标签:sha 知识点整理 吞吐量 维护 hadoop 负载 操作 影响 二次开发
****

我们知道订单系统堪称整个电商交易平台的核心,它需要与很多内部模块、外部第三方系统打交道。其实从下订单到支付完成这个过程中,需要完成很多额外的步骤:
为用户积分
本文就以订单系统为基础,看完后相信你会对消息中间件的原理有更清晰的认识。本文将会从以下几个方面来讲述相关知识,相信大家耐心看了之后肯定有收获,码字不易,别忘了「在看」,「转发」哦。
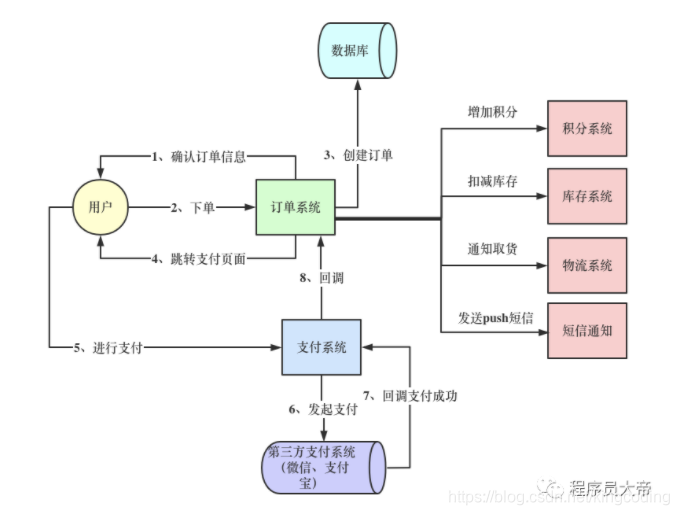
对于一个电商APP而言,每卖掉了一个商品,就要扣减掉商品的库存,而且一旦用户成功支付了,还需要将订单的状态更新成待发货。
在完成这些最核心的功能后,其实是有很多事情要做的,比如上图红色的部分。如果这些动作都以同步方式来完成,根据线上系统的一般统计,多个子步骤全部执行完毕,加起来大概需要1秒~2秒的时间。
有时候在高峰期并发量特别大,服务器的磁盘、IO、CPU的负载会很高,执行SQL语句的性能也会有所下降。因此有的时候甚至需要几秒钟的时间完成上述几个步骤。
那么影响是什么呢?
想象一下,如果你是一个用户,在支付完一个订单之后,界面上会有一个圈圈不停的旋转,让你等待好几秒之后才能提示支付成功。对用户来说几秒钟的时间,会让人非常不耐烦的!

所以首先针对子步骤过多、速度过慢、让用户支付之后等待时间过长的问题,就是订单系统亟需解决的问题!
