标签:开头 运行 反馈 res rgs 依赖 搜索 ip) 限制
在分析二进制数据的程序中,模糊测试是发现安全漏洞(如缓冲区溢出)的常用技术。模糊测试一般是指测试的随机生成输入。但是近年来,过度引导模糊测试(CGF)算法取得了特别的优势。CGF从一组已知的种子输入开始,维护一组不断变化的已保存输入。在每一个模糊回合中,CGF选择一个保存的输入并随机地对其进行变异以生成一个新的输入。然后它用这个变异的输入执行被测程序。CGF使用轻量级的程序检测来收集关于测试执行的反馈,例如通过程序的控制流图的路径。与纯随机模糊一样,如果一个变异的输入导致崩溃,它将被保存以进行bug测试。然而,覆盖引导测试算法的核心创新在于,如果变异的输入导致新的代码覆盖,则将其保存起来,作为变异的基础,供后续的模糊处理使用。CGF被AFL[Zalewski 2014]和libFuzzer[LLVM Developer Group 2016]等工具普及,这些工具发现媒体播放器、web浏览器、服务器、编译器和广泛使用的库等应用程序中存在数百个安全漏洞。
最近的研究表明,模糊测试的应用不仅仅局限于发现程序崩溃。例如,模糊测试可以用于定向测试[B?hme et al。2017],基于性能的试验[Padhye等人。2019a],差异测试[Petsios等人。2017a],侧沟道分析[Nilizadeh等人。2019],发现算法复杂性漏洞[Petsios等人。2017b],发现性能热点[Lemieux等人,2018]。在每一种情况下,研究人员都会修改原来的模糊算法,以产生一种专门的解决方案。类似地,研究人员调整了原始的CGF算法,以利用来自程序的特定领域的信息,以提高代码覆盖率,例如在文件格式中使用魔法字节[LafIntel 2016;Li et al.2017;Rawat等人。2017年]或输入有效性测量[Laeufer等人,2018;Padhye等人,2019c;Pham等人。2018]。
目前,开发特定领域的模糊应用程序的实践是非常特别的。对于每一个新的领域,研究人员必须找到一种方法来调整模糊算法并产生一个新的方差其他一些模糊工具。每个这样的解决方案都可能需要-琐碎的实现。此外,这些变体是独立的,不容易组合。
在本文中,我们提出了FuzzFactory,一个实现特定领域的模糊应用程序的框架。我们的框架基于以下观察:除了那些只提高代码覆盖率的模糊化算法之外,许多领域特定的模糊化问题可以通过增加覆盖率引导的模糊化算法来有选择地保存新生成的输入以备后续变异。我们将这些中间输入称为航点,灵感来自导航领域的相应术语。这些路径点给出了模糊算法朝特定领域目标的步骤。域d的特定于域的模糊化应用程序是通过一个谓词指定的:\(is\_waypoint(i,S,d)\)。这个谓词回答了以下问题:给定一个新生成的输入\(i\)和一组先前保存的输入\(S\),我们是否应该将输入i保存到\(S\)?FuzzFactory提供了一个简单的机制来定义\(is\_waypoint\),它基于在测试执行期间可以动态收集的领域特定反馈。一个特定于领域的模糊应用程序可以通过FuzzFactory提供的一小组APIs来对测试中的程序进行测试,以收集这样的定制反馈。
FuzzFactory支持开发特定领域的模糊应用程序,而无需更改底层搜索算法。我们能够很容易地从先前的工作中重新实现三种算法,并评估它们的优缺点:SlowFuzz[Petsios et al。2017b],PerfFuzz[Lemieuxetal。2018年),以及Validityfuzzing[Padhyetal。WealsousedFuzzFactory将为三个新的应用程序原型:平滑硬比较、生成分配过多内存的输入以及在代码更改后执行增量模糊化。我们描述了这六个领域特定的模糊化应用程序,以及我们在六个真实世界的基准测试程序上的实验结果,这些测试套件是由Google发布的[2019b]。
FuzzFactory的一个关键优势是特定领域的反馈是自然可组合的。我们结合我们的领域特定的模糊应用程序来加速内存分配和平滑硬比较,以生成一个性能优于其每个组成部分的复合应用程序。复合应用程序自动生成LZ4炸弹和PNG炸弹:微小的输入分别导致libarchive中4GB和libpng中2GB的动态分配。
综上所述,本文主要贡献如下:
(1) 我们提出了FuzzFactory,一个框架,用于使用测试执行期间动态收集的自定义反馈来指定特定领域的模糊应用程序。(2) 我们描述了一个特定于领域的模糊化算法,它结合了自定义反馈和用户提供的减缩器函数,有选择地保存中间输入,称为航路点。(3) 我们确定了reducer函数必须满足的关键属性,以保证每个保存的航路点都有助于特定领域的进度。(4) 我们描述了使用我们的框架实现的六个领域特定的模糊应用程序的实现,以及我们在六个实际测试程序上对这些应用程序的实验评估结果。(5) 我们描述了如何组合多个领域特定的模糊应用程序,并从经验上展示了这种组合如何比它们的组成部分表现得更好。(6) 我们描述了特定于领域的模糊化框架FuzzFactory提供的API,并在https://github.com/rohanpadhye/fuzzfactory。
近年来,覆盖引导模糊化(CGF)已成为实现真实软件模糊化的最有效技术之一。CGF已经在几个流行的工具中实现,包括AFL[Zalewski 2014]和libFuzzer[LLVM Developer Group 2016]。CGF的工作原理是使用大量随机生成的输入执行一个测试程序。CGF不是从头开始生成完全随机的输入,而是选择一组先前生成的输入,并对它们进行变异以获得新的输入。算法1给出了CGF的高级伪代码。

CGF算法采用一个插入指令的程序和一组用户提供的种子输入。CGF保持两个全局状态:(1)S保持一组被算法修改的已保存输入;和(2)totalCoverage,它跟踪程序在S中输入上的累积覆盖率。CGF可以跟踪任何类型的覆盖;实际上,最常用的是分支覆盖或基本块转换覆盖。S初始化为用户提供的种子输入集,\(totalCoverage\)初始化为空集。CGF的主模糊循环遍历输入集,从集合S中选择一个输入i。通过一个特定于实现的启发式函数\(fuzzProb(i)\),CGF决定是否改变输入i。如果选择i进行突变,CGF随机突变\(i\)产生\(i′\)。随机突变可以从一组预定义的突变中选择,例如位翻转、字节翻转、整数值的算术增量和减量、用“有趣的”整数值\((0,MAX\_INT)\)替换字节,然后,CGF用新生成的输入执行程序,并在临时变量覆盖率中收集输入的覆盖率。如果观测到的覆盖率包含一些新的覆盖点,而这些覆盖点在全局累计覆盖率totalCoverage中不存在,则将新的输入\(i′\)添加到保存的输入S集合中。然后输入\(i′\)将在fuzzing循环的未来迭代中发生变化。模糊循环一直持续到时间预算到期。

