标签:部分 描述 缓存 调用 编译器 状态 预处理 bsp nbsp
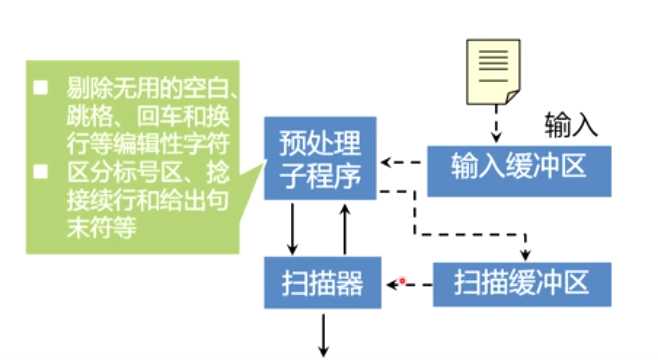

起点指示器:指向单词的开始位置
搜索指示器:从起点指示器开始,寻找单词的末尾
一个实现问题:可能单词很长,导致前半部分在缓冲区中,后半部分不在其中
此时,若搜索指示器扫描到缓冲区结尾,仍未找到单词的结束,会触发对预处理子程序的调用,会清空缓存区,但这会导致前半部分丢失
方法:1.提升缓冲区大小--->指标不治本
2.缓冲区一分为二,两半区互不使用,当读到缓冲区末尾仍然找不到单词,调用预处理子程序,将结果送入另一个缓冲区就可以了
单词的最大长度是小缓冲区的长度
如某种语言规定标识符最长为256,故缓冲区的总长度为512
超前搜索是很难处理的,所以加了一些限制,以避免这个问题

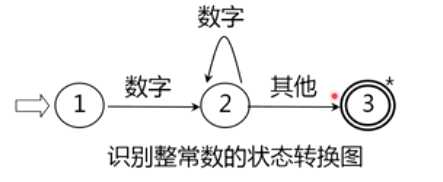
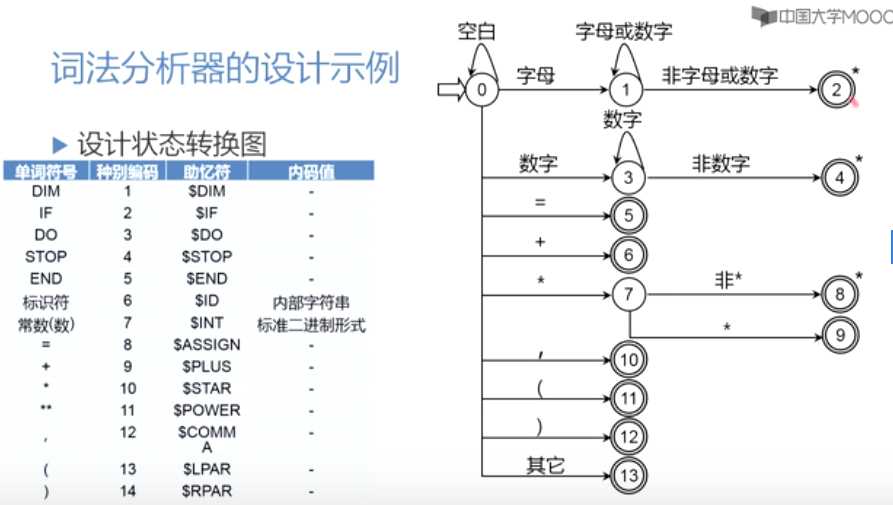
为了方便描述状态转换,使用状态转换图,如下
标签:部分 描述 缓存 调用 编译器 状态 预处理 bsp nbsp
原文地址:https://www.cnblogs.com/caishunzhe/p/13253908.html