标签:cut 反序列化 work 联系 用户态 用户 src gfs 记录
我看的论文是Fuzzing File Systems via Two-Dimensional Input Space Exploration,本文发表在IEEE Symposium on Security and Privacy 2019,第一作者Wen Xu,导师Taesoo Kim,本文作者主要从事二进制安全的相关研究。
文件系统是操作系统的基本系统服务和重要组成部分。大部分的文件系统,如ext4,XFS等都是运行在内核中的,因此文件系统中的bug可能会给系统造成巨大的危害。为了自动发现这些潜在的错误,大多数开发中的文件系统都依赖于已知的压力测试框架(xfstests, fsck等),主要通过完整性检查,需要对文件系统和操作系统状态都有深刻的了解。由于现代操作系统的复杂性越来越高,这现在不切实际。另一方面,大多数已验证的文件系统在实践中太不成熟。近年来,随着模糊测试(Fuzzing)技术的发展和使用,研究人员发现,该技术是一个自动化挖掘各类文件系统漏洞的一个有效且实用的方法。
通常来说,Fuzzing一个用户态程序时,Fuzzer只关注这个程序的输入数据;而Fuzzing 操作系统内核时,Fuzzer主要关注在内核执行的一系列系统调用(System Call);与上述两类场景的不同之处,Fuzzing文件系统需要同时关注两个维度的输入,一是文件系统镜像,二是一系列的文件操作(workloads)。现有的Fuzzer都只关注了上述两个输入维度中的某一个维度,而且都存在一些局限性。
当前的模糊器存在的挑战:
处理文件系统镜像作为输入: 一方面,文件系统镜像的大小远远大于普通用户态程序输入的大小,这导致Fuzzer处理输入的开销大大增加;另一方面,在一个文件系统镜像中,一般只有其中的元数据(metadata)会对文件系统的操作产生影响,普通的文件数据是无用的,而metadata只占整个文件系统镜像的1%左右,这导致Fuzzer对输入的突变操作可能大部分是无效的。此外,文件系统镜像中还有会用一些checksum来校验metadata,这进一步增加了Fuzzing的难度;
生成Context-sensitive的workloads: 有效的文件操作应该是基于运行时的文件系统的实际状态的,而传统的生成workloads的方法只和文件系统的初始状态有关,和上下文操作无关,workloads的部分操作可能是无效的。因此在生成workloads的过程中,必须维持文件系统的状态,基于之前的状态来生成新的文件操作;
在两个维度探索输入空间: 文件系统的行为依赖于这两个维度的输入,并且文件操作和文件系统镜像之间是存在联系。Fuzzer需要同步的对这两种输入进行fuzz,而不像一般的Fuzzer那样只考虑一种形式的输入。
重现Crash: 传统的针对操作系统的Fuzzer为了避免重置系统状态导致的巨大开销,在运行不同的workloads时,会复用之前的系统实例,这会使得在长时间运行后系统的行为变的不可靠,从而使得很多crash不可被复现;
定义:模糊测试 (fuzz testing, fuzzing)是一种软件测试技术。Fuzzing技术本质是依赖随机函数生成随机测试用例。其核心思想是自动或半自动的生成随机数据输入到一个程序中,并监视程序异常,如崩溃,断言(assertion)失败,以发现可能的程序错误,比如内存泄漏。模糊测试常常用于检测软件或计算机系统的安全漏洞。
