标签:页面 pil 实现 通过 时间间隔 现在 传参 cas att
Locust 脚本开发入门(1)
Locust 脚本开发入门(2)
Locust 脚本开发入门(3)
返回:教程目录
现在我们对这个脚本进行一些修改,让它更像一个真实的用户访问行为
1) 任务等待时间:任务之间按照特定的等待时间进行间隔
Locust 的任务之间等待时间控制包括:
方法1:between 类,指定范围内随机(5~10秒)等待
wait_time = between(5, 10)
方法2:constant 类,从上一次响应结束后,等待特定时间(3秒),再发起下一次请求
wait_time = constant(3)
方法3:constant_pacing 类,从上一次请求发起后,等待特定时间(3秒),再发起下一次请求,如果上一次请求的响应时间大于指定的时间(3秒),则在响应后立即发起下一次请求
wait_time = constant_pacing(3)
2) 步骤等待时间:在任务内加入步骤之间的时间间隔
方法1:从 time 导入 sleep 类即可
至此,脚本实现如下
from time import sleep
from locust import HttpUser, task, constant
class cnblogUser(HttpUser):
# open_blog和open_links任务之间等待固定的3秒
wait_time = constant(3)
@task(2)
def open_blog(self):
self.client.get("/huanghaopeng/")
@task(1)
def open_links(self):
# 在open_links任务内,上下两个步骤之间,等待1秒
self.client.get("/huanghaopeng/p/13100305.html")
sleep(1)
self.client.get("/huanghaopeng/p/13220749.html")
sleep(1)
self.client.get("/huanghaopeng/p/13187807.html")
sleep(1)
def on_start(self):
self.client.get("/")
3) 参数化:文章页面参数
由上面 open_links 任务的内容可知,13100305、13220749、13187807 是文章 ID,但是随着日后博客内容的增删改,这些博客链接可能随之失效、新增,因此为了让我们的脚本行为更符合一个真实用户的访问行为,现需要脚本在打开我博客的首页后从首页的页面源码中,解析出文章链接进行点击。所以在下面的脚本中,我将会:
import re
from time import sleep
from locust import HttpUser, task, constant
class cnblogUser(HttpUser):
wait_time = constant(3)
@task(2)
def open_blog(self):
with self.client.get("/huanghaopeng/") as resp:
if resp.status_code < 300:
pattern = re.compile(r‘<div class="c_b_p_desc">\n.*<a href="(.*)" class="c_b_p_desc_readmore">‘)
self.urlList = pattern.findall(resp.text)
else:
pass
@task(1)