而解决这个问题的一大利器就是消息中间件,英文全称“Message Queue”,简称MQ。
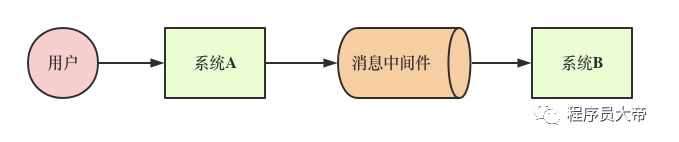
在引入消息中间件以后,系统A和系统B之间就由同步变为异步通信,而完成这样的一个核心概念就是“消息”。
系统A发送消息给MQ后,就认为已经完成了自己的任务;然后系统B根据自己的情况,可能会在系统A投递消息到MQ之后的1秒内,也可能是1分钟之后,也可能是1小时之后,多长时间都有可能。
反正不管是多长时间后,系统B会根据自己的节奏从MQ里获取到一条属于自己的消息,再根据消息的指示完成自己的工作。
在“异步调用”的整个过程中,系统A仅仅是发个消息到MQ,至于系统B什么时候获取消息,有没有获取消息,系统A是不管的。
顺着这个思路,我们再重新思考一下订单系统。由于支付订单流程中,过多的子步骤如红包发放、短信push通知、积分等等导致性能很差。
在引入MQ后,我们可以让订单系统仅仅完成最核心的功能,然后发送消息到MQ。比如需要进行减库存,就发送一个消息到库存消息队列中,然后库存系统从这个MQ里获取消息再进行处理就可以,把这些很耗时的步骤慢慢执行,从而也实现了系统之间的解耦。
在双11大促活动的时候,同样可以让瞬间涌入的大量下单请求到MQ里去排队,然后让订单系统在后台慢慢的获取订单,以数据库可以接受的速率完成操作,避免瞬间请求量过大击垮数据库。
这也是MQ的另一重要功能:削峰填谷,我会在接下来的文章更加详细的以秒杀场景进行介绍。
所谓消息中间件,就是一种系统,它自己本身也是独立部署的,通过消息的收发,是多个系统之间不局限于同步调用,通过异步调用更好地实现解耦。
具体来说,消息中间件,也就是MQ只是一种概念和模式。在真正使用的时候,我们要考虑如何正确使用MQ来满足我们的需求。简单来看,可以从以下几个维度进行思考:
(1)MQ的性能表现怎么样?
(2)假如机器硬件条件相同,比如互联网公司最为常见的2G4核或者4G8核,能抗住多少QPS,每秒几千QPS或几万QPS,什么程度会到达性能瓶颈?
(3)性能有多高,比如向MQ发送消息需要2毫秒还是20毫秒?
(4)能够高可用吗,如果部署的一台服务器宕机了怎么办,有没有自动修复的机制?
(5)可靠吗,会不会丢失数据?
(6)支持线性的集群扩展吗,添加更多机器的机制复杂吗?
(7)功能性满足吗,比如经常需要使用的功能:延迟消息、事务消息、消息累积、消息回溯、死信队列等等?
(8)官方文档是否完整且清晰,社区活跃吗,如果遇到技术问题我们是否方便地找到解决办法?
(9)在工业中是否已经被广泛使用了,已经被大公司验证过它的质量?
(10)它是用什么语言写的,如果有个性化的需求,是否可以对源码进行修改?
借着这个机会,我们可以对MQ有一个基本的了解,把这些事情都搞清楚了,你会发现消息中间件技术并没你想的那么难。
目前业界使用最广泛的是Kafka、RabbitMQ以及RocketMQ这三种消息中间件,因此我们主要针对它们来进行调研对比。接下来我们从性能、可靠性、功能性等多方面维度,来分析一下它们的优势和劣势。
Kafka
(1)Kafka的吞吐量几乎是行业里最优秀的,在常规的机器配置下,一台机器可以达到每秒十几万的QPS,可谓是消息中间件中的顶尖水平。
(2)性能高,发送消息给Kafka可以控制在毫秒级。
(3)可用性高,Kafka能够支持集群部署,如果部分服务器发生了宕机,集群其余部分可以保证任务的继续运行。
