为了替公司省钱,走了优化的路。
首先可以肯定的是数据条数不会少,因为业务量就在那里,所以减少数据量的这条路肯定行不通。那是否可以减少每条数据的长度呢?
我们再来看下redis存储的设计,如下图:

这样下来一条记录总共用了45个字节,这个长度能不能缩短? 当然能,我们可以截取部分UUID,但这样又带来一个新的问题,截取UUID会增加重复的概率,所以首先搞清楚怎么截取,截多少?
这里我们用的是随机UUID,这个版本中有效二进制位是122个,所以总共有$2^{122}$个有效的UUID。 因为是随机产生的所以肯定有重复的概率,UUID重复的概率有多少? 要算这个重复概率,光有$2^{122}$这个总数还不行,还得知道你拥有的UUID个数。 我把这个问题具体下,求:在$2^{36}$个UUID中有重复的概率是多少?
$$
p(n) \approx 1-e{-\frac{n{2}}{2 x}}
$$
这不就是生日悖论的数据放大版吗? 当然这个概率可以根据上面公式计算,其中x是UUID的总数$2{122}$,n是$2{36}$,引用百度百科的数据,概率为$4 *10^{-16}$ 这比你出门被陨石撞的概率还小很多。
| n | 几率 |
|---|---|
| 2^36 | 4 x 10^-16 |
| 2^41 | 4 x 10^-13 |
| 2^46 | 4 x 10^-10 |
另外,从上面的公式也可以看出,在n固定的时候,随着有效二进制位的减少,概率p就会增加。 回到我们广告去重的场景下,每天最大请求数n是基本固定的,而且我们也可以忍受一个较小的概率p(小于万分之一),然后就可以反推出这个x有多大。
其实只要$\frac{n^{2}}{2 x} < 0.0001$,p就会小于万分之一。我可以从历史数中统计出n的大小,然后计算出x,再留一定的buff,然后根据n的大小重新设计了redis的key。(因为涉及公司数据,这里不公布中间计算过程)
最终有效位我选取了40个有效二进制位(10个16进制位),但我并没有直接截取UUID的前10位,因为UUID的前几位和时间有关,随机性并不强。我选择将整个UUID重新md5散列,然后截取md5的前10位,然后拼接adId形成最终的key,如下图:
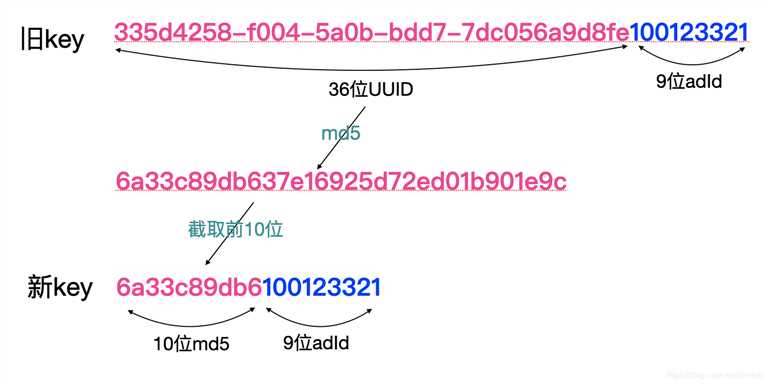
明显看出,key的长度缩小了一半,总体上能节省至少50%的存储空间。备注:但其实我们redis的具体存储实现和上文描述略有差异,为了不喧宾夺主上文特意对实际实现做了简化描述,所以最终实际没有省一半以上的内存,只省了35%左右。
实际优化就到这了,但其实还是不够极致,其实adId中也包含大量的冗余信息也可以截取,其实我们可以承受更高的重复率,其实我们可以把redis数据存储时间设的更短一些……
上面几种方法都可以进一步优化,但存储空间不会有量级级别的减少,而下面一种方式,可以将存储空间减小99%以上。
关于布隆过滤器的原理,可以参考我之前写的一篇文章布隆过滤器(BloomFilter)原理 实现和性能测试。 布隆过滤器完全就是为了去重场景设计的,保守估计我们广告去重的场景切到布隆过滤器,至少节省90%的内存。
那为什么我没有用布隆过滤器,其实还是因为实现复杂。redis在4.0后支持模块,其中有人就开发设计了布隆过滤器的模块RedisBloom,但无奈我们用的redis 还是3.x版本 !我也考虑过应用端基于redis去实现布隆过滤器,但我们应用端是个集群,需要解决一些分布式数据一致性的问题,作罢。
其实我们redis的具体存储实现和上文描述略有差异,为了不喧宾夺主上文特意对实际实现做了简化描述,所以最终实际没有省一半以上的内存,只省了35%左右。
最终400G+优化后能减少100多G的内存,其实也就是一台服务器,即便放到未来也就是少扩容几台服务器。对公司而言就是每个月节省几千的成本,我司这种大厂其实是不会在乎这点钱的。不过即便这几千的成本最终不会转化成我的工资或者奖金,但像这种优化该做还是得做。如果每个人都本着 用最低的成本做同样事 的原则去做好每一件事,就我司这体量,一个月上千万的成本还是能省下来的。
标签:测试 com 直接 计算 inf 图片 做了 转化 关系
原文地址:https://www.cnblogs.com/xindoo/p/13234720.html