标签:博文 log use image 逻辑 随机 war pen user
一个 Locust 测试脚本就是一个普通的 python 文件,它的基本组成十分简单:
定义用户的类型
所有用户的属性都需要继承自 User Class,我们最常用的 HttpUser 也是如此,你也可以定义一个如 TcpUser,或者 WebSocketUser,甚至基于你测试的业务系统来做一个,例如 QQUser,但是最终都必须继承至 User Class,类似于过去 LoadRunner、Jmeter 的选择应用的通讯协议或选择请求插件
等待时间的方法
声明一个等待时间的方法,用于确定模拟用户在任务之间执行的等待停留时间。Locust 附带了一些内置函数用于返回等待时间的方法,包括:1、between:在指定范围内的随机;2、constant:基于响应到下一次请求之间的固定的等待时间;3、constant_pacing:基于请求到下一次请求的固定间隔时间
主机属性
用于定义测试的主机信息,比如 http://www.cnblogs.com,如果在脚本中没有定义,那在命令行启动测试或 WebUI 中将作出定义
任务属性
用于定义任务的执行逻辑,你可以定义多个任务,让模拟的用户按照不同任务的权重配置随机执行,也可以让任务按照你的编排顺序执行
我们采用循序渐进的方式来,你不需要特别关注下面的每个范例所具备的实际意义,只需要关心脚本的结构
1、先按照最基本的脚本结构写一个范例
from locust import user, task, between
class MyUser(User):
@task
def my_task(self):
print("executing my_task")
wait_time = between(5, 15)
脚本实现:
把它保存为 locustfile.py,然后执行
locust -f locustfile.py
然后在本地浏览器访问 http://localhost:8089/,在“Start new Locust run”页面
点击“Start swarming”,可以命令行中看到返回:
PS E:\study.locust> locust -f .\locustfile.py
[2020-07-06 09:14:01,726] DESKTOP-FOCB2DV/WARNING/locust.main: System open file limit setting is not high enough for load testing, and the OS wouldnt allow locust to increase it by itself. See https://docs.locust.io/en/stable/installation.html#increasing-maximum-number-of-open-files-limit for more info.
[2020-07-06 09:14:01,726] DESKTOP-FOCB2DV/INFO/locust.main: Starting web interface at http://:8089
[2020-07-06 09:14:01,734] DESKTOP-FOCB2DV/INFO/locust.main: Starting Locust 1.1
[2020-07-06 09:14:11,992] DESKTOP-FOCB2DV/INFO/locust.runners: Hatching and swarming 10 users at the rate 10 users/s (0 users already running)...
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
executing my_task
功能实现:
2、把这个脚本修改为访问我的博客:)
import random
from locust import HttpUser, task, between
class cnblogUser(HttpUser):
wait_time = between(5, 10)
@task(2)
def open_blog(self):
self.client.get("/huanghaopeng/")
@task(1)
def open_links(self):
self.client.get("/huanghaopeng/p/13100305.html")
self.client.get("/huanghaopeng/p/13220749.html")
self.client.get("/huanghaopeng/p/13187807.html")
def on_start(self):
self.client.get("/")
脚本实现:
把它保存为 locust_cnblogs.py,然后执行
locust -f locust_cnblogs.py
在 Web UI 中填入模拟用户数、加载速率、以及博客园的 Host 信息 https://www.cnblogs.com/huanghaopeng/
点击“Start swarming”,可见:
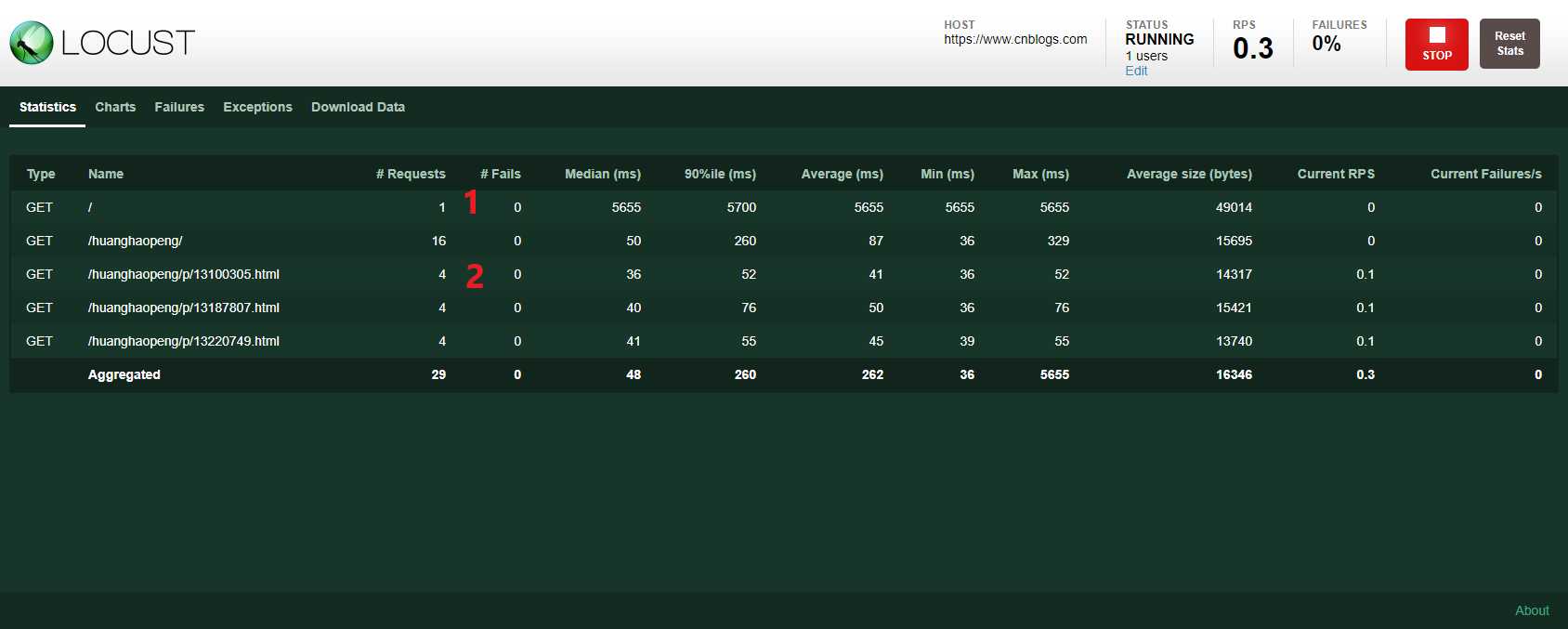
从上面的运行情况可以发现
现在我们对这个脚本进行一些修改,让它更像一个真实的用户访问行为:
标签:博文 log use image 逻辑 随机 war pen user
原文地址:https://www.cnblogs.com/huanghaopeng/p/13254938.html