考虑图1a中的示例测试程序,函数测试采用两个16位整数a和b作为输入。一个常见的测试目标是生成在这个程序中最大化代码覆盖率的输入。我们使用算法1对这个测试程序执行CGF。假设我们从种子输入开始:a=0x0000,b=0x0000。种子输入不满足第2行的条件。CGF算法随机地对这个种子输入进行变异,并在变异的输入上执行测试程序,同时寻找新的代码覆盖率。图1b在灰色框中描述了CGF可以保存的一系列示例输入,从黄色框中的初始种子输入i1开始。两个输入之间的一个实心箭头,比如i和i′,表示输入i被突变以生成i′。经过一些尝试后,CGF可能会将i1中的a的值更改为0x0020之类的值,该值满足第2行的条件。因为这样的输入会导致执行新的代码,所以它被保存到S。在图1b中,这是输入i2。小的字节级突变使CGF能够随后生成满足图1a第3行和第4行分支条件的输入。这是因为有许多可能的解决方案分别满足a>0x1000和b>=0x0123的比较;我们称这些软比较。图1b示出了我们示例中的相应输入:i3和i4。然而,对于CGF来说,生成满足第5行a==b之类的比较的输入要困难得多;我们称这些为硬比较。输入i1–i4上的随机字节级突变不太可能产生a==b的输入。因此,第6行的代码可能无法在使用常规CGF的合理时间内执行。
现在,考虑另一个测试目标,在这个目标中,我们希望生成最大化通过malloc动态分配的内存量的输入。此目标对于生成压力测试或发现内存不足相关的潜在错误非常有用。CGF算法使我们能够生成在第8行调用malloc语句的输入,例如i4。但是,这个输入只分配0x1220字节(即,刚刚超过4KB)的内存。虽然这个输入上的随机突变可能会产生分配更大内存量的输入,但CGF永远不会保存这些,因为它们的覆盖范围与i4相同。因此,CGF不太可能在合理的时间内发现分配输入的最大内存。
如果我们将一些有用的中间输入保存到S,而不管它们是否增加了代码覆盖率,上面列出的两个挑战都可以解决。然后,这些中间输入的随机突变会产生输入突变我们称这些中间输入点. 例如,为了克服像a==b这样的困难比较,我们希望如果中间输入最大化a和b之间的公共位的数量,就可以节省中间输入。我们把这个策略称为cmp。图1b中的蓝框显示了当对航路点使用cmp策略时可以保存到S的输入。在这种策略中,输入i5和i6被保存到S,即使它们没有实现新的代码覆盖率。现在,输入i6可以很容易地变为输入i7,它满足条件a==b。因此,我们很容易在图1a的第6行发现触发中止的输入。类似地,为了实现最大化内存分配的目标,我们保存在给定的malloc调用中分配比S中任何其他输入更多内存的航路点。图1b显示了可以用这种策略(称为mem)保存的示例航路点i8和i9。从i9到i10的虚线箭头表示,经过几个这样的路径点,随机突变最终将导致我们生成输入i10。这个输入导致测试程序在第8行分配最大可能的内存,这几乎是64KB。
现在考虑的条件是,在图1a中,条件是改变,而不是图1a的条件。我们需要在第一个0x8行调用malloc来克服这个问题。我们可以将两种保存路径点的策略组合如下:如果一个新的输入i增加了硬比较操作数之间的公共位数量,或者增加了在调用malloc时分配的内存量,那么就保存一个新的输入i。在第4.7节中,我们将演示这些策略的组合如何使我们能够自动生成PNG炸弹和LZ4炸弹,即在分别模糊libpng和libarchive时分配2-4GB内存的微小输入。
我们提出了一个叫做FuzzFactory的框架,它允许用户实现选择路径点的策略。为此,用户指定除了覆盖率信息外,还需要从被测程序的执行中收集哪些自定义反馈。用户还指定了一个函数,用于在输入集合中聚合此类反馈;聚合的反馈用于决定是否应将某个输入视为一个航路点。
接下来我们将描述该框架及其底层算法。该框架使我们能够迅速实施文献中的三个现有战略和四个新的战略,包括一个综合战略。
我们的目标是构建一个框架,允许用户通过简单地定义一个自定义谓词:\(is\_waypoint(i,S,d)\) 来构建一个特定于域的模糊应用程序d。谓词告诉模糊器一个新的输入i是否是一个航路点;也就是说,我是否应该被保存到一组已保存的输入S中,以便以后可以对其进行变异以生成新的输入。
在传统的CGF算法中,是否保存输入的决定是根据程序对输入i的动态行为来定义的。具体地说,如果程序对输入i的覆盖包括一个覆盖点,该覆盖点不存在于程序对S中的输入累积获得的覆盖中,则CGF认为i是有趣的并将其保存到S。这个决定是基于一种特定的反馈(即覆盖率)来决定的。反馈直接关系到CGF的目标,即增加程序的覆盖率。
虽然提高代码覆盖率对于发现新的程序行为很重要,但我们相信,如果以其他测试目标为指导,模糊器可以变得更加有效和多样化,例如:发现性能瓶颈或内存使用问题,覆盖最近修改的代码,执行有效的输入行为,等等。
fuzzfactory允许用户原型化以用户定义的自定义目标为目标的fuzzer。支持自定义或特定于域的目标,用户需要指定:(1)从程序执行过程中收集的对任何输入的反馈的具体类型,以及(2)如何使用此反馈来确定输入是否应该被认为是有趣的和保存的。
接下来,我们将描述FuzzFactory用户指定他们希望从执行中获得的特定于域的反馈的机制。然后我们解释is_航路点谓词如何使用这种自定义反馈来确定是否需要保存输入。我们还描述了如何撰写此类领域特定的反馈。最后,我们展示了如何扩展算法1中的CGF算法来考虑特定领域的反馈。
?
在FuzzFactory中,我们为用户提供了一种机制来指定一个域,并从被测程序的执行中收集定制的特定于域的反馈(DSF)。域特定反馈(DSF)是\(dsf_i : K → V\)的映射,其中i是程序输入,K是一组键(例如程序位置),V是一组值(通常是我们想要优化的东西的度量)。通过在输入i上执行被测程序来填充映射。例如,如果我们对生成程序执行增加内存分配的输入感兴趣,那么\(dsf_i\)是从L到N的映射,其中L是调用内存分配函数(例如malloc)的程序位置集,N是自然数集。\(dsf_i(k)\)表示在对测试输入i执行程序期间分配给程序位置k的内存总量(以字节为单位)。
通常,用户将域指定为\(d=(K,V,a,a_0,\nabla)\)形式的元组其中K是一组键,V是一组值,a是一组聚合值,\(a_0\)是始聚合值,以及\(\nabla:A×V→A\)是一个减缩函数。用户指定如何在对输入i执行测试程序期间,通过在测试程序中插入适当的指令插入来更新map \(dsf_i\)。我们来解释A,\(a_0\)的含义,还有\(\nabla\)在下一小节中的用户定义域中。
我们使用在输入i上执行测试程序时得到的\(dsf_i\)映射,以确定是否需要保存。为此,FuzzFactory将从多个测试输入的执行中收集的特定于域的反馈聚合为一个属于用户定义集a的值。为了计算这个聚合值,用户提供一个初始聚合值a 0∈a和一个reducer函数\(?:A×V→A\)作为域的一部分。对于任何\(a∈A\)和任何v,\(v′∈V\),一个约化函数必须满足以下性质:
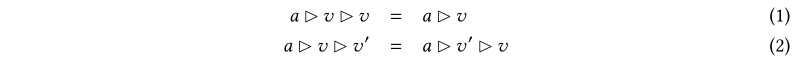
这些规则分别表示第二个操作数的幂等性和应用程序顺序不敏感。对于内存分配域(比如\(d^{mem}\)):V和A都是自然数N的集合。初始聚合值\(a_0=0\),以及?是对自然数的最大运算。因此我们可以定义\(d^{mem}=(L,N,N,0,max)\)。性质1满足,因为\(max(max(a,v),v)=max(a,v)\)对于任何\(a,v∈N\)。性质2是满足的,因为\(max(max(a,v),v′)=max(max(a,v′)\)对于任何\(a,v′,v∈N\)。属性有助于确保每个保存的航路点都有助于特定领域的进度;当遇到下面的定理1时,将访问该点。注意,这些属性不是由FuzzFactory静态验证的;用户有责任确保他们选择的reducer函数满足属性1和属性2。
