标签:重复 扩容 shc 方式 mamicode hashcode 决定 可变 遍历
collection接口下面有哪些集合
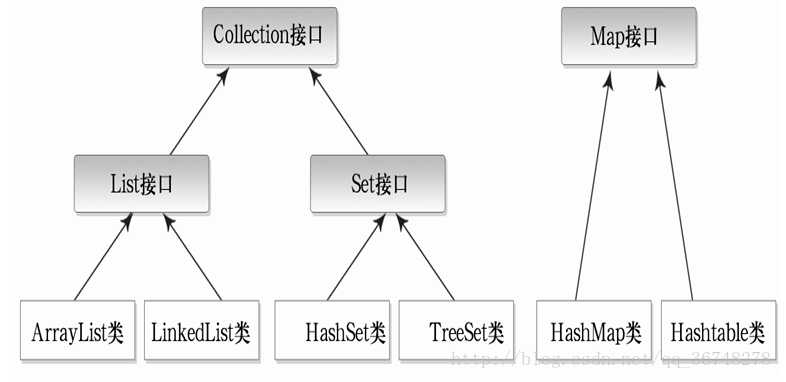
list与set区别:在List中的元素存放是有序的,可以存放重复的元素,检索效率较高,插入删除效率较低,set没有存放顺序不能存放重复元素检索效率较低,插入删除效率较高,由于set集合储存位置是由他的HashCode码决定的,所以他的存储对象必须有equals()方法,而且set遍历只能用迭代,没有下标。
ArrayList:底层的实现就是一个可变数组非同步实现,当数组长度不够用的时候就会重新开辟一个新的数组,然后将原来的数据拷贝到新的数组内。由于这一底层实现,所以ArrayList集合中元素存储的位置是连续的,查询起来效率比较高,插入删除效率较低。
LinkedList:LinkList中元素存储位置是不连续的,插入删除的执行效率高,查询效率低。
Vector是线程安全的,但是性能比ArrayList要低。
HashSet:底层由哈希表(实际上是一个HashMap实例)支持,不能保证元素的顺序,元素是无序的,可以有null,但是null只能有一个,不能有重复的元素。HashSet不是同步的,需要外部保持线程之间的同步问题。
TreeSet:TreeSet实现了SortedSet接口,它是一个有序的集合类,TreeSet的底层是通过TreeMap实现的。TreeSet并不是根据插入的顺序来排序,而是根据实际的值的大小来排序。TreeSet也支持两种排序方式:自然排序和自定义排序。不能放入重复元素和null。
hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的
HashMap:使用位桶和链表实现(最近的jdk1.8改用红黑树存储而非链表),它是线程不安全的Map,方法上都没有synchronize关键字修饰,
HashTable;hashTable是线程安全的一个map实现类,它实现线程安全的方法是在各个方法上添加了synchronize关键字。但是现在已经不再推荐使用HashTable了,因为现在有了ConcurrentHashMap这个专门用于多线程场景下的map实现类,其大大优化了多线程下的性能。
ConcurrentHashMap:主要实现原理是segment段锁,它不再使用和HashTable一样的synchronize一样的关键字对整个方法进行枷锁,而是转而利用segment段落锁来对其进行加锁,以保证Map的多线程安全。在JAVA的jdk1.8中则对ConcurrentHashMap又再次进行了大的修改,取消了segment段锁字段,采用了CAS+Synchronize技术来保障线程安全。底层采用数组+链表+红黑树的存储结构,也就是和HashMap一样,有 16 个 Segments ,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的
TreeMap:因为他具有一个很大的特点就是会对Key进行排序,使用了TreeMap存储键值对,再使用iterator进行输出时,会发现其默认采用key由小到大的顺序输出键值对
LinkedHashMap:LinkedHashMap是有序的,且默认为插入顺序。继承于HashMap,是基于HashMap和双向链表来实现的。插入顺序和访问顺序两种
1.引用计数法
2可达性分析
标签:重复 扩容 shc 方式 mamicode hashcode 决定 可变 遍历
原文地址:https://www.cnblogs.com/2048tw/p/13260479.html