标签:丢失 遇到 color 关系 spark mat code 就是 map
整个计算链可以抽象为一个DAG(有向无环图) Spark 的 DAG 作用:
记录了RDD之间的依赖关系,即RDD是通过何种变换生成的,
如下图:RDD1是RDD2的父RDD,通过flatMap操作生成 借助RDD之间的依赖关系,可以实现数据的容错,
即子分区(子RDD)数据丢失后,可以通过找寻父分区(父RDD),结合依赖关系进行数据恢复
综上,RDD(弹性分布式数据集)
①分区机制
②容错机制(借助RDD之间的依赖关系容错) 即使用Spark 框架处理数据,把数据封装为RDD,然后通过高阶函数来处理

以上的执行过程如下:
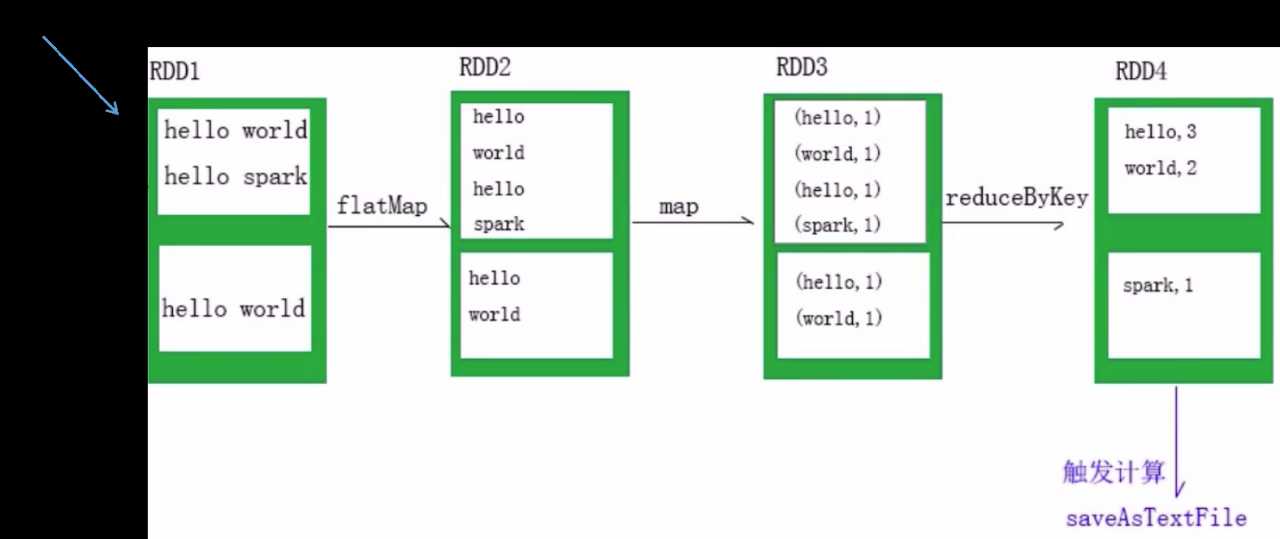
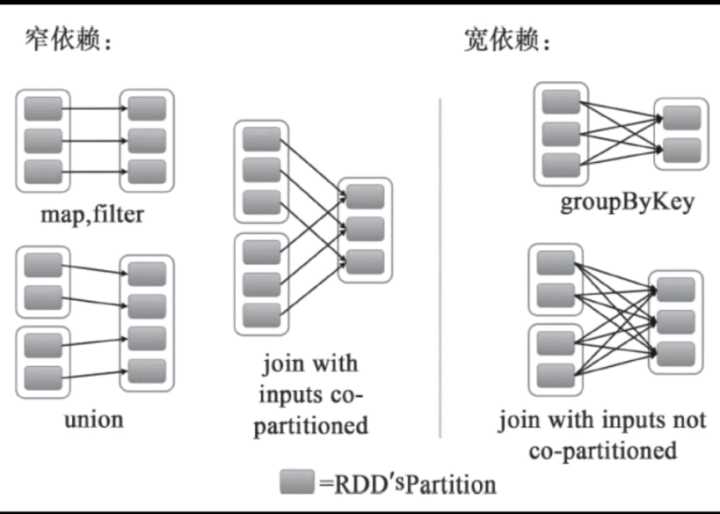
依赖关系有两种:
①窄依赖:父分区和子分区是一对一关系,没有shuffle,即不会发生磁盘I/O,所以执行效率很高,
如果DAG中存在多个连续的窄依赖,会放到一起执行,这种优化方式称为流水线优化
②宽依赖:父分区和子分区是一对多关系,会发生shuffle过程,会发生磁盘I/O。所以Spark框架并不是完全基于内存的,
也是要依赖于磁盘的。但是已经尽力避免产生shuffle
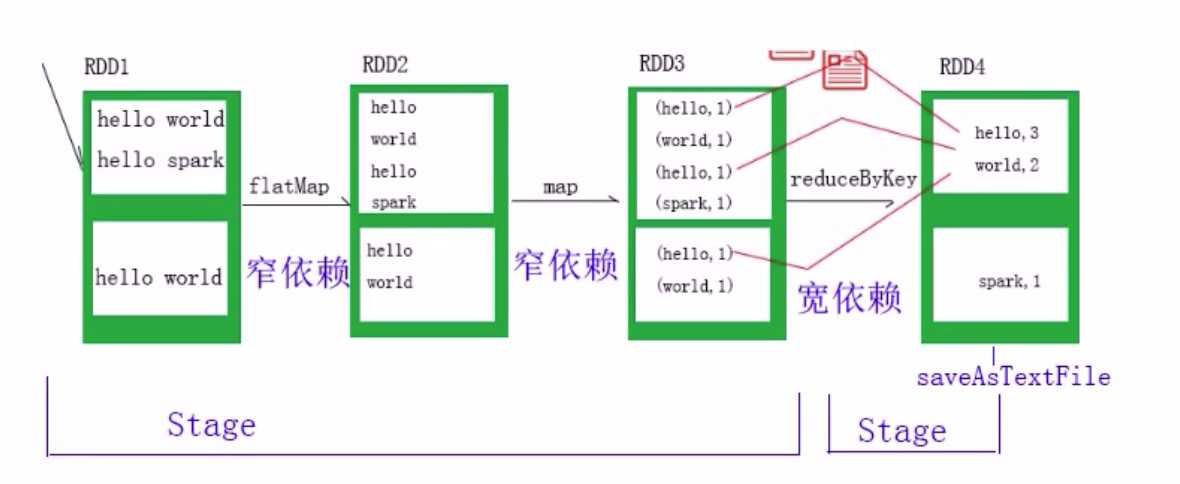
Stage(阶段) -> 一组Task集合
Task任务对应的是分区,即一个分区就是一个Task,但是要注意:多个连续的窄依赖,会放到一起执行 作为一个Task,宽依赖按照不同的分区
标签:丢失 遇到 color 关系 spark mat code 就是 map
原文地址:https://www.cnblogs.com/alen-apple/p/13246504.html