标签:建立 transform idt online 不同 网络 支持 方法 有关
1. 支持向量机(Support Vector Machine, SVM):
一种知名的二元线性/非线性分类方法,由俄罗斯的统计学家Vapnik等人所提出。它使用一个非线性转换(Nonlinear Transformation)将原始数据映像(Mapping)至较高维度的特征空间 (Feature Space) 中, 然后在高维度特征空间中,它找出一个最佳的线性分割超平面(Linear Optimal Separating Hyperplane) 来将这两个类别的数据分割开来。
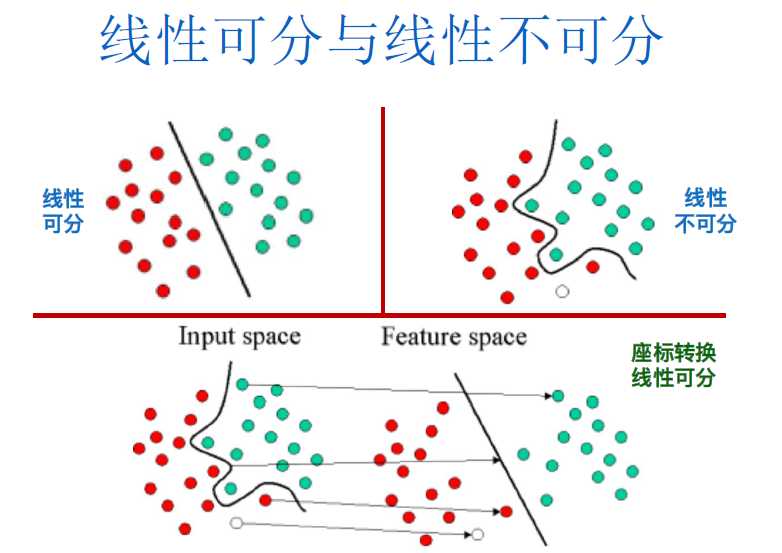
2.决策边界和支持向量
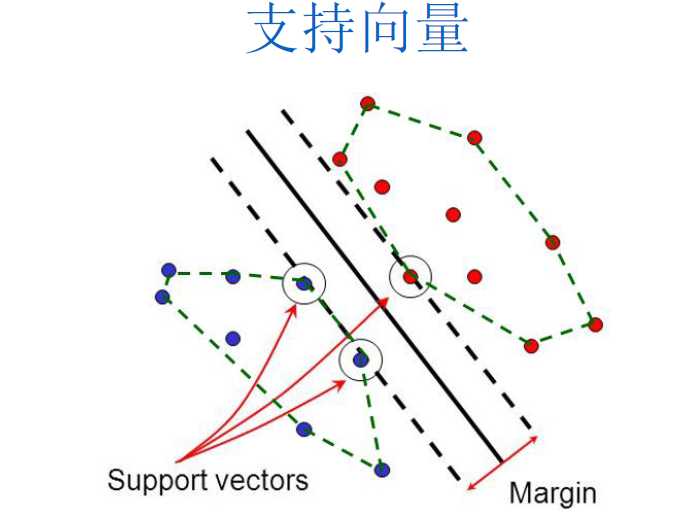
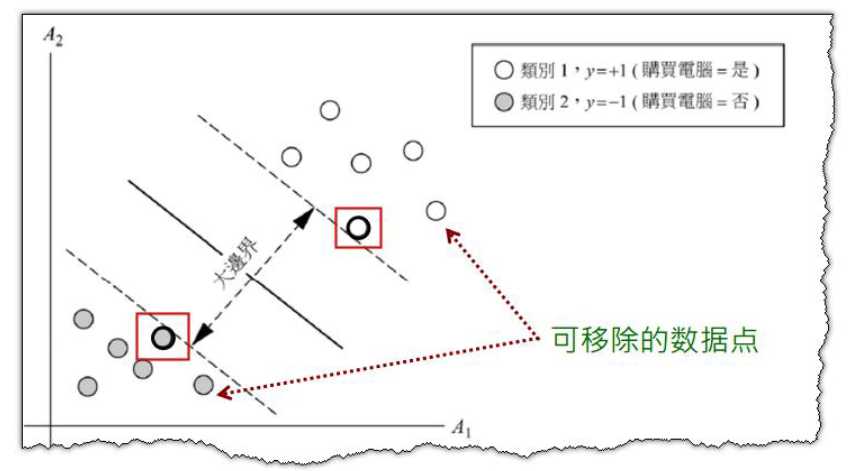
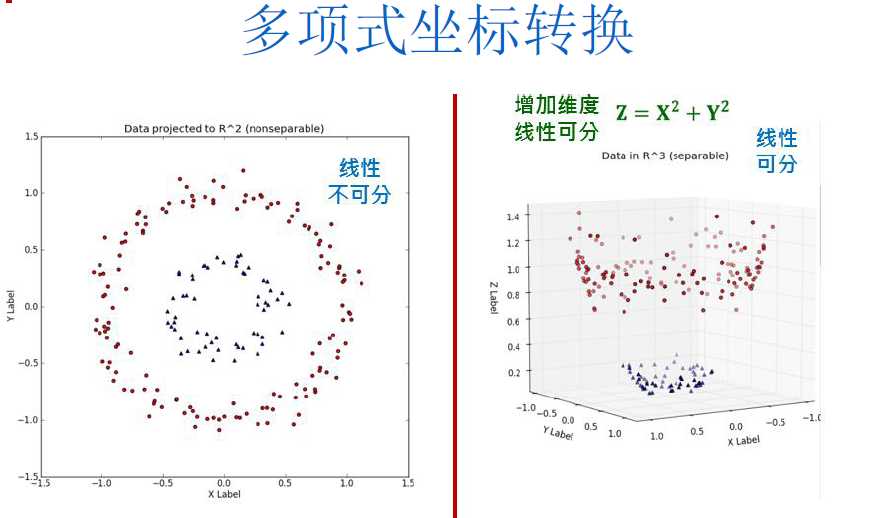
3.SVM如何处理线性不可分
第一步:使用一个非线性转化,将原始数据映射至较高维度的特征空间(Feature Space),此步骤,可以有许多的映射函数供使用,我们称此映射函数为“核函数(Kernel Function)”,不同的核函数的训练结果,会对应到输入空间上不同类型的非线性分类器。