测试用例类别
随机数据
缓冲区溢出类测试用例:超长字符串。比如几时上百个a,也可以更长只要自己觉得足够长就行。超长字符串一般是等价的不需要a来一串b来一串什么的,来两三个长度差别稍微大的测试用例就行了。
随机数测试用例:很多系统支持的配置值是固定的,比如屏幕只支持1080p我们故意设1081p系统就可能把错了。负数,浮点数,超大数等分别来个测试用率就行了。
格式化字符串测试用例:%d、%s等符号在很多语言中是指导格式化用的,如果用做做为输入可能引发报错。长长短短随便来几个测试用例就行了。
特殊字符测试用例:~!@#$%等等符号在很多语言中是有特殊含义的,作为输入可能会引发报错。最好每个字符及不同长度都来一个测试用例。
unicode编码测试用例:有些程序是不支持unicode的,输入unicode可能会引发报错。%uxxxx等长短不一来几个测试用例。
磁盘文件系统具有二维输入空间:(1)结构化文件系统映像格式; (2)用户调用以访问存储在已安装映像上的文件的文件操作。模糊测试工具通用的模糊测试基础结构如下。
磁盘映像是一个较大的结构化二进制Blob(图像中的一块连通区域),这个blob具有用户的数据和管理结构,称为元数据,它主要用于文件系统需要访问、加载、恢复和搜索数据,或者满足文件系统的其他特定要求。如下图,是一个ext4映像的磁盘布局,灰色块表示正在使用的元数据,仅占图像大小的1%,其中一些(包括扩展树节点,目录条目和日志块)散布在图像中,而其他一些(例如,超级块,组描述符等)则位于开头:

(1)较大的输入大小会导致输入空间探索呈指数增长。同时,重要的元数据很少被突变。 (2)模糊器对输入文件执行频繁的读取和写入操作。对磁盘映像进行模糊处理时,它会在更改期间重复读取,在更改之后重复写入,并在必要时保存该映像。结果,较大的磁盘映像大小会减慢基本文件操作的速度,从而导致巨大的性能开销。 (3)最后,为了检测元数据损坏,一些文件系统(例如XFS v5,GFS2,F2FS等)引入了校验和以保护磁盘元数据。
由于文件系统是操作系统的一部分,因此对文件系统进行模糊处理的一般方法是调用一组系统调用。尽管将这些模糊器移植到目标文件系统操作非常简单,但是由于两个原因,它们无法有效地模糊文件系统:
文件操作只修改文件对象(例如目录、符号链接等) 存在于图像上,完成的操作会影响特定的对象。然而,现有的OS模糊器不考虑图像和文件操作之间的动态依赖,因为它们盲目地生成系统调用,这些调用肤浅地探索文件系统。例如,最先进的OS模糊器,Syzkaller, 根据描述每个参数的数据类型的静态语法规则生成系统调用,并为每个目标系统调用返回值。
现有的OS模糊器主要使用虚拟化实例(例如KVM、QE MU等。)为了性能起见,在不重新加载操作系统或文件系统的新副本的情况下运行目标操作系统。不幸的是,与老化的操作系统或文件系统混淆有两个问题:(1)在处理大量系统调用后,老化操作系统的执行变得不确定。例如,依赖于先前分配的kmalloc()在运行时表现不同。 有
大多数模糊器要么模糊二进制输入,要么使用一系列系统调用来模糊操作系统。然而,为了模糊文件系统,我们需要变异两个输入:(1)二进制图像(即文件系统图像)和(2)相应的工作负载(即一组文件系统特定的系统调用)。Syzkaller试图通过在图像中变异非零块来实现这两个目标,同时独立生成上下文不感知的工作负载来测试突变的图像,这仍然是不健全和无效的。
