标签:启用 gns 初步 运行 head 参与 常见 上进 大型
关于混沌工程的小漫画:
“如果你不提早发现和解决问题(引入混沌工程实验),最后问题会来(周末/半夜)解决你”。

图1 混沌工程带来的变化
我们在启动篇从混沌工程的发展历程出发,分析了社区对混沌工程的理解并不是一蹴而就而是循序渐进,以此得到了第一个重要结论:
结论1 :“并不是只有研发实力突出的大型互联网公司才能实践混沌工程”。
可行性评估篇明确了混沌工程的过去、当前和未来目标(实现韧性系统,如图2所示),为了帮助不同类型的公司来进行实践混沌工程,我们提出了混沌工程的可行性评估模型。

图2 混沌工程的过去和未来
因此,我们得到了第二个重要的结论:
结论2 :“也许很多公司目前仍处在第三象限(实验技术成熟度低、公司接纳指数低),但只要根据可行性评估模型中的逐项要求和未来发展的路线图,迭代推进和持续改进,我们都可以从混沌工程实践中获得收益。”
接下来的问题便是,混沌工程实验要怎么做,具体的设计方法是什么?

图3 混沌工程实验的实践流程
如图3所示,完整的混沌工程实验是一个持续性迭代的闭环体系,从初步的实验需求和实验对象出发,通过实验可行性评估,确定实验范围,设计合适的观测指标、实验场景和环境,选择合适的实验工具和平台框架;建立实验计划,和实验对象的干系人充分沟通,进而联合执行实验过程,并搜集预先设计好的实验指标;待实验完成后,清理和恢复实验环境,对实验结果进行分析,追踪根源并解决问题,并将以上实验场景自动化,并入流水线,定期执行;之后,便可开始增加新的实验范围,持续迭代和有序改进。
下面我们会深入讨论有关混沌工程实验的准备事项:
可行性评估篇提供了这样一个混沌工程实验的可行性评估模型,从多个维度对实验技术的成熟度做了定性分析。此处的实验可行性评估,依照这个可行性评估模型,会针对具体的实验需求和实验对象进行细致评估。常见的一个形式是对照“可行性评估问题表”,对实验对象的干系人进行访谈。可行性评估问题表的内容会包含以下几个方面:
观测指标的设计是整个混沌工程实验成功与否的关键之一。最新的调研报告“Chaos Engineering Observability: Bringing Chaos Experiments into System Observability”指出在进行混沌工程实验过程中,系统可观测性已成为一种“强制性功能”,良好的系统可观测性会给混沌工程实验带来一个强有力的数据支撑,为后续的实验结果解读、问题追踪和最终解决提供了坚实的基础。
以下是常见混沌工程实验的观测指标类型:
以Netflix为例,早在2008年Netflix起步流媒体,手动追踪数百个指标,全靠人工来检测问题。 这种方法适用于数十台服务器和数千台设备,但不适用于未来的数千台服务器和数百万台设备。最终Netflix找到了一个可以反映业务状况、用户参与度的指标:每秒流视频启动次数SPS (stream-starts-per-second)。

