标签:ima 算法 mysq java 终端 leetcode info push list
树是学习数据结构的时候非常重要的一个数据结构,尤其是二叉树更为重要。像Java的HashMap
就使用了红黑树,而Mysql的索引就使用到了B+树。恰好最近刷leetcode碰到了不少的有关
二叉树的题目,今天想着写个总结。
树(Tree)是n(n>=0)个优先数据元素的结合。当n=0时,这棵树称之为空树,在一棵非空树T中:
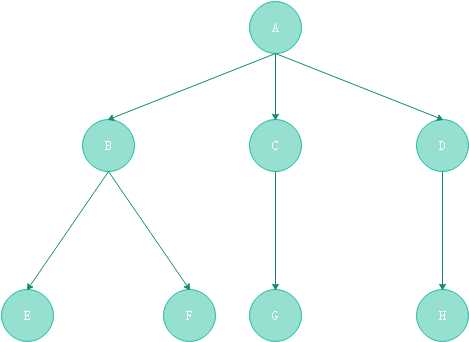
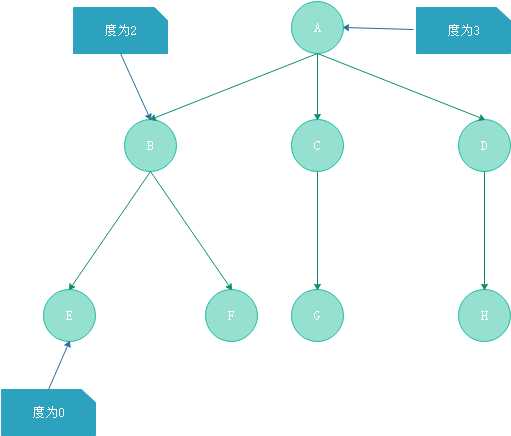
二叉树指书中节点的度不大于2的有序树,是一种最简单且最重要的树。
递归定义:二叉树是一棵空树或者是一颗由一个根节点和两颗互不相交二叉树组成的非空树。
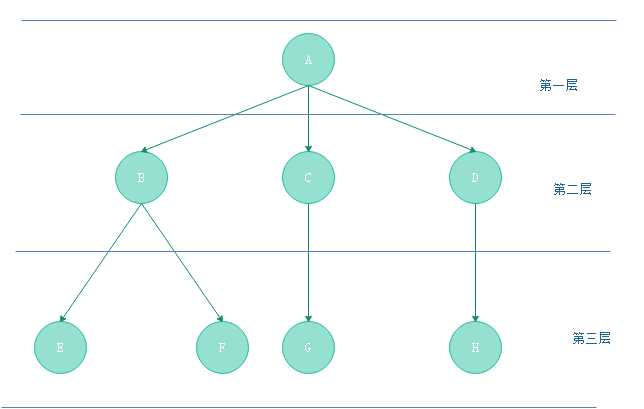
特点:
- 每个节点最多由两棵子树,所以二叉树中不存在度大于2的节点
- 左子树和有子树是有顺序的,次序不能任意颠倒
- 即使树中某节点只有一颗子树,也要区分他是左子树还是右子树
有关二叉树的一些概念:
- 二叉树的深度:树种节点的最大层数称之为树的深度。
- 满二叉树:如果一个二叉树每一层的节点数都到达了最大,这颗二叉树就称作满二叉树。
对于满二叉树,所有的分支节点都存在左子树和右子树,所有的叶结点都在同一层(最下面一层)。图(2-2)就是一颗满二叉树- 完全二叉树:一颗深度为k的有那个节点的二叉树,对其节点按照从上至下,从左至右的顺序进行编号,如果编号i(1<=i<=n) 的节点与满二叉树种编号为i的节点在二叉树种的位置相同,则这棵二叉树称之为完全二叉树。完全二叉树的特点是:叶子节点只能出现在最下层 和次最下层,且下层的叶子节点集中在左侧。一棵慢二叉树必然是一颗完全二叉树,而完全二叉树未必是满二叉树。 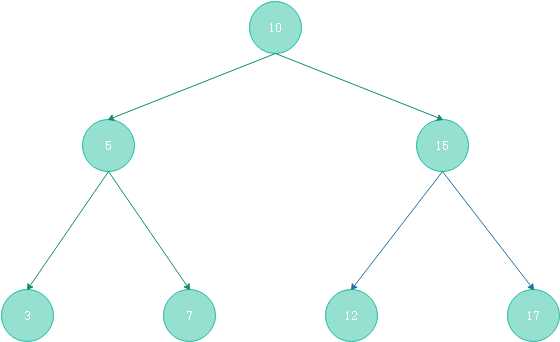
图(2-2) 满二叉树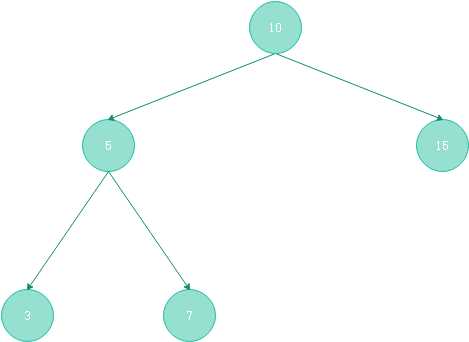
图(2-3) 完全二叉树
- 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
- 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
- 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
二叉树的遍历是指从二叉树的根结点出发,按照某种次序一次访问二叉树中所有的节点,使得每个节点被访问且仅访问一次。
二叉树的访问次序可以分为四种:
节点定义:这里先将后续代码实例的节点进行定义,节点的结构如下:
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int x){
this.val=x;
}
}
根据前面说的,访问顺序:父节点——>左子树——>右子树。那么对于图(2-2)所示的满二叉树
则有以下访问顺序:
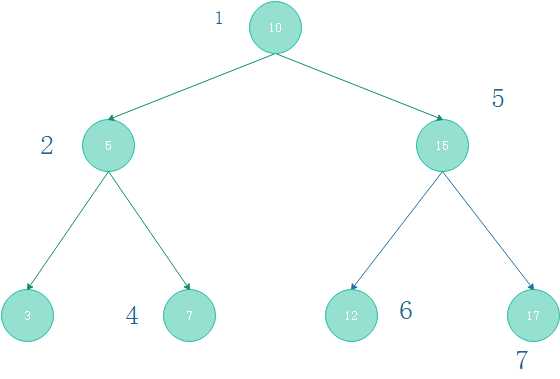
public void preorderTraversal(TreeNode root){