JANUS的设计架构图
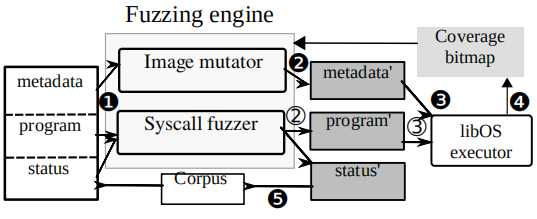
JANUS的大致过程:JANUS的设计架构 JANUS的一个测例有三部分构成:元数据(metadata),一系列文件操作(program or workloads),文件系统的状态(status)。和其他Fuzzer一样,JANUS接受若干个文件系统镜像作为seed input。
首先JANUS会根据不同类型的文件系统,对输入的镜像进行解析,从中定位并提取出对应的metadata,并得到文件系统的初始状态status,然后生成一个打开文件的文件操作作为初始的program,并更新program运行后的文件系统的可能状态为新的status。对seed input的解析结果构成一个集合(Corpus)。
之后从Corpus挑选出一个测例进行mutate。Metadata由Image mutator进行fuzz,生成新的metadata’;program交由Syscall fuzzer基于status进行fuzz,生成新的program’,以及对应的新状态status’。
接着,JANUS会将metadata’,组装成一个完整的文件系统镜像,并重新计算相应的checksum。然后由一个用户态的操作系统执行器,挂载这个镜像,并执行program’,并把执行情况返回给引擎,如果这个测例是有价值的,比如其会使程序执行一条之前未被执行到的路径,则这个测例会被加入到Corpus,否则这个测例将被抛弃。
最后,这个执行器每次运行新的program前都会重置,确保系统状态不受之前操作的影响。
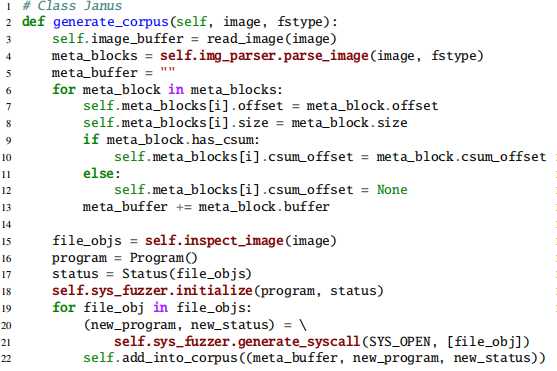
首先将整个图像映射到内存缓冲区。然后,特定于文件系统的图像解析器将扫描图像,并根据所应用文件系统的规范找到所有磁盘上的元数据。 JANUS将这些元数据重新组合成一个缩小的Blob,以便随后进行突变,并记录其大小和图像内偏移。对于任何受校验和保护的元数据结构,JANUS会记录由图像解析器识别的校验和字段的元内偏移。其次,开始的测试用例还包括映像上每个文件和目录的信息,使JANUS可以使用该知识来随后生成上下文感知的工作负载。特别是,系统调用模糊器探测种子图像并检索其上每个文件对象的路径,类型(例如,普通文件,目录,符号链接,FIFO文件等)和扩展属性,这些文件对象打包到每个文件中。初始测试用例。而且,每个初始测试用例都包含一个启动程序,该程序具有一个由系统调用模糊器生成的用于突变的独特系统调用。为了扩大语料库的整体覆盖范围,每个随机生成的系统调用都会操作一个唯一的文件象。种子图像的元数据和文件状态以及启动程序一起构成了一个输入测试用例,由JANUS打包并保存到磁盘上的语料库中,以供将来进行模糊处理。
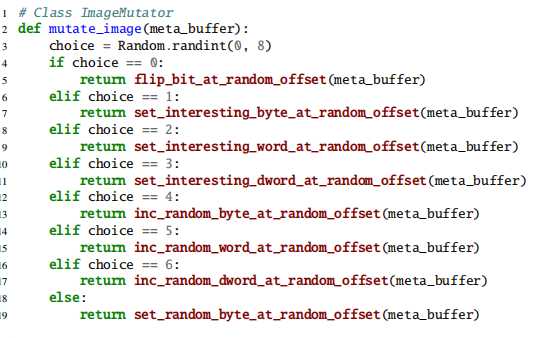