一般来说,让\(dsf_i\)是在用i执行程序p期间填充的dsf映射。对于给定的输入集\(S={i_1,i_2,...,i_n}\),我们为域d和密钥k∈k定义聚合域特定反馈值\(A(S,k,d)\),如下所示:
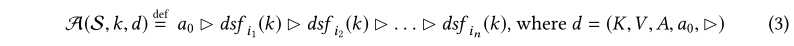
由于性质1和2,\(A(S,k,d)\)的值是唯一定义的;顺序\(i_1,..,i_n\)的选择无所谓。
对于内存分配域,聚合反馈值\(A(S,k,d^{mem})\)表示在程序位置k∈L处分配给S中所有输入的最大内存量。对于这个域,如果对i的执行导致在某个程序位置\(k\epsilon L\)处的内存分配比在S中的输入执行期间在k处观察到的任何分配的内存分配都多,那么我们希望保存一个输入i来设置S。在FuzzFactory中,我们将谓词\(is\_waypoint(i,S,d)\)定义如下:
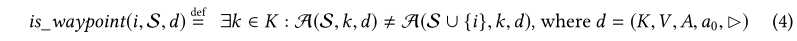
该定义意味着,如果对输入的执行导致某个键的聚合域特定反馈值发生更改,我们将保存输入i。注意,为了决定一个输入i是否应该被视为一个航路点,我们只检查总聚合是否发生变化;即\(A(S,k,d)\neq A(S∪\{i\},k,d)\)是否发生变化。然而,属性1和属性2的一个重要结果是,这种变化总是指向某种特定于领域的进展的方向,用A上的偏序表示。换句话说,函数A对于偏序?的第一个参数是单调的。例如,在内存分配域\(d^{mem}\)中:如果\(A(S,k,d^{mem})\neq A(S∪{i},k,d^{mem})\)对于某个程序位置k∈L,这意味着在执行i的过程中,在k处分配的内存大于在S中任何其他输入在k处分配的内存。这个例子中的偏序是自然数的总序:≤。更一般地说,我们可以陈述以下定理:
定理1(聚集的单调性)。A域\(d=(K,V,A,a_0,?)\)的reducer函数?满足属性1和2在上施加偏序?,使得函数a在其关于?的第一个参数中是单调的。也就是说,对于任何这样的域d,任何键k∈k,以及对于A:
\(S_1?S_2?A(S_1,k,d)?A(S_2,k,d)\)
上的某些二元关系?我们在附录A中证明了这个定理。
推论2:一个输入i被认为是一个路径点,如果聚合域特定的反馈严格地为某个键k取得进展,而不牺牲任何其他键的进度。特别是:
\(is\_waypoint(i,S,d) \Leftrightarrow (?k∈k:A(S,k,d)\leq A(S\cup \{i\},k,d))\\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ∧(?k∈k:A(S,k,d)?A(S∪\{i\},k,d))\)
其中\(a?b \Leftrightarrow a\leq b∧a\neq b\)
证明。根据公式4和定理1中is_waypoint的定义。
FuzzFactory允许用户自然地为一个程序组合多个域测试。这个使模糊化能够同时针对多个目标。
假设用户指定了一组域D,其中\(D=(K,V,A,a_0,?)\)对于每一个d∈D,我们将谓词的定义推广到d as以下:
对一组域D是真的当且仅当对某个域d∈D是真的。如果\(is\_waypoint(i,S,D)\)为真,我们将输入i保存在S中。注意,推论2自然地扩展到多个域的组合:\(is\_waypoint(i,S,D)\)表示至少一个域d∈D中至少一个键的严格进程。

算法2描述了在FuzzFactory中实现的领域特定的模糊化算法。该算法对算法1中描述的传统覆盖引导模糊算法进行了扩展,并用灰色背景进行了标记。扩展非常简单:在对输入i′执行程序p的过程中,该算法不仅收集覆盖率,还收集域特定的反馈映射\(dsf^1_{i′},...,dsf^{| D |}_{i′}\),用于D中的每个域。然后它在调用\(is\_waypoint(i′,S,D)\)中使用这些映射来确定是否应该将新的输入i‘添加到保存的输入S集合中。
我们通过实例化六个独立的领域特定的模糊应用程序来演示FuzzFactory的适用性。其中一些模糊化算法已经在前期工作中被提出和实现。我们实现这些算法的动机是评估是否可以在不改变底层模糊算法或搜索启发式的情况下,在我们的框架中原型化这些算法。第4.1节到第4.6节描述了六个领域,按照复杂程度的增加顺序:
(1) slow:基于SlowFuzz[Petsioset al。2017b年]。这是FuzzFactory中实现的最简单的领域。
(2)perf:基于PerfFuzz[Lemieux et al。2018年]。在FuzzFactory中,这自然地泛化了慢。
(3)mem:一种新的应用程序,用于生成最大化动态内存分配的输入。
(4)有效性:有效性模糊算法的一个应用[Padhyeetal et al.2019b,c],这意味着将输入生成偏向于满足特定程序有效性检查的输入。
(5)cmp:一个平滑硬比较的领域。虽然之前的很多工作都是针对这个应用,但是我们的特定解决方案策略是新颖的。
(6)diff:测试中代码更改后增量模糊化的一个新应用程序。
用于每个应用程序,(1)我们用元组\((K,V,A,a_0,?)\)定义域d(2) 借助于表2中定义的一些实用程序,我们描述了在输入i 1上执行测试期间,我们如何使测试程序填充map \(dsf_i\),以及(3)我们报告将特定领域的模糊实现应用于一组实际程序的结果。
组成。FuzzFactory的一个关键优势是它使我们能够自然地组合多个主特定的fuzzingapplicati没有额外的努力。不安全4.7,我们描述了一个CMP和mem的组成,它平滑地共享了比较,以使B一个记忆地点。很明显,我们发现这样的构图可以表现得更好,而不仅仅是其部分的总和。
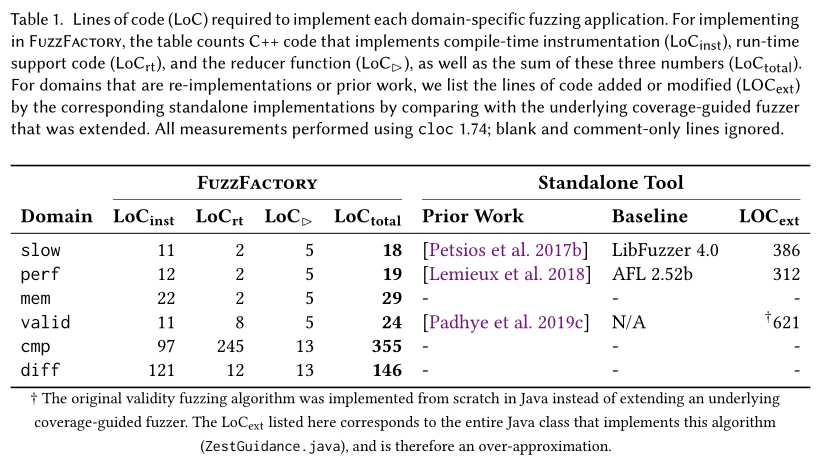
实施。传统上,实现每一个这样的领域将需要非同小可的努力修改模糊工具,如AFL,以实现特定领域的目标。使用FuzzFactory,上述六个域中的四个可以在30行C++代码中实现。表1列出了使用FuzzFactory实现本文中提出的六个域中的每一个域所需的代码行。第6节提供了关于我们的实现的更多细节。对于重新实现先前工作的域,该表还列出了实现相应的专用独立模糊工具所需的代码行。


程序仪表。第4.1节到第4.6节描述了如何使用测试程序来实现本文中介绍的六个领域中的每一个。当对输入i执行测试程序时,该工具可以在map \(dsf_i\)中收集特定于域的反馈。这样的指令插入是在编译时执行的。尽管我们的实现在LLVM IR级别执行安装,但是为了便于表示,我们在更高的抽象级别上描述了六个域中每个域的工具逻辑。表2列出了我们在特定领域的抽象描述中使用的一些钩子、操作和实用程序函数仪器。我们接下来描述如何解释表2中的信息。