if(root==null) return;
//先访问根节点
System.out.println(root.val);
//访问左子树
preorderTraversal(root.left);
//访问右子树
preorderTraversal(root.left);
}
考虑,本着一个节点访问一次的原则,则访问一个节点的时候 除了将自身的值输出,还需要将两个子节点加入到栈中。
访问两个子树的时候需先访问左子树,在访问有子树,因此应该先将右孩子入栈(如果有),再将左孩子入栈(如果有)。
然后再将节点出栈重复这个动作。直到栈为空。
public void preorderTraversal(TreeNode root){
if(root==null) return;
Stack<TreeNode> stack=new Stack<TreeNode>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node=stack.pop();
System.out.println(node.val);
if(node.right!=null){
stack.push(node.right);
}
if(node.left!=null){
stack.push(node.left);
}
}
}
根据前面说的,访问顺序:左子树——>父节点——>右子树。那么对于图(2-2)所示的满二叉树
则有以下访问顺序:
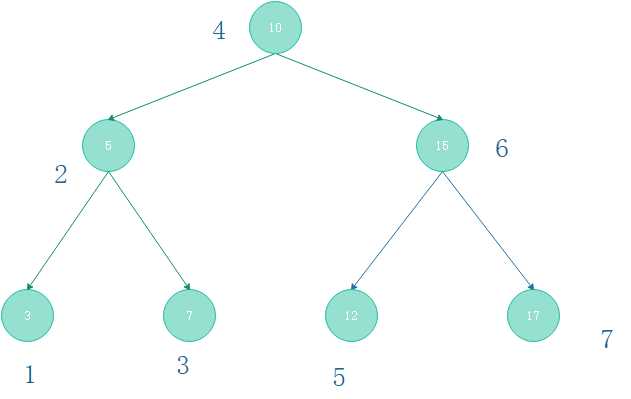
public void middleTraversal(TreeNode root){
if(root==null) return;
middleTraversal(root.left);
System.out.println(root.val);
System.out.println(root.right);
}
首先访问的顺序是左子树——>父节点——>右子树,我们有的线索就是一个根节点,需要先找到左子树的最左边的节点输出(图(3-2)中的3),
然后输出父节点,再输出右节点,如果沿着最左边的路径全部入栈,那么从栈中弹出的第一个元素就是我们的第一个元素,现在栈顶的元素就是输出的元素的父节点。
输出,父节点已经有了就可以获取到右子树,右子树的根节点入栈,重复这样的动作,代码如下:
public void middleTraversal(TreeNode root){
if(root==null) return;
Stack<TreeNode> stack=new Stack<>();
TreeNode node=root;
while (node!=null||!stack.isEmpty()){
while (node!=null){
stack.push(node);
node=node.left;
}
node=stack.pop();
System.out.println(node.val);
node=node.right;
}
}
根据前面说的,访问顺序:左子树——>右子树——>父节点。那么对于图(2-2)所示的满二叉树
则有以下访问顺序:
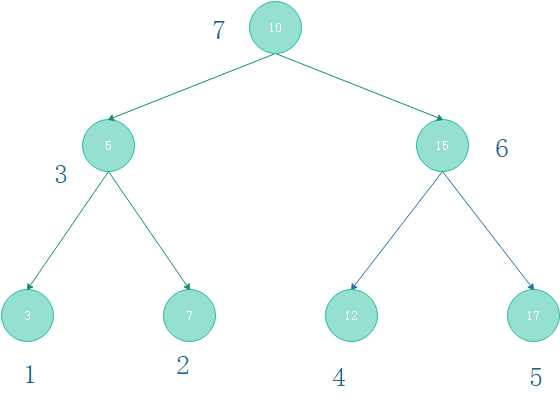
1)使用递归遍历
public void postorderTraversal(TreeNode root){
if (root==null) return;
postorderTraversal(root.left);
postorderTraversal(root.right);
System.out.println(root.val);
}
public List<Integer> postorderTraversalUseStack(TreeNode root){
if (root==null) return new LinkedList<Integer>();
Stack<TreeNode> stack=new Stack<>();
//因为这种办法访问的结果是反序的
//因此这里使用了一个链表,目的是在头部插入数据
//这样得到的结果就是目标结果
//也可以使用ArrayList,再循环反序。
LinkedList<Integer> res=new LinkedList<>();
stack.push(root);
TreeNode node;
while (!stack.isEmpty()){
node=stack.pop();
res.addFirst(node.val);
//因为要得到的结果是左-右,压栈的时候如果是正序是应该先右再左
//但是访问的结果是反的,所以是先左后右
if(node.left!=null){
stack.push(node.left);
}
if(node.right!=null){
stack.push(node.right);
}
}
return res;
}
层序遍历会比简单,只要使用一个队列,计算每层的长度,便利的时候按照左孩子,右孩子的顺序入队即可
public void levelOrder(TreeNode root){
if(root==null) return;
Queue<TreeNode> queue=new LinkedList<TreeNode>();
queue.add(root);
TreeNode node;
while (queue.size()!=0){
int len=queue.size();
for (int i=0;i<len;i++){
node=queue.poll();
System.out.println(node.val);
if(node.left!=null){
queue.add(node.left);
}
if (node.right!=null){
queue.add(node.right);
}
}
}
}
本文简单介绍了树的概念与性质,重点介绍了二叉树的几种遍历方式,尽管递归遍历很简答,但是手写还是会写错,而且一般会要求通过迭代来完成。
刚才又看到了新的套路,jvm中的迭代的本质就是压栈和弹栈,然后可以把递归转化为迭代。后面还有很多种树的遍历方式。多多学习吧,希望自己能进个大厂喽。
标签:ima 算法 mysq java 终端 leetcode info push list
原文地址:https://www.cnblogs.com/bmilk/p/13236268.html