def open_links(self):
# 由于权重配置,无法确保 open_links 任务执行时 self.urlList 包含文章链接列表
for url in self.urlList:
self.client.get(url)
def on_start(self):
self.client.get("/")
但是,上面脚本存在一个问题,由于当前任务的执行是依据权重配置执行的,无法确保 open_blog 和 open_links 的先后执行顺序。
当然,你也可以把 open_blog 和 open_links 两个任务内的工作合并为一个任务就可以达到顺序执行的目的。
4) 任务控制:按照顺序的方式执行(SequentialTaskSet 类)
主要步骤:
import re
from time import sleep
from locust import HttpUser, task, constant, SequentialTaskSet
# 继承 SequentialTaskSet 的一个任务类,内部编排好任务的执行顺序
class TaskCase(SequentialTaskSet):
# 初始化
def on_start(self):
self.client.get("/")
# @task 装饰器说明下面是一个任务
@task
def open_blog(self):
with self.client.get("/huanghaopeng/") as resp:
if resp.status_code < 300:
pattern = re.compile(r‘<div class="c_b_p_desc">\n.*<a href="(.*)" class="c_b_p_desc_readmore">‘)
self.urlList = pattern.findall(resp.text)
else:
pass
# @task 装饰器说明下面是一个任务
@task
def open_links(self):
for url in self.urlList:
self.client.get(url)
# 继承 httpUser
class cnblogUser(HttpUser):
tasks = [TaskCase]
wait_time = constant(3)
至此,任务执行顺序将为:on_start -> open_blog -> open_links,执行压测场景看看
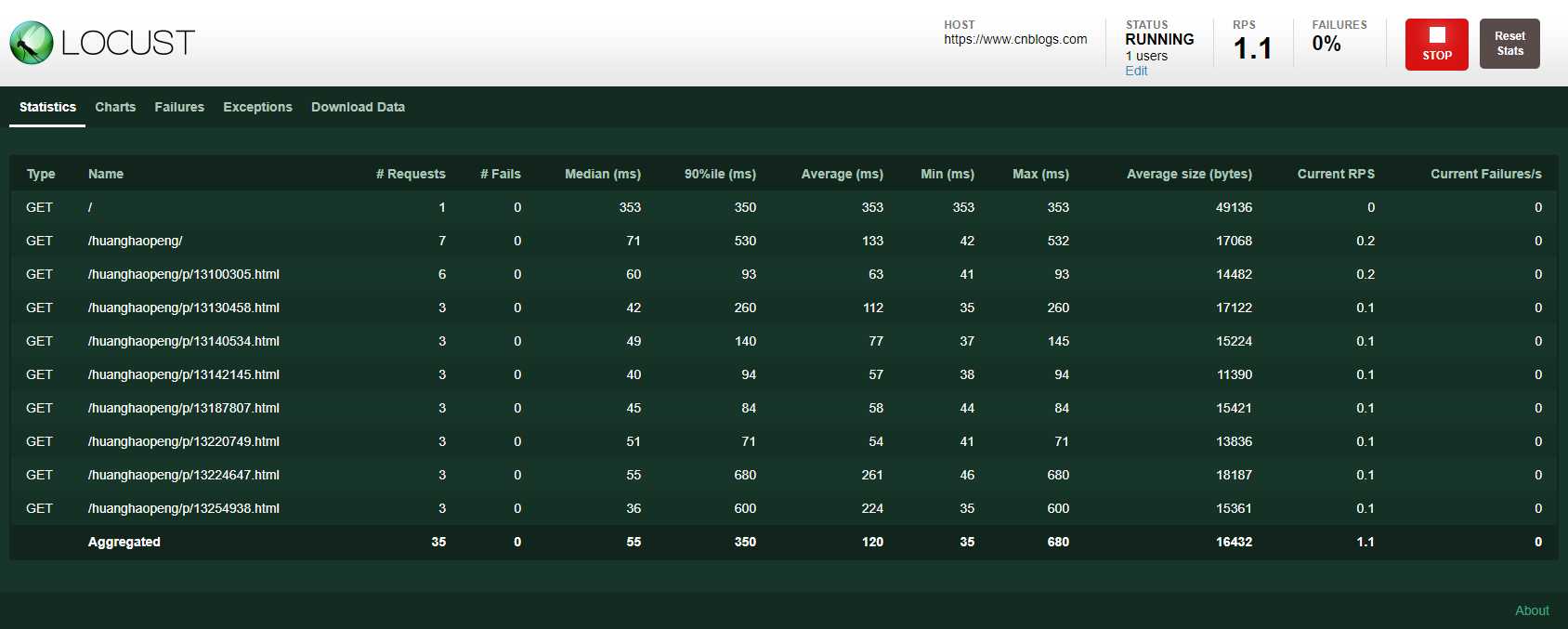
由上面的结果,可以看到,虚拟用户实现了 打开博客首页,进入我的博客并解析页面上的文章链接,再逐个访问,但是,浏览多篇文章本质上只是不同的文章id传参请求,没有在结果中分别统计的需要,因此我们给请求指定一下name,进行合并统计:
def open_links(self):
for url in self.urlList:
# 对name进行传参为任务名称
self.client.get(url,name=‘open_links‘)
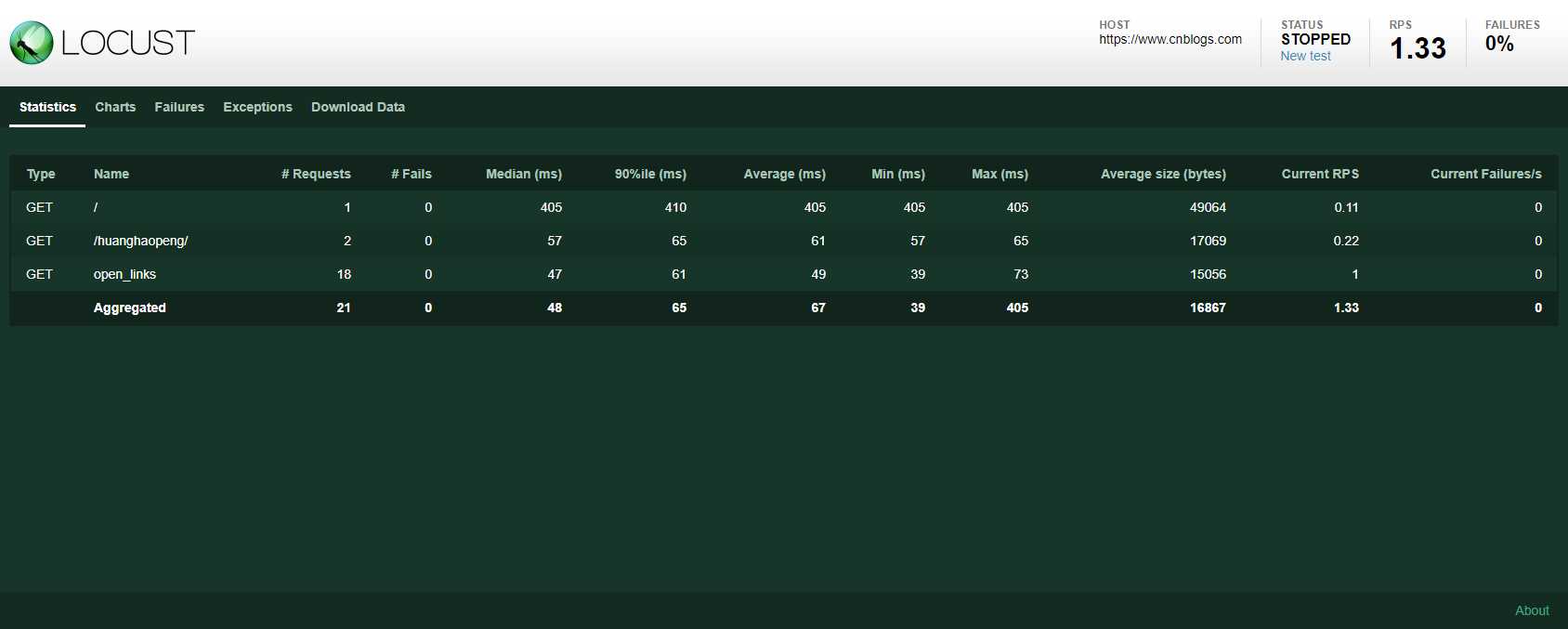
再次执行,可见多篇文章遍历访问的请求响应已经被合并统计
Locust 脚本开发入门(1)
Locust 脚本开发入门(2)
Locust 脚本开发入门(3)
返回:教程目录
标签:页面 pil 实现 通过 时间间隔 现在 传参 cas att
原文地址:https://www.cnblogs.com/huanghaopeng/p/13255067.html