标签:就是 mic input tor class 不同 parallel oal 通过
RDD 使用分区来分布式并行处理数据, 并且要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 读取数据的时候, 会尽量的在物理上靠近数据源, 比如说在读取 Cassandra 或者 HDFS 中数据的时候, 会尽量的保持 RDD 的分区和数据源的分区数, 分区模式等一一对应。
分区的主要作用是用来实现并行计算, 本质上和 Shuffle 没什么关系, 但是往往在进行数据处理的时候, 例如 reduceByKey, groupByKey 等聚合操作, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区, 于是理解分区才能理解 Shuffle 的根本原理。
Spark 中的 Shuffle 操作的特点:
只有 Key-Value 型的 RDD 才会有 Shuffle 操作, 例如 RDD[(K, V)], 但是有一个特例, 就是 repartition 算子可以对任何数据类型 Shuffle。
早期版本 Spark 的 Shuffle 算法是 Hash base shuffle, 后来改为 Sort base shuffle, 更适合大吞吐量的场景。
3.1 创建 RDD 时指定分区数
scala> val rdd1 = sc.parallelize(1 to 100, 6) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24 scala> rdd1.partitions.size res1: Int = 6 scala> val rdd2 = sc.textFile("hdfs:///dataset/wordcount.txt", 6) rdd2: org.apache.spark.rdd.RDD[String] = hdfs:///dataset/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24 scala> rdd2.partitions.size res2: Int = 7
rdd1 是通过本地集合创建的, 创建的时候通过第二个参数指定了分区数量. rdd2 是通过读取 HDFS 中文件创建的, 同样通过第二个参数指定了分区数, 因为是从 HDFS 中读取文件, 所以最终的分区数是由 Hadoop 的 InputFormat 来指定的, 所以比指定的分区数大了一个.
3.2 通过 coalesce 算子指定
coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T] #numPartitions新生成的 RDD 的分区数,shuffle是否 Shuffle
如果 shuffle 参数指定为 false, 运行计划中确实没有 ShuffledRDD, 没有 shuffled 这个过程。
如果 shuffle 参数指定为 true, 运行计划中有一个 ShuffledRDD, 有一个明确的显式的 shuffled 过程。
如果 shuffle 参数指定为 false 却增加了分区数, 分区数并不会发生改变, 这是因为增加分区是一个宽依赖, 没有 shuffled 过程无法做到, 后续会详细解释宽依赖的概念。
3.3 通过 repartition 算子指定
repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
repartition 算子本质上就是 coalesce(numPartitions, shuffle = true)
scala> val source = sc.parallelize(1 to 100, 6) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24 scala> source.partitions.size res7: Int = 6 scala> source.repartition(100).partitions.size res8: Int = 100 scala> source.repartition(1).partitions.size res9: Int = 1
repartition 算子无论是增加还是减少分区都是有效的, 因为本质上 repartition 会通过 shuffle 操作把数据分发给新的 RDD 的不同的分区, 只有 shuffle 操作才可能做到增大分区数, 默认情况下, 分区函数是 RoundRobin, 如果希望改变分区函数, 也就是数据分布的方式, 可以通过自定义分区函数来实现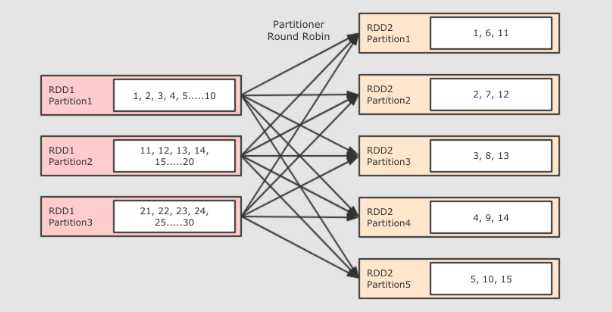
Spark从HDFS读入文件的分区数默认等于HDFS文件的块数(blocks),HDFS中的block是分布式存储的最小单元。如果我们上传一个30GB的非压缩的文件到HDFS,HDFS默认的块容量大小128MB,因此该文件在HDFS上会被分为235块(30GB/128MB);Spark读取SparkContext.textFile()读取该文件,默认分区数等于块数即235。
spark读取kafka数据模式为direct,分区数为topic分区数。
1、分区数越多越好吗?
分区数太多意味着任务数太多,每次调度任务也是很耗时的,所以分区数太多会导致总体耗时增多。
2、分区数太少会有什么影响?
分区数少则每个分区要处理的数据量就会增大,从而对每个结点的内存要求就会提高;还有分区数不合理,会导致数据倾斜问题。
3、合理的分区数是多少?如何设置?
总核数=executor-cores * num-executor
一般合理的分区数设置为总核数的2~3倍
标签:就是 mic input tor class 不同 parallel oal 通过
原文地址:https://www.cnblogs.com/chong-zuo3322/p/13260106.html