每当在通过测试时遇到程序中的相应元素时,钩子就会被检测框架(例如LLVM)激活程序。用于例如,在编译时为程序中的每个callexpression函数调用func_call(name,args)钩子。这里,name是一个字符串,args是对构成函数调用参数的语法表达式的引用列表。一个检测过程,比如我们为每个模糊域编写的过程,指定了一些处理此类钩子的逻辑。处理程序逻辑可以选择在当前钩子所在的程序元素之前或之后插入新代码激活。用于例如,func_调用的处理程序可以静态地查看名称(比如f),以决定是否在对f的调用周围插入代码。代码是通过调用诸如在后面插入和在前面插入等操作来插入的。插入的代码可以使用编译时常量或引用静态程序元素,例如:f的一个或多个参数、全局变量或用户定义函数。为了便于表示,我们将插入的代码显示为源代码级别的伪代码,而不是某个IR中的指令。通常,我们会插入更新\(dsf_i\)映射的代码,在实践中,我们插入一条指令,调用第6.1节中列出的某个api。处理器逻辑是不受限制的,在我们的实现中,它是使用LLVM API的任意C++代码。处理程序逻辑可以使用fuzzfactory编译时提供的实用函数.Table2仅列出所需的挂钩和实用功能描述论文中提出的六个领域(表3-8)。为了实现新的域,还可以插入其他语言结构,如分支、加载、存储等。
实验评价。在我们的实验中,我们使用了来自Googlefuzzing测试套件[google2019b]的六个基准测试程序。这个套件包含了特定的历史版本的程序,这些版本已经使用OSS fuzz基础设施进行了彻底的模糊化处理[google2019a]。我们使用的六个基准包括:(1)libpng-1.2.56,(2)libarchive-2017-01-04,(3)libjpeg-turbo-07-2017,(4)libxml2-v2.9.2,(5)vorbis-2017-12-11,和(6)boringssl-2016-02-12。2基准测试是在RC++中编写的。之所以选择基准(1)–(4),是因为它们通常在模糊化文献中使用[Chen和Chen 2018;Chen等人。2019年;Lemieux等人。2018年;Lemieux和Sen 2018年;Peng等人。2018年;Pham等人。2018年]。之所以选择基准测试vorbis和boringssl,是因为它们期望不同的输入格式。我们只用了六年的时间对谷歌的CPU基准测试进行了评估。
所有实验均运行在AmazonAWS‘c5.18xlarge’例子。每个实验重复12次,以说明随机算法的可变性。除非另有说明,我们的模糊化实验使用的是基准测试套件中提供的初始种子输入,在模糊化过程中输入大小限制为最多10KB,并且每次运行24小时。
对于每个应用程序,我们评估以下研究问题:“FuzzFactory是否在不修改底层搜索算法的情况下帮助实现了主要的特定模糊化目标?”. fuzzyfactory是AFL的扩展,继承了AFL的变异和搜索启发式。因此,对于每个应用领域,我们将特定领域模糊化的结果与基线:常规覆盖引导利用AFL进行模糊处理。当然,我们进行这种比较所依据的度量因领域而异。我们注意到,如果FuzzFactory的结果与先前工作中实现的特定领域的专用模糊工具的结果进行比较是没有意义的,如果这些工具也使用不同的突变和搜索启发式。因此,我们只在扩展了AFL的情况下与之前的工作进行直接比较,类似于FuzzFactory。

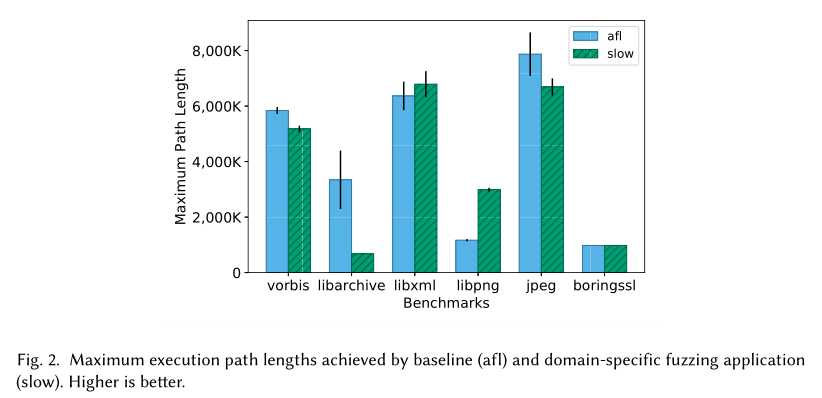
模糊测试可以用来生成增加被测程序算法复杂性的输入。斯洛夫兹[Petsios等人。2017b]使用资源导向的进化搜索引入了这一理念。搜索使用一个适应度函数,该函数计算在执行单个测试输入时执行的基本块的数量。我们把这个度量称为执行路径长度。
我们的第一个特定于领域的模糊应用程序是SlowFuzz到我们框架的一个端口。此应用程序的目标是生成最大化被测程序执行路径长度的输入。我们想将\(is\_waypoint(i,S,d)\)谓词定义如下:如果一个输入的执行导致路径长度比S中的任何其他输入都长,那么就应该对其进行保存。
表3的第一行定义了这个域(比如d),如下所示。特定于域的反馈映射dsf将单个键0(K={0})映射到一个自然数(V=N)。在映射中,dsf(0)表示测试输入i的执行路径长度。这些值被聚合成一个数字(A=N),表示在一组输入中观察到的最大执行路径长度\((a_0=0,a?v=max(a,v))\)。
表3还描述了如何在运行时向测试程序正确更新mapdsf中的条目。我们使用仪器钩子入口点和新的基本块,以及后面的操作插入,所有这些都在表2中定义。使用这些函数,我们可以将表3中的描述解释如下:在被测程序的入口点,插入一个将dsf(0)设置为0的语句。然后,在程序中的每个基本块上,插入一个语句,该语句增加存储在dsf(0)中的值。因此,在测试执行期间,dsf(0)的值在每次访问基本块时递增一个。在测试输入执行结束时,dsf(0)的值将包含执行路径长度。由于该域的reducer函数被定义为max,初始值为0(见表3的第一行),域特定反馈A(S,0,d)的聚合值将是在S中观察到的所有输入的最大执行路径长度。
实验评价。图2显示了我们在基准程序上使用这个应用程序的实验结果。在24小时的模糊化之后,我们评估基线(afl)和特定领域的模糊化应用程序(slow)的最大执行路径长度(通过生成的测试语料库)。该图显示了该指标在12个方面的平均值和标准误差重复。为了libpng,域特定的反馈可以生成路径长度大于2的输入。基线的5倍。对于boringssl和libxml来说,增长不是有意义。有趣的是,slow的最大执行路径长度实际上比aflon在其余三个基准测试中发现的要小。对于这个结果的一个可能的解释是,从第一个输入开始,缓慢地尝试最大化执行路径长度。另一方面,afl将其时间花在最大化代码覆盖率上,并在测试程序的组件中发现不由种子输入执行的更长的执行路径。这一区别在Libashive中最为明显。在我们考虑过的所有基准测试中,libarchive是唯一一个Google测试套件中提供的初始种子输入无效的基准。也就是说,libarchive的初始种子输入会导致测试程序在错误状态下提前退出。由于AFL在24小时内只增加代码覆盖率,因此它最终能够生成有效存档(例如ZIP文件)的输入,这些文件的处理会导致更长的执行路径。在libpng等基准测试中,提供的种子输入是有效的,并且已经覆盖了测试程序中有趣的代码路径;因此,slow能够有效地最大化路径长度。当初始种子输入已经提供了良好的代码覆盖率时,这种由SlowFuzz启发的方法似乎效果最好。
注意,我们没有直接将我们的实现与Petsios等人实现的SlowFuzz工具进行比较。[2017b]。SlowFuzz是libFuzzer的扩展,而FuzzFactory则建立在AFL之上。libFuzzer使用的突变和搜索启发式与AFL不同;因此,比较SlowFuzz工具和我们的slow实现不会帮助我们确定与搜索启发式无关的领域特定反馈的值。
PerfFuzz[Lemieux等人。2018]是另一个使用模糊测试生成病理性输入的工具。与SlowFuzz不同的是,SlowFuzz最大化了单个条件——执行路径长度PerfFuzz独立地最大化被测程序中每个基本块的执行计数。为此,PerfFuzz扩展了覆盖引导的模糊化算法,如果新生成的输入增加了任何基本块的最大可观察执行计数,则可以保存新生成的输入。在这个域中,目标是找到多次执行相同基本块的输入。

表4描述了我们如何在框架中实现PerfFuzz。第一行定义域。这个DSF映射(即K)中的键范围超过程序位置L的集合。DSFmap的值以及聚合值表示执行计数(即V=N和A=N)。减速器函数(即?)是max,初始值为\(a_0=0\),就像在SlowFuzz中一样。
