标签:标签 http 中间 hello 如何 制表符 情况 index 单行注释
? + *
// 匹配标签: 以<开头,以>结尾,且中间不能出现 >, 且<>中间必须有内容。如<div>
/<[^>]+>/
// 匹配开始标签:除了满足以上条件外,还要保证 < 后买不能有/; >前面不能有/
/<[^/>][^>]*>/ // 考虑到属性中可能含有 /; 比如: <a href="http://baidu.com">百度</a>
// 因为[^/]本身就占了一个字符,所以[^>]量化范围必须从0开始 ---疑问: 这种匹配可能出现自闭合:就加一个或运算/<[^/>][^>]*><[^/>]|[^>/]/。 分为两种情况判断:标签只含有单字母的标签名,没有属性;<>中间包含多个字符。 其实实际应用中,没有必要总是要求匹配的那么严格
// 匹配自闭合标签
/<[^>/][^>]*/>/
// 匹配结尾标签
/</[^>/]+>/
常用正则方法
任意符:.
滥用.的问题
// 比如我们用/"[^"]*"/匹配双引号字符串,如果换成贪图简便换成 /".*"/就会出现这样的匹配问题
"double quate" is me " 也符合要求
忽略优先量词
回溯:
下图是用".*"匹配"qouted string"的过程;字符串末尾的",.*可以匹配他,也可以不匹配,但使用的匹配量词优先,所以.*先匹配",并记录下这个状态。但这时字符串已经结束了,但正则中还没有匹配到",所以只能查询之前保留的备用状态,看能不能退回几步,照顾"的匹配;就是下面的回溯过程

忽略量词优先: ?
// 要求匹配整个script标签以及其中的内容
<script type="text/javascript"> ...</script>
// 方式一:
/<script type="text/javascript">[\s\S]*</script> /
// 会存在一个问题,如果存在多个script标签的话,就会匹配所有的scripr标签,如:会匹配下面所有内容,直到后面再不i出现</script>
<script type="text/javascript"> alert(0)</script>
<div>我是一个div</div>
<script type="text/javascript"> alert(1)</script>
// 方式二:
/<script type="text/javascript">[\s\S]*?</script> /
忽略优先量词和匹配优先量词逐一对应,只是在对应的匹配优先两次后面添加?,两个限定的元素能出现的次数也一样,遇到不匹配的情况也同样需要回溯:唯一的区别在于忽略优先量词会优先选择忽略,如果后面的//不能匹配,再回溯回来,尝试匹配。而匹配优先量词会优先‘选择’</script>,如果一直到字符串结尾都没有</script>,就会把选择的</script>交由//
总结:忽略优先量词将匹配的优先级交给它后面的正则,后面如果对上了就属于后面,后面对不上自己再尝试对;
? 匹配优先量词将匹配的优先级交给自己,自己先对完,发现后面如果对不上了再来回溯自己,看退几步后面能不能对上

/[a-z]+?[a-z]/ // 只匹配 ‘asd‘中的 ‘as‘。+必须满足匹配字符至少出现一次; ?将匹配权限先交给后面的匹配; +?:他前面的字符组先匹配最低值一个后,将选择权交给后面的[a-z],如果[a-z]匹配到了,这个匹配过程就结束了;如果[a-z]匹配不到,再将匹配权交给[a-z]+?; 比如:/[a-z1-9]+?[a-z]/ 可以匹配 ‘a123sa’中的 ‘a123s‘
```
疑问:
/[a-z]+?[a-z]/.test(‘asd‘) 和 /[a-z]+?[a-z]/.test(‘as‘) 返回的都是 true;那 +? 的具体应用场景是什么?
忽略优先运算符的特点不是体现在这里;当匹配到字符符合[a-z],后面再出现符合要求的字符就不会再匹配了;举个容易理解的例子:/[a-z1-9]+?123/。在用test()测试字符串‘adf123‘和‘wqe123fsgfgw123‘结果返回的都是 true; 但再提取字符串的字串的时候/[a-z1-9]+?123/和/[a-z1-9]+123/会有不一样的结果
??和?有什么区别
提取c语言中的注释
// 正则匹配规则不一定要准确到可以精准匹配到每种可能存在额的情况,想下面提到的字符串中可能出现 ‘注释符‘,这种几率少之又少,为它在浪费时间写逻辑实在不划算
const cCode = `
int a = 2, b = 3, c;
char arr = []
/* c = a + b; // 我是一个行内注释
c = c*c */
function (a, b) { // 将求两数之和封装成一个函数
return a + b
}
// 这是一个for循环
/*
for (var i = 0; i < arr.length; i ++) {
// 进行一些操作吧
}
*/
`
// 单行注释 + 多行注释(可能多行注释里面嵌套有单行注释或者`//`这样的符号)
// 字符串中可能存在 ‘//‘ 或者 `/*` 或者 ‘/*‘的问题: 暂不考虑
// 避免多行注释里嵌套单行注释,先提取多行注释
var regMulti = /\/\*[\s\S]*?\*\//g
var regSingle = /\/\/.*/g
var multiArr = cCode.match(regMulti) // 是一个数组, 存放多行注释
var codeExceptMul = cCode.replace(regMulti, ‘‘)
var singleArr = codeExceptMul.match(regSingle) // 是一个数组, 存放单行注释
提取html中所有a标签的超链接
const html = `<a href="http://baidu.com?name=tina"></a>
<a href="http://baidu.com#index"></a>`
// 提取所有a标签中的超链接
const reg = /(?<=<a[^>]+href=")[\w#?=\-:\/\.]*(?="[^>]*>[\s\S]*<\/a>)/g
console.log(html.match(reg))
// 疑问:如何以字符串的形式获取页面的元素
// 解决方式二: 不用正则,直接遍历document.body对象,获取里面所有的a标签的href属性值
字符串的与正则有关的方法
str.search(reg/string): 检索字符串中与正则/子字符串匹配的第一个子字符串的下标
str.match(reg/string): 查找一个或者多个正则表达式/子字符串的匹配。如果正则结尾加上 g可以查找并返回所有符合匹配条件的字串;结尾不加g,只能查找第一个符合条件的字串,并返回字串和子串中符合条件的分组
str.repace(reg/string, newString):将字符串中特定的或者符合正则匹配的子串(第一个参数),替换成别的字符串(第二个参数)。这个方法会返回替换后的新字符串,并不改变原来的字符串。
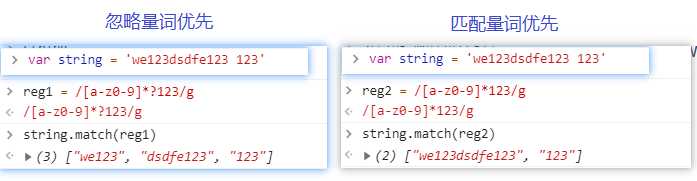
var string = ‘we123dsdfe123 123‘
var reg1 = /[a-z]*?123/g
var reg2 = /[a-z]*123/g
string.replace(reg1, ‘hello ‘) // "hello hello hello "
string.replace(reg1, ‘hello ‘) // "hello hello "
改造匹配