JANUS依靠图像转换器对图像进行模糊处理。尤其是,图像转换器会加载测试用例的元数据块,并应用几种常见的模糊策略(例如,位翻转,对随机字节的算术运算等)来随机变异元数据的字节。JANUS希望使用一组特定的整数(即,图4)(例如-1、0,INT_MAX等),而不是纯随机值来突变元数据。在我们的评估中,这些特殊值使图像转换器能够产生更多的极端情况,这些情况无法由文件系统正确处理(例如,错误#1,#6,#14,#28,#33等表六 由JANUS发现)以及更多极端情况,这些情况会增加崩溃时内核通过在运行时触发特定的bug的可能性(例如,JANUS发现的大多数外部访问bug)。在对整个元数据blob进行突变后,JANUS将blob中的每个元数据块复制回到其在内存缓冲区中的相应位置。为了保持图像的完整性,图像解析器通过遵循目标文件系统采用的特定算法来重新计算每个元数据块的校验和值。
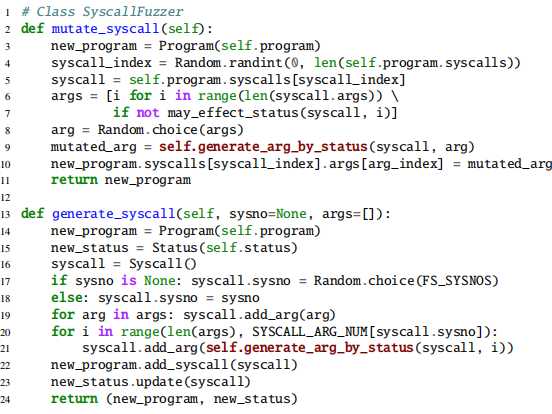
与现有的模糊器(例如Syzkaller)类似,系统调用模糊器以两种方式从输入程序生成新程序:(1)Syscall突变。系统调用模糊器在程序中随机选择一个系统调用,并生成新值列表以替换随机选择的参数的旧值; (2)Syscall生成。系统调用模糊器将新的系统调用追加到程序,该程序的参数具有随机生成的值。JANUS采用Syzkaller用来为系统调用的平凡参数生成值的相同策略。这些参数的候选值与我们推测的运行时状态无关。对于任何具有明确定义的可用值集的参数,JANUS会从该值集中随机选择值。 (例如,lseek()的int来源)。此外,JANUS会为整数类型的参数生成某个范围内的随机数(例如,write()的size_t count)。此外,许多文件操作需要指针类型的参数。这样的指针通常指向一个缓冲区,该缓冲区用于存储用户数据(例如,voidbuf用于写())或内核输出(例如,voidbuf用于读())。对于前一种情况,系统调用fuzzer声明一个数组,其中包含参数的随机值。在后一种情况下总是使用固定数组,因为JANUS不受运行时内核输出的驱动,除了其代码覆盖。
但是,对于那些适当值取决于文件系统的运行上下文的非平凡参数,JANUS不仅根据其预期类型,而且更重要的是,根据我们的维护状态,通过遵循以下三个规则来生成其值:(1)如果需要文件描述符,则系统调用模糊器会随机选择一个打开的适当类型的文件描述符。例如,write()需要一个普通的文件描述符,而getdents()需要一个目录的文件描述符; (2)如果需要路径,系统调用模糊器将随机选择现有文件或目录的路径,或由最近操作删除的陈旧文件或目录的路径。例如,JANUS提供了一个普通文件或目录的路径来重命名(),但仅提供了rmdir()所需的有效目录的路径。如果该路径用于创建新文件或目录,则JANUS可能还会随机生成一个位于现有目录下的全新路径; (3)如果系统调用操作了特定文件的现有扩展属性(例如getxattr()和setxattr()),则系统调用模糊器将随机选择记录的文件扩展属性名称。
对于新生成的系统调用,JANUS将其附加到程序中,更重要的是,总结系统调用对文件系统造成的潜在更改,并更新推测状态 相应的图像。例如,open(),mkdir(),link()或symlink()可能会创建一个新文件或目录,而open()还引入了一个活动文件描述符。 rmdir()或unlink()从映像中删除文件或目录; named()更新文件的路径,setxattr()或removexattr()更新特定的扩展属性。JANUS在完成程序执行后仅保留推测的图像状态。因此,JANUS避免了对现有参数的任何突变,从而不会导致图像状态发生潜在变化。