表4还描述了我们如何对测试中的程序进行测试。在每个测试执行的开始(入口点),我们用值0初始化整个DSF映射。每次访问一个新的basic block k时,我们递增dsf(k)中存储的值。这是在instrumentation hookfunction new_basic_块中完成的,使用current_program_loc()函数静态获取被检测的基本块的程序位置(参考表2)。在测试执行结束时,dsf(k)将包含执行基本块k的次数。由于reducer函数是max,如果新生成的输入增加了测试程序中任何基本块k的执行计数,那么它将被视为一个航路点。
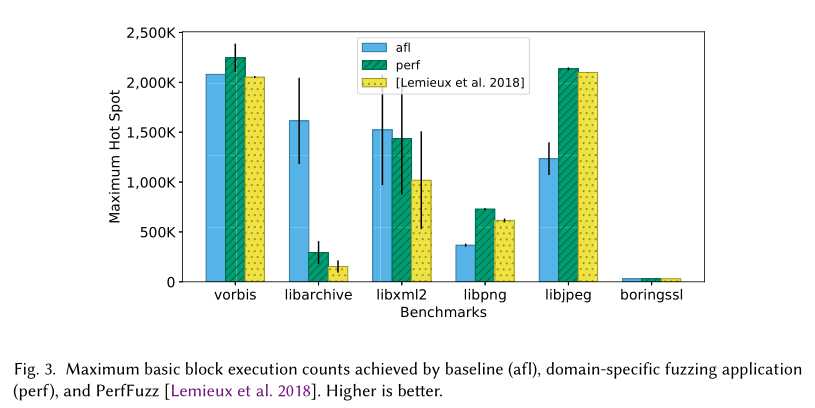
实验评价。图3包含了我们在基准程序上使用这个应用程序的实验结果。因为PerfFuzz工具是由Lemieux等人实现的。[2018]也是AFL的一个扩展,它使用了与FuzzFactory相同的变异和搜索启发式,因此,对于这个应用,我们可以直接与PerfFuzz进行比较。我们在metricmax热点上评估了FuzzFactorydomain特定的fuzzing应用程序(perf)、基线(afl)和PerfFuzz工具。PerfFuzz文件将max hot spot定义为生成的测试语料库中所有输入的任何基本块的最大执行计数。该图显示了该指标在12次重复中的平均值和标准误差。
图3显示perf能够为六个基准测试中的三个生成最大化热点的输入:vorbis、libpng和libpjeg。对于libpng和libjpeg turbo,perf发现的热点执行比基线afl发现的多2倍和7倍。对于libarchive,perf应用程序的性能要差得多。与上一节报道的实验类似,这里的主要问题是libarchive提供的初始种子输入导致提前退出。由于baseline AFL在增加代码覆盖率上花费更多时间,而不是基本的块执行计数,因此它最终会生成有效的存档文件(例如ZIP)。考虑到libarchive是一个执行解压的程序,生成一个有效的归档文件就足以在执行解压的代码组件中发现巨大的热点。另一方面,perfonly发现libarchive解析文件元数据时的热点。我们的评估表明PerfFuzz算法还依赖于覆盖有趣代码路径的初始种子输入。在所有的基准测试中,perf的结果与专门的PerfFuzz工具相似或稍好一些。
我们现在描述FuzzFactory的一个新应用:生成加剧内存定位的输入。对于这样一个领域,有几个用例,比如发现被测程序可以为给定大小的输入动态分配的最大内存量,发现可能导致与内存不足相关的错误的输入,或者为基准测试目的生成一组内存压力测试。

表5描述了我们对内存分配域的检测。此表第一行的域定义以及入口点的dsf初始化与PerfFuzz域的定义完全相同(表4)。然而,我们在测试程序中插入调用函数malloc或calloc的表达式,而不是在每个基本块处递增DSF映射中的值。每当测试程序在程序位置k使用malloc或alloc分配新内存时,我们都会将dsf(k)的值增加字节数分配。在测试执行结束时,dsf(k)的值包含在程序位置k为所有这些位置k分配的字节总数。
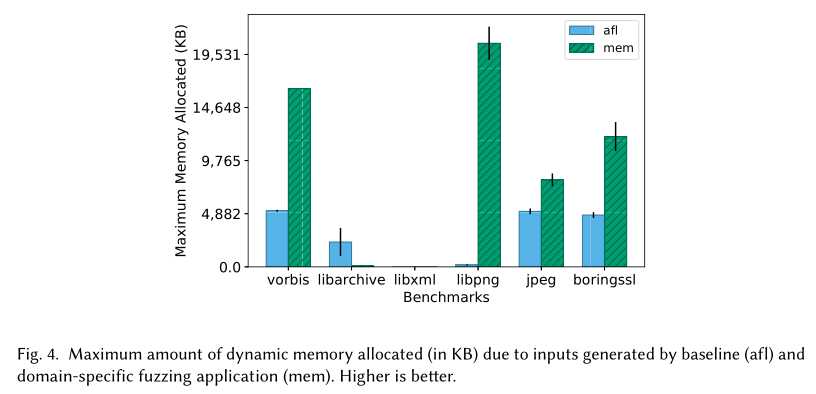
实验评价。图4显示了我们在基准程序上使用这个应用程序的实验结果。在24小时模糊化运行后,我们根据生成的输入分配的最大动态内存量来评估特定领域的模糊应用程序(mem)和基线(afl)。图中显示了该指标在12次重复中的平均值和标准误差。
基准libxml似乎没有执行任何依赖于输入的动态内存分配。在vorbis、libpng、libjpeg turbo和boringssl的基准测试中,我们的特定领域的模糊应用程序生成的输入分配1。内存增加5倍–120倍。对于libpng,我们的应用程序生成了输入PNG图像,其元数据指定了允许的最大图像尺寸-根据在200万像素的测试驱动程序中硬编码的验证规则。尽管这些PNG文件本身的大小只有1KB左右,但它们的处理需要超过24mb的动态分配内存。在第4.7节中,我们将讨论一个复合领域特定的模糊应用程序,它生成的PNG图像的尺寸小于1000像素,但其处理需要libpng提供超过2GB的动态内存分配。
就像slow和perf一样(分别参考4.1和4.2节),mem应用程序对libarchive无效。回想一下,这是我们套件中唯一一个由于验证错误导致初始seedinput提前退出的基准测试。
与CGF相关的一个主要问题是大多数随机生成的输入都是无效的;也就是说,它们导致测试程序提前退出并返回错误状态。例如,传统的cgfonlibpng不太可能生成许多有效的PNG图像,即使fuzzing是用有效的输入开始的。新生成的输入所实现的大部分代码覆盖都位于处理输入验证和错误报告的代码路径中。因此,CGF算法很难有效地测试和发现其主要功能的缺陷程序。在在许多情况下,希望生成有效的输入,以最大限度地提高代码覆盖率。例如,可能需要测试图像查看器和媒体播放器等程序,这些程序可以下载和处理上载到社交媒体网站上的文件。很可能,这样的网站不允许用户上传无效文件。图像查看器或媒体播放器中的错误只会在处理有效文件时出现。
有效性模糊化。最近有人提议解决产生有效投入的问题。在有效性模糊化中,根据程序特定的有效性概念(例如libpng的输入是否是有效的PNG文件)对测试程序进行扩充,以返回关于输入是否有效的反馈。在模糊化循环期间,新生成的输入将被保存(1)如果它们增加了整个代码覆盖率,或者(2)如果新生成的输入是有效的,并且它覆盖了以前生成的有效输入没有覆盖的代码。第一个标准要求,只要中间输入产生新的累积码覆盖率,就不管其有效性如何。我们的希望是,对这些输入进行变异将导致以后生成更有趣的有效输入。第二个标准试图最大化有效输入中的代码覆盖率。其他研究人员也使用了程序特定有效性的概念来指导模糊搜索以生成更有效的输入[Laeufer et al。2018年;Pham等人。2018年]。

在我们现在如何实现模糊算法的有效性框架。第一,我们修改了基准测试套件附带的测试驱动程序,以添加程序特定假设(expr)语句。assume的语义类似于更熟悉的assert的语义:如果参数expr在运行时求值为true,则该语句为no-op;否则,将停止测试执行。图5展示了我们对libpng测试驱动程序所做的三个单行更改之一。我们不必因为无效的PNG头而提前退出,而是简单地用一个假设语句包装有效性检查。除了boringssl之外,我们能够对所有基准测试驱动程序进行如此微小的更改。在我们修改了驱动程序的五个基准测试中,我们添加了1-3个假设语句,将现有的有效性检查包装在测试驱动程序中,更改了1-11行代码。第二,我们插入测试程序,用测试执行期间的代码覆盖率信息填充DSF映射,类似于传统的覆盖率指南模糊化。在运行时,如果要假定的任何参数的计算结果为false,则整个DSF映射将在退出之前重置为初始状态。因此,当且仅当测试输入有效时,DSF映射才会镜像传统的代码覆盖信息。无效输入不产生特定于域的内容反馈。这个scheme会导致算法2的以下行为:如果新生成的输入导致新的累积代码覆盖率,或者输入有效并实现更多的代码覆盖率(即。,更改聚合域特定反馈)而不是任何其他有效输入(即,在产生特定域反馈的输入之间)。