(1)Kafka的存储策略是在消息收到之后,将其写入磁盘缓冲区内,并不会直接存储到物理硬盘上。这就导致了假如机器本身发生故障,磁盘缓冲区里的数据非常有可能丢失。而消息作为最重要的资源, kafka的这一特点有可能造成严重后果。
(2)Kafka另外一个比较大的缺点是功能比较单一。它使用了典型的推拉架构设计,生产者将发送消息给它,然后消费者在从它拉取消息进行消费。除此之外,其他就没有什么额外的高级功能,所以基于Kafka有限的功能,一些比较复杂的商业场景并不是很适合。
RabbitMQ
再说RabbitMQ,在RocketMQ出现之前,国内大部分公司,包括很多一线互联网大厂都在使用RabbitMQ,而且直到目前,还有很多中小型公司在使用RabbitMQ。
(1)可以有保证数据不丢失的机制。
(2)保证高可用性,集群部署的时候部分,即使部分服务器宕机可以继续执行任务。
(3)实现了部分高级功能,比如死信队列,消息重试。
(1)RabbitMQ的吞吐量是比较低,只有每秒几万的级别,遇到像双十一这样的高并发场景,很容易到达性能的瓶颈。
(2)维护比较复杂,在集群部署时,如果需要线性扩展,比较麻烦。
(3)它的开发语言是erlang,国内目前大大小小公司的技术骨干大部分都是BAT背景,精通erlang语言的还是少数。阅读源代码非常困难,也就更加无从谈起根据个性化要求修改源代码了
RocketMQ
RocketMQ是阿里开源的消息中间件,经过实战的检验,比较靠谱。后发优势使它在最初设计的时候,就为了去解决Kafka和RabbitMQ所存在的缺陷。
(1)性能强大,吞吐量高,能够达到10万QPS以上的级别
(2)可以保证高可用性,能够大规模集群化部署
(3)支持通过配置保证数据绝对不丢失
(4)满足多种需求,比如说延迟消息、事务消息、消息回溯、死信队列、消息积压等等。
(5)RocketMQ是基于Java开发的,符合国内大多数公司的技术栈,很容易就可以阅读他的源码,甚至是修改他的源码。
当然RocketMQ也有美中不足的地方,RocketMQ的官方文档相对简单,而这也是国内开源软件和社区的一个通病,可能国内996的工作强度导致大家没有更多的精力维护。
相比于起步早,社区化程度高的的Kafka和RabbitMQ 的官方文档,这是RocketMQ需要慢慢追赶的一点。
根据Kafka技术在各大公司里的使用情况,目前行业内比较流行的方式是用Kafka进行采集和传输用户行为日志。对于一个电商公司而言,每天的行为数据堪称天量,比如商品详情页的点击,店铺的转化率等等,非常适合大数据团队来收集APP上用户的种种行为。
虽然Kafka有可能会导致消息的丢失,但由于日志本身并不像订单那么重要,即使真的发生了数据丢失也在可控范围内。
最主要在这个场景下,日志量特别大,吞吐量必须要高,只要保证收发消息的正常完成就满足的需要,并不需要其他功能,所以 Kafka非常适合这种场景。
而目前现在国内很多一线互联网大厂,在核心系统模板上,都在慢慢切换为使用RocketMQ了。RocketMQ的高吞吐量,大规模集群部署能力,以及各种高级功能满足了日益复杂的商业化业务需求,尤其是非常适合用在Java业务系统架构中,同时还可以根据自己的需求定制修改RocketMQ的源码。
对于中小型互联网公司,并发量没那么大,似乎看起来RabbitMQ也能满足所有的需要。没有特别高的吞吐量,也不需要部署大规模集群,更没必要阅读和修改RabbitMQ的源码。但是RocketMQ一定是更好的选择,因为它规避掉了RabbitMQ的全部缺点。
假设未来我们身处一个大公司,每秒会有几十万的QPS,也许我们以后也需要对MQ进行源码的二次开发,那此时RabbitMQ还合适吗?