第二步,在高维度特征空间中找出最佳的线性分割平面,,此时在高维度特征空间中找到的最大边界超平面(MMH),对应至原来空间就是一个非线性分割曲面或者曲线。
4.SVM常用的核函数
• 多项式转换(Polynomial Kernel)
• 高斯RBF转换(Gaussian Radial Basis Function)
• Sigmoid转换(Sigmoid Kernel)
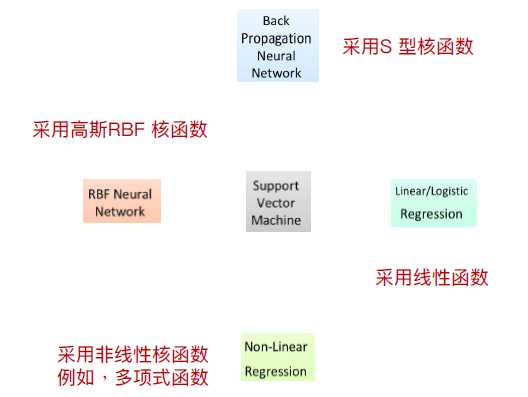
5.SVM与逻辑回归、神经网络、非线性回归间的关系
SVM使用高斯RBF核函数(Gaussian Radial Basis Function)所找到的分类器与RBF类神经网络相同
SVM使用S型核函数(Sigmoid Kernel)所找到的分类器等同于BP类神经网络。不同于类神经网络所使用的Bp算法通常会收敛到区域最佳解,SVM一定会找到全局最佳解。
标签:建立 transform idt online 不同 网络 支持 方法 有关
原文地址:https://www.cnblogs.com/liyuewdsgame/p/13245959.html