表6更正式地描述了有效性模糊应用程序。此表的第一行定义域。这个域的DSF映射将程序位置(即K=L)映射到执行计数(即V=N),类似于perf应用程序(参考第4.2节)。然而,当聚合特定于域的反馈时,有效性模糊应用程序为每个基本块收集一组数量级的执行计数(即\(A=2^N\))。这反映了AFLin收集代码覆盖率所使用的启发式方法[Zalewski 2017]。聚合由reducer 操作者定义:\(a?v=a∪log_2(v)\),其中\(log_2(v)\)提取从DSF映射中提取的值v中最高设置位的位置。初始值为空集:\(a_0=?\)。这些信息允许在执行相同代码片段的输入之间进行区分,例如,2次与4次(因为这些计数的数量级不同),但不是10次对11次(因为这些计数的数量级相同)。表6中为hook entry_point和new_basic_块描述的操作与perf应用程序的操作完全相同(表4)。函数调用的钩子处理对assume()的调用。检测插入执行所需逻辑的代码:如果assume的参数计算结果为false,则在调用assume之前清除DSF映射中的所有条目,从而停止测试。
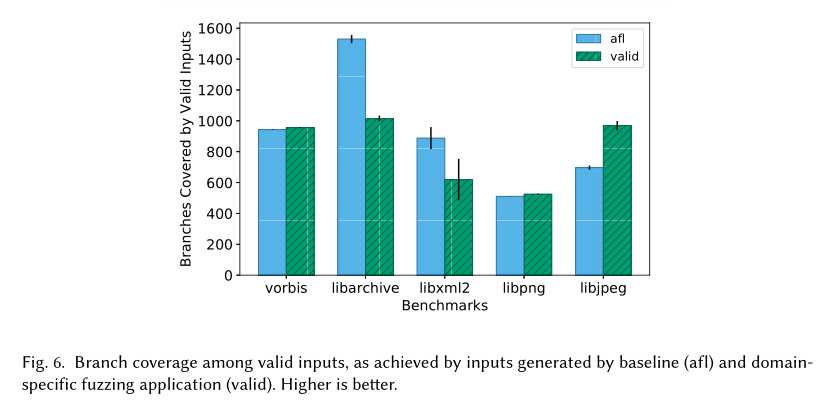
实验评价。图6包含了我们在基准程序上使用这个应用程序的实验结果。在24小时的模糊化运行之后,我们评估了特定领域的模糊化应用程序(valid)和基线(afl)。使用gcov计算分支覆盖率[Stallman et al。2009年]。这些图显示了12个重复的分支覆盖的平均值和标准误差。
实验显示,在libpng(3%)和libjpeg-turbo(39%)的有效输入上,有效性模糊可调。对沃比斯来说,有效性反馈似乎没有任何影响。对于libxml,有效性模糊算法在有效输入中产生的分支覆盖率减少了30%。与其他处理二进制输入数据的基准测试不同,libxml期望有效的输入符合上下文无关的语法。对于这样一个领域,有效性模糊本身似乎是不够的。直观地说,使用字节级的突变来改变有效的XML文件并不一定有助于生成具有不同代码覆盖率的更有效的XML文件。通常,在libarchive上,特定于域的模糊化应用程序不是很有效。由于libarchive是用一个无效的输入进行种子设定的,所以在模糊化的头几个小时内生成的大多数输入都会导致假设失败。当然,有效性模糊算法依赖于有一些有效的输入,以使其领域特定的反馈有用。
有了fuzzfactory,我们能够快速地对有效的模糊算法进行验证,在这种情况下,它是否表现良好。注意,我们没有与Zest[Padhye et al。2019b],它结合了有效性模糊和参数生成器。因为这两种方法的区别在于,它和Java的启发式搜索不同。
接下来,我们描述一个众所周知的问题的新解决方案,即硬比较。回想一下图1中的移动示例,它需要生成相等的输入a和b。对于CGF,当遇到strncmp、memcmp和switch case语句时,也会出现类似的障碍。过去,几位研究者已经解决了硬比较的问题[LafIntel 2016;Li等人。2017;Peng等人。2018年;Rawat等人。2017年;Stephenset al。2016;Yun等人。2018年]。该问题的常见解决方案包括但不限于:(1)从已经满足大多数复杂不变量的种子输入开始,(2)从测试程序中挖掘出诸如0x0123-这样的magicconstants,然后将这些值随机插入变异过程中,(3)将测试程序转换为“展开”一个n字节比较一系列执行1字节比较的分支,以及(4)执行复杂的静态分析、动态污染分析或符号执行来识别和克服困难比较。一些解决方案,如静态挖掘魔术常数或展开多字节比较,不要对可变长度的参数进行硬比较,例如memcmp(a,b,n),其中所有操作数是从程序输入派生的。

我们展示了如何使用模糊工厂。我们不要依赖种子输入中的领域知识或昂贵的符号分析。表7描述了特定于域的模糊应用程序。其核心思想是为测试程序(K=L)中的每个比较操作提供特定于域的反馈,其中反馈表示被比较的两个操作数之间共同的比特数V=N。feedback是使用max reduce运算符聚合的;因此,如果新生成的输入最大化了在被测程序中任何硬比较操作中匹配的位数,那么它将被保存为一个分段点。表7接着描述了程序工具化策略。bin_expr、switch、target_program_loc、comm_位的定义见表2,插装策略如下:首先,在入口将DSF映射初始化为0点。那么,例如整数相等、字符串比较和switch case语句等操作都将被检测。插入的代码用操作数之间观察到的最大公共位计数填充与其程序位置相对应的DSF映射项。
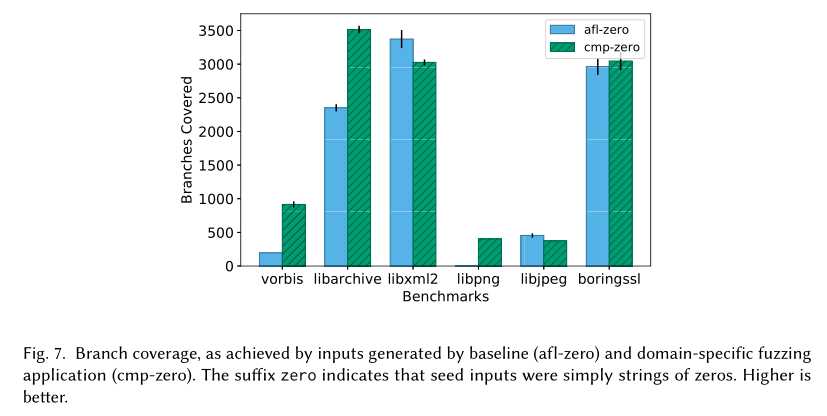
实验评价。图7包含了我们在基准程序上使用这个应用程序的实验结果。仅在这个实验中,我们不使用基准测试套件中提供的初始种子输入,而是使用一个包含零字符串的输入为所有模糊器种子。我们这样做是为了研究在不依赖种子中嵌入的特定程序知识的情况下,如何克服比较的困难。这个实验还模拟了一个场景,在这个场景中,人们希望模糊一个输入格式未知的程序,因此没有可用的种子输入。在24小时的模糊化运行之后,我们评估了特定领域的模糊化应用(cmp-zero)和基线(afl-zero)在分支覆盖率(由gcov计算)上的变化。后缀0表示这些实验没有使用有意义的种子输入。图中显示了12个重复的分支覆盖的平均值和标准误差。
从图中可以看出,cmpzero在四个基准测试中实现了比基线更高的代码覆盖率:vorbis、libarchive、libpng和boringssl。手工调查显示,这些程序期望它们的输入要么包含神奇的值,要么满足严格的不变量,这需要硬比较。在vorbis上,cmp前端实现了5倍以上的代码覆盖范围。开libpng,基线(aflzero)的性能尤其差,因为PNG图像格式要求在每个输入文件的开头有一个8字节的幻数;如果找不到这个幻值,测试程序会提前退出。cmp前端毫不费力地超越了这一艰难的对比,能够覆盖超过100×更多的分支。在libxml和libjpegturbo上,cmp前端似乎没有什么用处。在这些基准测试中,我们没有发现大小大于两个字节的操作数之间存在任何依赖于输入的硬比较。因此,基线方法就足够了。
现在我们描述fuzzfactory的另一个新应用:代码更改后的增量模糊化。
通常的做法是让模糊工具运行数小时或数天,以便发现复杂软件不稳定版本的错误。但是,如果开发人员对这样的软件进行了更改,那么目前还没有一种简单的方法可以快速地对更改进行模糊测试。他们可以使用软件上一个版本上长时间运行的模糊会话生成的测试语料库作为回归测试套件,但是这些输入可能不会执行受软件更改影响的代码路径。他们还可以用先前生成的输入语料库作为初始种子启动一个新的模糊会话。然而,他们无法与模糊引擎沟通,模糊引擎应该关注影响软件变更的代码路径。定向模糊工具,如AFLGo[B?hme et al。2017年]解决这个应用程序,但可能需要几个小时的静态分析来预先计算到目标程序位置3的距离。perfuick在这样的连续集成环境中可能不希望每次都使用这种连续的回归方法。