**
**
公众号内还整理 《Java核心知识点整理.pdf》, 面试突击全都靠它了,好东西还是要分享出来给大家一起学习呀~
内容覆盖很广:Java 核心基础、Java 多线程、高并发、Spring、微服务、Netty 与 RPC、Zookeeper、Kafka、RabbitMQ、HBase、设计模式、负载均衡、分布式缓存、Hadoop、Spark、Storm、云计算等。
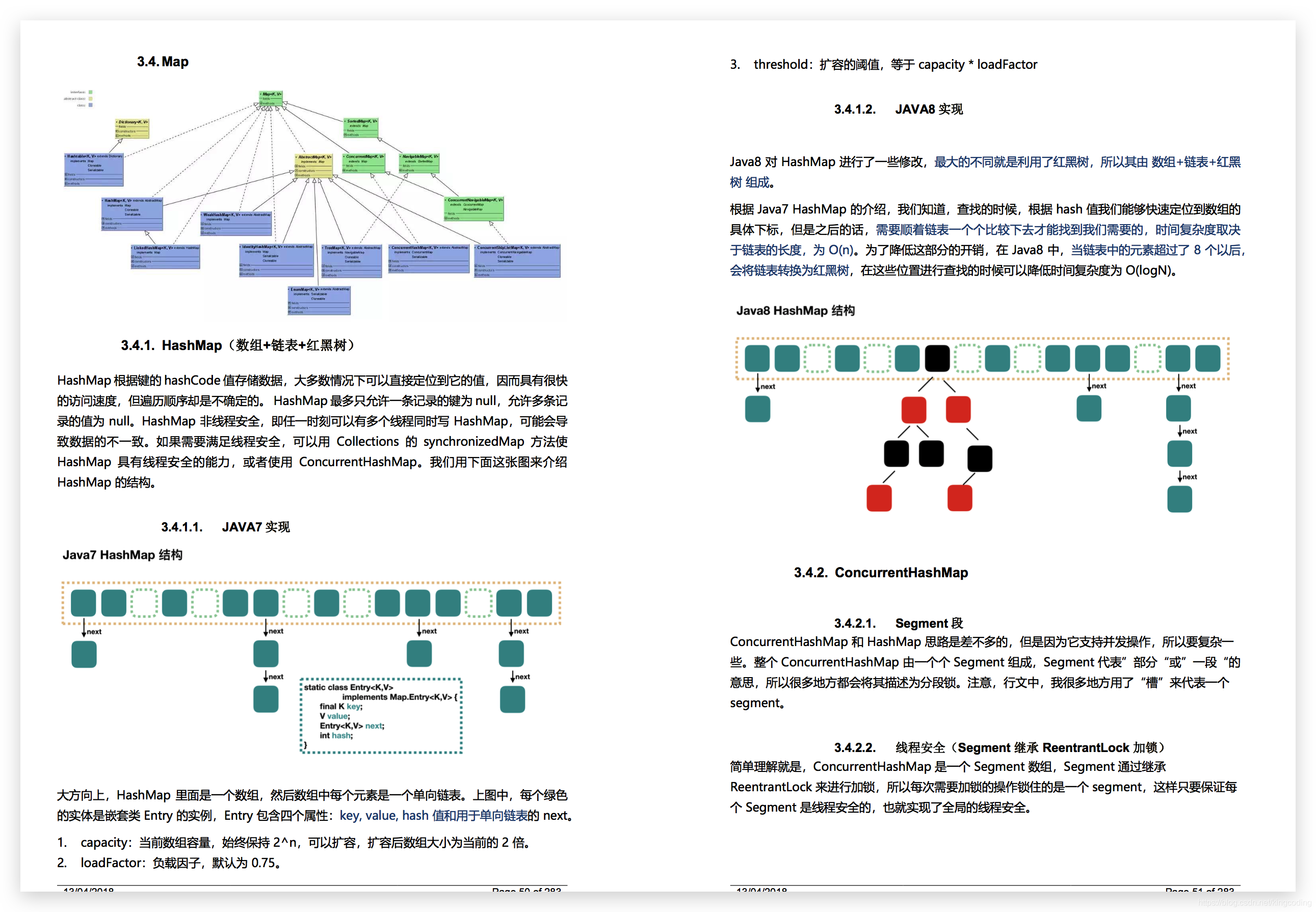

获取方式: 关注公众号【程序员大帝】, 后台回复【资料】,即可免费无套路获取资源链接
标签:sha 知识点整理 吞吐量 维护 hadoop 负载 操作 影响 二次开发
原文地址:https://blog.51cto.com/14867449/2509427