标签:换行 是什么 换行符 条件 疑问 exp 撒旦 高亮 字符串
断言:正则中大部分匹配都是匹配文本的,会出现在最终的匹配结果中。但有些结构只负责位置匹配(左边、右边、开始和结尾),不真正匹配文本,这种结构称为断言。常见的三种断言:单词边界、行起始/行结束、环视。
\b作用:匹配一边是单词字符,一边不是单词字符(不分左右)。在js中,\w就可以匹配单词字符,其它语言不管。比如用/\b\w+\b/就能匹配一个单词
例子1:使用单词边界,给<tag class="name"></tag>的开始标签和结束标签名标记高亮(改变颜色)
例子2:借助单词边界匹配一段英文字符信件中的所有名字(自己网上搜索)
js中^、$只匹配单行。所以只需要记住:^匹配字符串的开始位置,$匹配字符串的结束位置,其他们本身不保存匹配结果。如果想了解更多请看【第四章第二节】
疑问:在字符串中\n算是字符还是换行符 ---普通字符
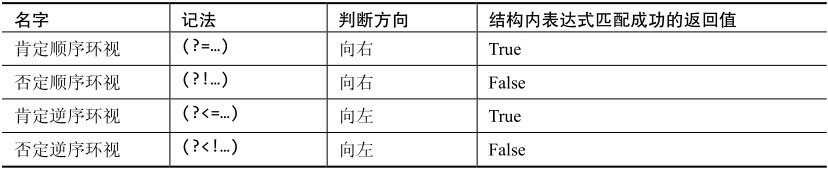
匹配某个位置的左边或者右边,看是否满足匹配条件,但不保存匹配结果。环视分为以下四种
更详细的理解,请看6/8日笔记,前瞻、后顾、负前瞻和负后顾
// 前瞻
exp1(?=exp2) //匹配exp1, 且必须满足条件exp1后面必须是exp2; 比如: /中国(?=人)/ 将匹配‘中国人’中的 ‘中国’。就像/^a/ 匹配字符串a,且a必须是字符串开头。前瞻只不过是匹配的一个条件而已
// 注意:匹配exp2
// 后顾
(?<=exp1)exp2 // 匹配exp2,但必须满足条件exp2前面必须是exp1; 比如:/(?<=请紧闭)冰箱门/ 将匹配 ‘请紧闭冰箱门‘中的 ‘冰箱门’
// 负前瞻
exp1(?!exp2) // 匹配exp1, 且必须满足条件exp1后面不是exp2。 比如: /中国(?!人)/ 将匹配 ‘中国话‘中的 ‘中国‘,但不可以匹配 ‘中国人‘
// 负后顾
(?<!exp1)exp2 // 匹配exp2,但必须满足条件exp2前面不是exp1。 // 测试前面不管是不是exp1都符合,是什么原因?
例子:去掉中英文混排字符中中文中不必要的字符
(?:pattern) // 例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries‘ 更简略的表达式。
// 规定当前位置必须是 pattern,但匹配结果不会被保存。
例子:
var str = ‘中国你好啊撒旦‘
var reg=/(?:中国(你好))(啊)/
str.match(reg)
// 结果如下图
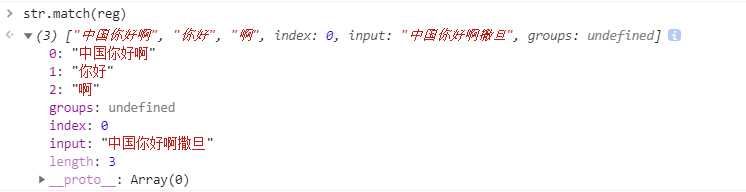
注意:通过match方法匹配的结果中会保存分组里面的匹配结果。不会保存匹配规则(?:...)匹配到的结果,如果(?:...)里面有子分组,子分组的内容还是会被保存。(?:...)里面可以嵌套它自己 (练习:Vue深入浅出第9章-练习1)
标签:换行 是什么 换行符 条件 疑问 exp 撒旦 高亮 字符串
原文地址:https://www.cnblogs.com/tina-12138/p/13243459.html