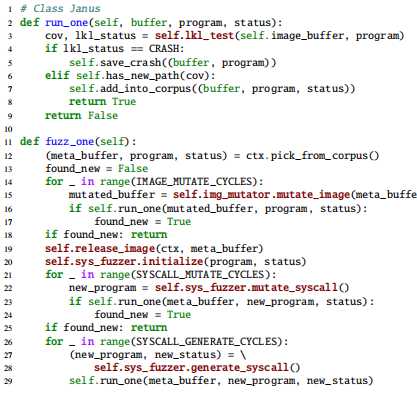
为了同时模糊元数据和系统调用,JANUS依次安排了两个核心模糊器具体来说,对于包含缩小图像和程序的输入测试用例,JANUS首先启动图像转换器,以对缩小图像上的随机字节进行突变。如果在未更改的程序中未发现新的代码路径,则JANUS会调用系统调用模糊器以在某些回合中更改程序中现有系统调用的参数值。如果仍然没有探索新的代码路径,JANUS最终会尝试将新的系统调用追加到程序中。注意,每个模糊阶段的回合都是用户定义的。
为避免使用会导致执行不稳定和无法再现的错误的老化OS或文件系统,JANUS依靠基于库OS的应用程序(即执行程序)来模糊OS功能。具体而言,JANUS派生一个新的执行器实例,以测试来自模糊引擎的每个新生成的图像和工作负载。
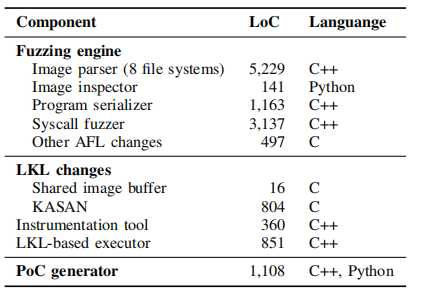
Image parser :图像解析器和图像转换器。我们将图像解析器实现为动态库,以定位元数据并识别种子图像上的校验和。当前,映像解析器支持解析Linux上八个广泛使用的文件系统的磁盘映像,包括ext4,XFS,Btrfs,F2FS,GFS2,HFS +,ReiserFS和VFAT。
Image inspector:图像检查器,在种子图像上迭代文件和目录,并记录它们的图像中路径,类型和扩展属性以构建初始测试用例。
Program serializer :程序序列化器。我们以可序列化的格式描述新生成的程序和更新的状态。序列化程序将它们从磁盘加载到内存中进行模糊和测试,并将它们从内存中保存到磁盘中进行簿记。
Syscall fuzzer :系统调用模糊器被实现为AFL的新扩展,当图像突变无法取得进展时,JANUS会调用它。系统调用模糊器接收反序列化的程序和相应的状态,并通过系统调用突变或系统调用生成来输出新程序和更新的状态。
LKL-based executor:我们在Linux内核库(LKL)上构建JANUS的执行程序,这是一个典型的库OS,它将内核接口公开给用户空间程序。
JANUS在上游Linux内核中八个广泛使用的文件系统中发现的错误
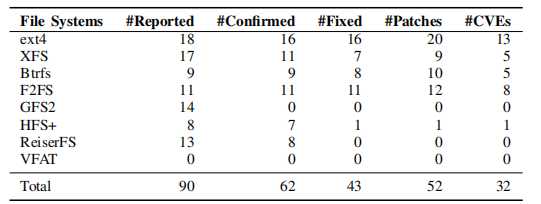
JANUS发现了90个独特的错误,这些错误导致内核崩溃或死锁,我们向Linux内核社区报告了这些错误。我们根据KASAN报告和调用堆栈跟踪来区分错误。其中,开发人员确认了62个以前未知的错误,包括ext4,XFS和Btrfs中的36个错误-这是Linux上使用最广泛的三个文件系统。到目前为止,开发人员已经修复了带有52个不同补丁的43个错误,并分配了32个CVE JANUS发现了90个独特的错误,这些错误导致内核崩溃或死锁,我们向Linux内核社区报告了这些错误。我们根据KASAN报告和调用堆栈跟踪来区分错误。其中,开发人员确认了62个以前未知的错误,包括ext4,XFS和Btrfs中的36个错误-这是Linux上使用最广泛的三个文件系统。到目前为止,开发人员已经修复了带有52个不同补丁的43个错误,并分配了32个CVE.
在四个月内与JANUS合作。根据我们的调查,Syzkaller报告在评估期间仅报告了两个ext4错误,一个XFS错误,四个F2FS错误和一个HFS +错误,其中JANUS也发现了ext4错误之一,XFS错误和HFS +错误.