SPS指标示例比较(红色=当前周,黑色=前一周)
SPS 模式通常是比较规则的,受到假日和事件等外部影响会有所变化。上图描绘的就是 SPS 随时间变化的波动情况,可以看出,它有一个稳定的模式,每天 SPS 峰值发生在晚上,谷值发生在清晨。这是因为人们习惯于在晚餐时间看电视节目。假期时,白天的观看次数增加,因为有更多的空闲时间在Netflix上观看节目。
如果我们将过去一周的波动图放在当前的波动图之上,就像上图中当前的图线是红色,上一周的图线是黑色,以求找出其中的差异。由此,我们可用“受SPS影响”或“不影响SPS”来衡量业务的状况。此外,由于 SPS 随时间的变化可以预期,所以我们可用一周前的 SPS 波动图作为稳定状态的模型,并通过使用预期SPS级别与实际SPS级别来衡量业务的可用性。Netflix SPS指标的这种特性,也提醒我们应以观测指标的稳定状态进行对照。
不过可行性评估中,我们发现有很多的用户还是无法定义一个合适的业务指标,如无法准确定义一个稳定状态,那么我们也可以退而求其次,使用多个指标进行联合分析来对照。具体的联合分析方法包括:静态阈值、指数平滑、双指数平滑、贝叶斯检测、马尔可夫链蒙特卡罗方法(MCMC)、鲁棒主成分分析(PCA)等等,后面我们可以专门来详细讨论。
实验场景和环境的设计要努力遵循以下三大设计目标:
以下是亚马逊AWS云上常见的实验场景:
| 故障注入场景 | 具体描述 |
|---|---|
| 依赖型故障 | AWS 托管服务异常:ELB/S3 / DynamoDB/Lambda,… |
| 主机型故障 | EC2 实例异常终止,EC2 实例异常关闭,EBS 磁盘卷异常卸载,容器异常终止,容器异常关闭,RDS 数据库实例故障切换,ElastiCache 实例故障切换,… |
| 操作系统内故障 | CPU、内存、磁盘空间、IOPS 占满或突发过高占用,大文件,只读系统,系统重启,熵耗尽,… |
| 网络故障 | 网络延迟,网络丢包,DNS 解析故障,DNS 缓存毒化,VIP 转移,网络黑洞,… |
| 服务层故障 | 不正常关闭连接,进程被杀死,暂停/启用进程,内核奔溃,… |
| 请求拦截型故障 | 异常请求,请求处理延迟,… |
这些场景的实施能力,依赖于实验工具和平台框架的选型,后面我们会专门来深入讨论。
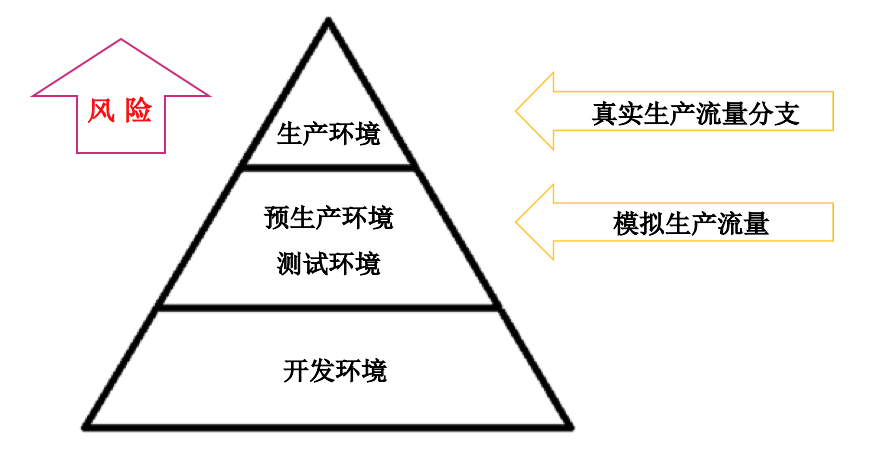
实验环境的不同,带来不同的业务风险。生产环境的业务风险最大,开发环境的业务风险最小,其他依次类推。我们会建议用户在生产环境上进行混沌工程实验,当然前提是这些实验场景和工具已经在开发/测试和预生产环境得到了验证。当然在生产环境上进行混沌工程实验也不是强制的,用户可以选择适合自己的推进节奏,逐步向生产环境靠拢。因为实验越接近生产环境,从结果中学到的越多。同时,为了体现实验对照的效果,在生产环境进行的混沌实验可以通过真实生产流量分支的方式,组建控制组和对照组,以此区分故障注入的影响,从一定程度上控制了爆炸半径。对于非生产环境的混沌工程实验,可采用模拟生产流量的方式,尽量和生产流量相似,来验证实验场景和工具的可靠性。
综上,本文是混沌工程专栏的第三篇,首先我们回顾了专栏前两篇中的重要结论,由此引申出“如何进行对照实验设计”这个实施性问题,并从实验可行性评估、观测指标设计与对照、实验场景和环境的设计三个维度,深入分析和讨论了混沌工程实验的对照设计原则和方法,后续我们还会针对特定专题进行剖析。
标签:启用 gns 初步 运行 head 参与 常见 上进 大型
原文地址:https://www.cnblogs.com/passzhang/p/13245965.html