为此,我们提出并实现了一个特定于领域的模糊应用程序来进行增量模糊化。这个应用程序的目标是引导模糊化快速发现访问刚刚修改过的代码行的有趣的代码路径。我们将修改后的代码行集称为diff。为了测量输入执行的路径的多样性,我们将重点关注基本块转换(bbt),而不是仅关注基本块。

考虑图8a中给出的示例程序,该程序在第7行执行除法。在原始程序中,除数d总是输入a的倍数,所以第7行的除法总是安全的。不幸的是,对程序的新更改,它将2*a转换为2-a在第4行,使得被零除法成为可能。图8b显示了一些输入和通过这个程序的执行路径。执行路径表示为输入执行的bbt序列。我们使用?x,y?来表示从x行开始的基本块到从y行开始的基本块的转换。我们用符号?表示受差异影响的基本块的执行?。
考虑图8b中的三个输入,输入\(i_1(a=3,b=4)\)练习diff,而不是第7行的除法。输入\(i_2(a=4,b=4)\)在第7行练习除法,而不是在第4行练习diff。请注意,与输入i1和i2相比,输入\(i_3(a=4,b=3)\)没有使用新的bbt,因此常规的覆盖率指南fuzzing不会保存它。然而,输入i3是第一个在命中diff之后执行指向第7行的真正分支的代码。我们将命中diff后执行的bbt称为post diff BBTs;图8b中新执行的post diff bbt以蓝色突出显示。由于输入i3覆盖了一个新的post diffBBT,因此在增量模糊化设置中很有趣,因为它练习一个受diff变化影响的新代码路径。实际上,它与a=2,b=3只有一个突变,这将触发除数为0。
我们的FuzzFactory应用程序diff确保输入(如i3)保存为航点。它在DSF映射中填充diff代码执行后每个BBT的执行次数(即,它必须在?之后跟踪BBT)。例如,对于输入i1,sf映射是{?4,6?→1,?6,9?→1}。对于输入i2,DSF映射是{},因为输入i2没有遇到diff。最后,对于输入i3,DSF映射是{?4,6?→1,?6,7?→1}。

表8正式定义了增量模糊化域,并描述了仪器。自从我们跟踪基本块转换,而不是简单的基本块,K=L×L。为了更好地接近路径,DSF映射收集BBT执行计数的数量级聚合,类似于用于域有效性的聚合(参考第4.4节)。因此,\(A=2^N\),A 0=?,减径函数为\(a?v=a∪log_2(v)\)。为了跟踪bbt,仪器添加了一个全局变量p来跟踪先前访问的基本块的位置。p与当前块c组合以创建BBT元组?p,c?。这一点的灵感来自AFL的BBT跟踪逻辑[Zalewski 2017]。
为了确保我们只跟踪post diff bbt,工具还在测试程序中定义了一个新的全局变量hits_diff。此变量在测试入口点设置为false。在每个基本块上,指令插入都会添加一个检查,以查看基本块是否在_diff内—也就是说,基本块是在感兴趣的代码更改中添加或修改的,如果是这样,则将hits_diff设置为true。然后,BBT?p,c?的DSF只有在hits?p,c?为真时才会增加,有效地只计算差异后BBT。
实验评价。为了在我们的基准测试中模拟增量模糊化环境,而不需要挑选差异,我们执行以下过程。对于每个基准测试,我们在基准。这个是我们新的测试输入集,s0。为了找到一个相关的代码更改,我们将代码库提前一个git提交,直到我们找到一个差异,这个差异(1)影响主测试驱动程序中的代码,并且(2)由s0中至少一个输入执行。我们在提交历史中不断前进,并积累差异,直到找到这样的差异,或者直到最近一次提交。
为了评估持续集成环境中的效用,我们将每个工具运行5分钟。由于我们有兴趣评估工具在diff下游使用高codecoverage生成输入的能力,所以我们记录了在5分钟运行中命中diff的任何AFL生成的输入。在我们的覆盖率评估中,我们用这些来增加AFL的常规节省投入。
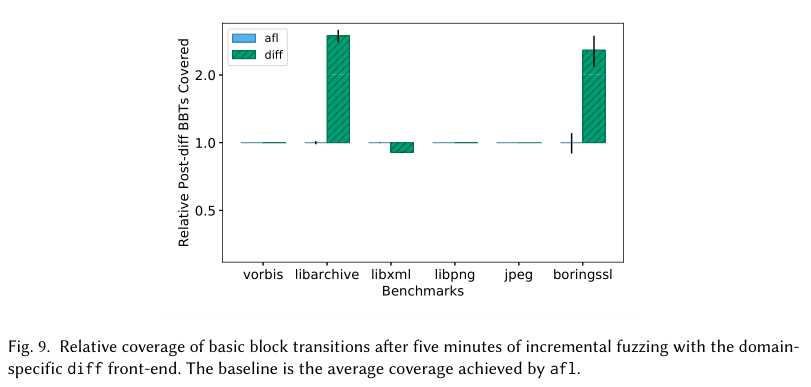
图9包含我们5分钟增量模糊化评估的结果。该图描绘了所有生成的输入所命中的差分后BBT数的相对于基线afl的标准误差。我们绘制了我们的领域特定的模糊应用程序(称为diff)相对于afl实现的覆盖率。对于libpng和libjpeg-turbo,我们的过程产生的diff会被起始语料库中的所有输入击中,而对于vorbis,种子语料库中没有任何输入一开始就击中了diff,这导致了非常大的diff。正如预期的那样,diff和afl同样成功地在这些基准上找到了各种diff后的行为。对于libarchiveand boringssl,只有少数输入达到了初始diff,并且diff不是很大。这些更紧密地反映了由我们的技术推动的渐进变化。对于这些基准测试,fuzzfactory领域特定的模糊应用程序diff在diff的下游覆盖率比afl高2.5-3倍。
由于特定领域的反馈映射和底层模糊算法之间的明确分离,我们可以很容易地在同一测试程序二进制文件中组合多个特定领域的模糊应用程序。组合两个特定于域的模糊应用程序只需要合并与每个域相关联的工具。我们的每个域的编译标志都是简单的。每个域的关联检测只更新自己的DSF映射。类似,我们的领域特定的模糊算法聚合从每个注册的域独立反馈(参考算法2)。
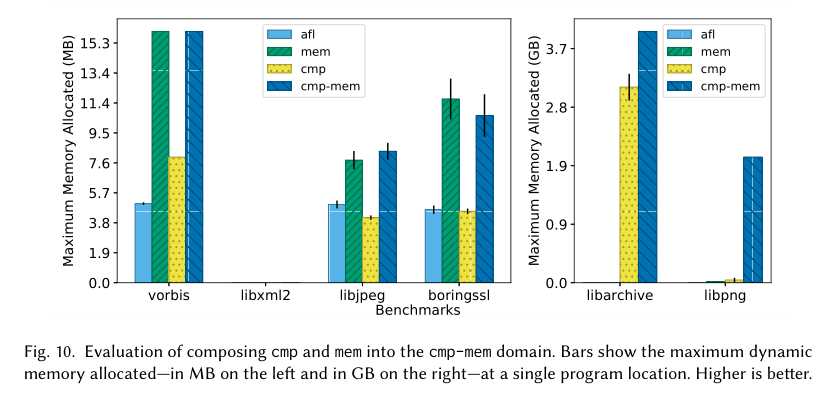
图10显示了我们用cmp(参考第4.5节)和MEM(参考第4.3节)组成的实验结果。这个实验的目标是在测试程序中最大限度地分配内存,同时平滑硬比较,这可能需要执行难以到达的程序分支。这个实验使用了基准测试附带的初始种子输入套房。我们比较复合结构域(cmp-mem)与基线(afl)以及每个独立应用(cmp和mem)。对于大多数基准测试,复合应用程序cmp mem生成的输入分配的内存比cmp或mem生成的内存多(或相等)。特别是,组合的cmp mem应用程序能够生成分别与libarchive和libpng-4GB和2GB一起分配最大内存的输入。对于libarchive来说,这个结果是显著的,因为mem域本身的性能比afl基线差得多,因为初始种子输入是无效的(参考4.3节)。然而,当与平滑硬比较的应用程序结合时,它能够快速生成有效的存档文件,并最终生成一个LZ4炸弹:一个小的输入在解码时会导致过多的内存分配。类似地,在libpng中,cmp mem应用程序能够生成PNGbomb。与mem单独发现的大多数内存分配输入不同,mem是在其元数据中声明非常大的几何尺寸的图像(参考第4.3节),cmp mem生成的PNG bomb利用pCAL/sCAL块的解码。这样的输入说明了一个众所周知的缺陷:在编码PNG文件时,简单地限制图像的几何尺寸并不会限制内存使用。我们可以得出这样的结论:cmp和mem结构域的组合比其各部分的总和更有效。
发现了新的错误。由于在我们的实验中使用的基准测试套件包含旧的,历史版本的严重模糊的软件,我们期望只找到以前已知的错误,如果有的话,在模糊化。令我们惊讶的是,我们发现cmp mem在对2017年1月libarchive快照进行模糊处理时保存的输入在最近(2019年3月)暴露了两个以前未知的错误版本:记忆泄漏4和意外的整数符号转换导致巨大的内存分配5。