JANUS在上游内核中被广泛使用的成熟文件系统中成功发现了90个错误。其中有62个错误已被确认为以前未知。作为文件系统的专业模糊测试工具,JANUS在最近几个月帮助Linux内核社区发现和修补了比Syzkaller更多的文件系统错误。
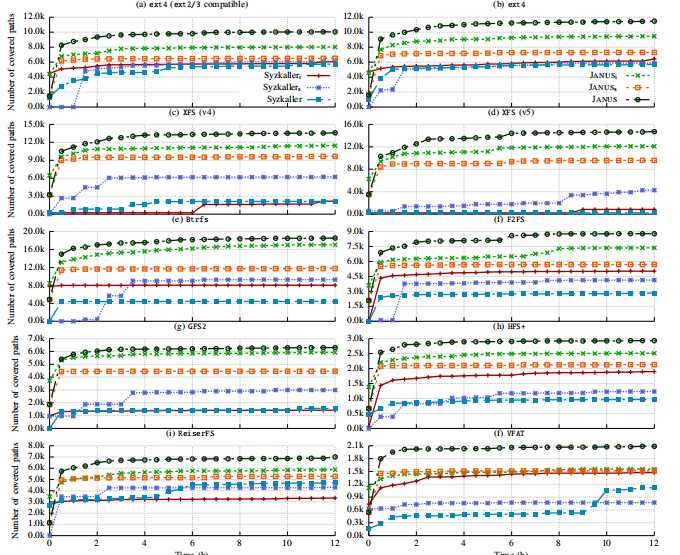
探索图像的状态空间
通过改变元数据块和固定校验和,JANUSi在选择的文件系统中快速探索比Syzkalleri更多的代码路径,当只对具有固定文件操作的图像进行模糊处理时。更具体地说,JANUSi比Syzkalleri实现了最多4.17×更多的代码覆盖,这表明了JANUS只对图像进行模糊处理时的有效性。
探索文件操作
通过仅生成与上下文相关的工作负载,JANUS在仅针对与文件操作相关的系统调用时,在所有八个流行文件系统中都比Syzkallers探索了更多的代码路径。
探索二维输入空间
为了通过改变图像字节和文件操作来证明JANUS模糊测试的全面性,我们在具有相同种子图像的上述八个文件系统上运行原始JANUS和Syzkaller 12小时,我们观察到,与JANUSi和JANUS相比,JANUS发现更多的代码路径。我们的结果说明了对图像和文件操作进行模糊处理以全面探索文件系统的重要性。更重要的是,JANUS在所有经过测试的文件系统上的性能均优于Syzkaller。
对于每个目标文件系统,我们为Syzkalleri启动一个JANUSi实例和一个KVM实例。因为Syzkalleri仅将图像的重要部分视为非零块的数组,这些块可能会丢失元数据块,甚至可能包含无关紧要的数据块。相反,JANUSi利用图像的语义,即仅定位和变异元数据块。此外,GFS2和Btrfs都具有元数据块的校验和,这严重降低了Syzkalleri的性能。
由于使用老化的OS的基本限制,Syzkaller会在不初始化的情况下挂载不同的映像并调用系统调用,因此Syzkaller无法重现其发现的任何崩溃。相反,JANUS可以重现除Btrfs以外的大多数文件系统中超过95%的崩溃。 Btrfs启动多个内核线程以并行方式完成不同的事务,从而导致不确定的内核执行。
例如,JANUS不能通过修改LKL模糊文件系统的DAX模式(直接访问)。
对于开发人员来说,调试崩溃的理想PoC包括仅具有基本错误字节的映像和具有最少文件操作的程序。为了实现这一点,JANUS当前使用蛮力方法来还原每个突变的字节,并且还尝试删除每个调用的文件操作,以检查内核是否仍在预期的位置崩溃。
一开始并不是选择的这篇
标签:cut 反序列化 work 联系 用户态 用户 src gfs 记录
原文地址:https://www.cnblogs.com/w741741/p/13246575.html