我们的框架允许开发人员和研究人员通过定义一种策略来有选择地保存中间输入来控制模糊测试的过程。我们的框架目前没有提供任何显式的钩子到CGF算法中使用的各种其他搜索启发式方法,例如变异运算符或种子选择策略。原则上,应该可以移植通用的启发式方法,例如AFLFast中使用的启发式方法[B?hme et al。或FairFuzz[Lemieux and Sen 2018]或FairFuzz[Lemieux and Sen 2018]来处理本文中描述的各种特定领域的模糊应用程序。改进通用模糊启发式算法的工作与本文的工作是正交的我们的贡献主要贡献是提出了模糊算法和被测程序反馈选择之间的关注点分离。
理论上,代码覆盖率的基本增加本身可以被认为是特定于领域的反馈。那我们可以定义一个域d,当输入i导致执行S中没有任何输入覆盖的代码时,\(is_waypoint(i,S,d)\)满足。然而,在算法2中,我们总是在增加代码覆盖率的情况下保存一个输入,而不是通过另一个域来建模这个标准。在实践中,我们发现增加代码覆盖率对所有领域都是有用的,因为这会导致发现新的程序行为。换句话说,我们总是用一个试图最大化代码覆盖率的默认域组合每个自定义域。如果需要,我们的实现允许通过环境变量禁用默认域。
自从我们完成本文的实验以来,甚至出现了更专业的适合我们抽象的路径点的模糊器:例如(1)Coppik等人。[2019]将读/写新值的输入保存到输入相关内存地址,以及(2)Nilizadeh等人。[2019]通过保存执行路径与参考路径最大不同的输入,发现侧信道漏洞。我们对这样的工作感到鼓舞,因为它加强了模糊工厂的理由。
我们实现了FuzzFactory作为AFL的扩展。在FuzzFactory中,特定领域的模糊应用程序是通过插入测试程序来实现的。表1描述了实现本文描述的六个域中的每一个所需的代码行。在我们的应用程序中,我们使用LLVM执行检测。然而,测试程序也可以使用任何其他工具来检测,比如英特尔的Pin[Luk等人。2005年]。事实上,特定领域的模糊应用程序可以通过手动编辑测试程序来添加调用FuzzFactoryAPI的代码来实现。接下来我们将描述这个API。

图11概述了FuzzFactory提供的API。类型dsf\t定义域特定映射的类型。在我们的实现中,键和值总是32位无符号的整数。但是,用户可以指定DSF映射的大小;也就是说,它将指定的键数包含。TheAPI函数new_domain注册一个新域,其密钥集K包含key_size密钥。
参数reduce和a_0分别提供reducer函数(intxint->int类型)和初始聚合值。对于慢速域,key_size为1。对于Kis是一组程序位置L的应用程序,我们使用2 16的密钥大小,并将16位伪随机数分配给基本块位置,类似于AFL。对于增量模糊应用,其中K=L×L,我们使用哈希函数将两个基本块位置组合成一个整数值密钥。集合V和A是通过使用DSF映射和reduce函数的实现来隐式定义的。对于有效性模糊等应用,其中A是一个数量级的集合,我们使用位向量来表示集合。
函数new_domain返回DSF映射的句柄,然后在图11中列出的后续tap中使用该句柄,例如DSF_increment。在执行任何测试之前,在测试程序启动时插入对新_域的调用。用户需要确保提供的reducerfunction满足属性1和2,这反过来又保证了单调聚合(定理1)。以“dsf”开头的API函数操作dsf映射。参数键必须在范围[0,key_size)中。
据我们所知,FuzzFactory是实现特定领域的模糊应用程序的第一个框架。JQF【Padhye等人。2019a]允许用户为Java实现定制的模糊算法;但是与FuzzFactory不同的是,检测是固定的,而搜索算法可以定制。基于LLVM的CLAN编译器[LATTER和ADVE 2004 ]提供了C/C++程序可扩展的跟踪框架。通过使用诸如fsanitize coverage之类的命令行标志,可以让Clang检测基本块和比较操作来调用特殊命名的函数;用户可以链接这些函数的自定义实现来跟踪程序的执行。LibFuzzer[LLVM Developer Group 2016]使用这些钩子来提供测试程序的反馈,以执行覆盖率引导的模糊化。但是,libFuzzer没有提供一种机制,用定制的聚合函数提供特定于域的任意反馈。也就是说,虽然LLVM为程序的执行提供了钩子,但是目前还没有办法将信息传递给fuzzing算法。然而,使用llvm的跟踪钩子来调用FuzzFactory的API进行特定领域的模糊化相对容易。
根据maneès等人的调查,模糊测试领域的许多研究都以搜索过程中的通用改进为目标。[2018年]。这些技术通常适用于模糊化算法中的各种启发式方法[B?hme et al。2016年;Chen和Chen 2018年;Lemieux和Sen 2018年),orseek将模糊测试与重量级方法相结合,如concolic execution[Ognawalaet al。2018年;Stephens等人。2016;Yun等人。2018年]。我们提出的设计和这些技术中的任何一个都不冲突。对模糊化过程的通用调整可以应用于算法2,而不会影响收集特定领域反馈的机制。
结构化模糊工具,如protobuf mutators[serebyany等人。2017年),AFLSmart[Phamet al。2018年),鹦鹉螺[Aschermann等人。2019年),Superion[Junjie Wang and Liu 2019]利用了与被测程序预期的输入格式相关的领域特定信息。这种方法可以与第4.4节中介绍的有效性模糊域相结合,以克服我们在XML等格式中观察到的局限性[Padhye et al。2019b年]。
我们提出了FuzzFactory,一个实现特定领域模糊化的框架应用程序。我们的框架提供了一种机制,用于在被测程序执行期间与模糊引擎通信、任意特定于域的反馈。我们对六个前端的实验表明,FuzzFactory可以用来原型领域特定的应用程序,而不需要改变底层的搜索算法。特定领域反馈的有效性取决于测试程序的性质、目标和初始种子输入。我们希望,我们提出的框架将使研究人员能够快速开发出高度专业化的领域专用解决方案,并推动最新技术的发展。
运行论文提供的代码需要LLVM/Clang 6+,Ubuntu18.04安装可参考ubuntu18.04编译安装clang/llvm
安装完成后可根据代码read.me
cd FuzzFactory-master
make以构建FuzzFactory的自定义“afl-fuzz”
然后make llvm-domains 构建FuzzFactory基于LLVM的特定于域的检测
之后就可以根据需要进行slow, perf, mem, valid, cmp, diff的检测
或者
使用代码附带的demo进行实验
具体如下:
cd demo
../afl-clang-fast demo.c -o demo
WAYPOINTS=mem ../afl-clang-fast demo.c -o demo
WAYPOINTS=cmp ../afl-clang-fast demo.c -o demo
WAYPOINTS=cmp,mem ../afl-clang-fast demo.c -o demo
../afl-fuzz -p -i seeds -o results ./demo
20199126 2019-2020-2 《网络攻防实践》实践
标签:开头 运行 反馈 res rgs 依赖 搜索 ip) 限制
原文地址:https://www.cnblogs.com/fuhara/p/13246485.html