标签:操作 维度 let gif close init alt nts nbsp
|
定义网络 |
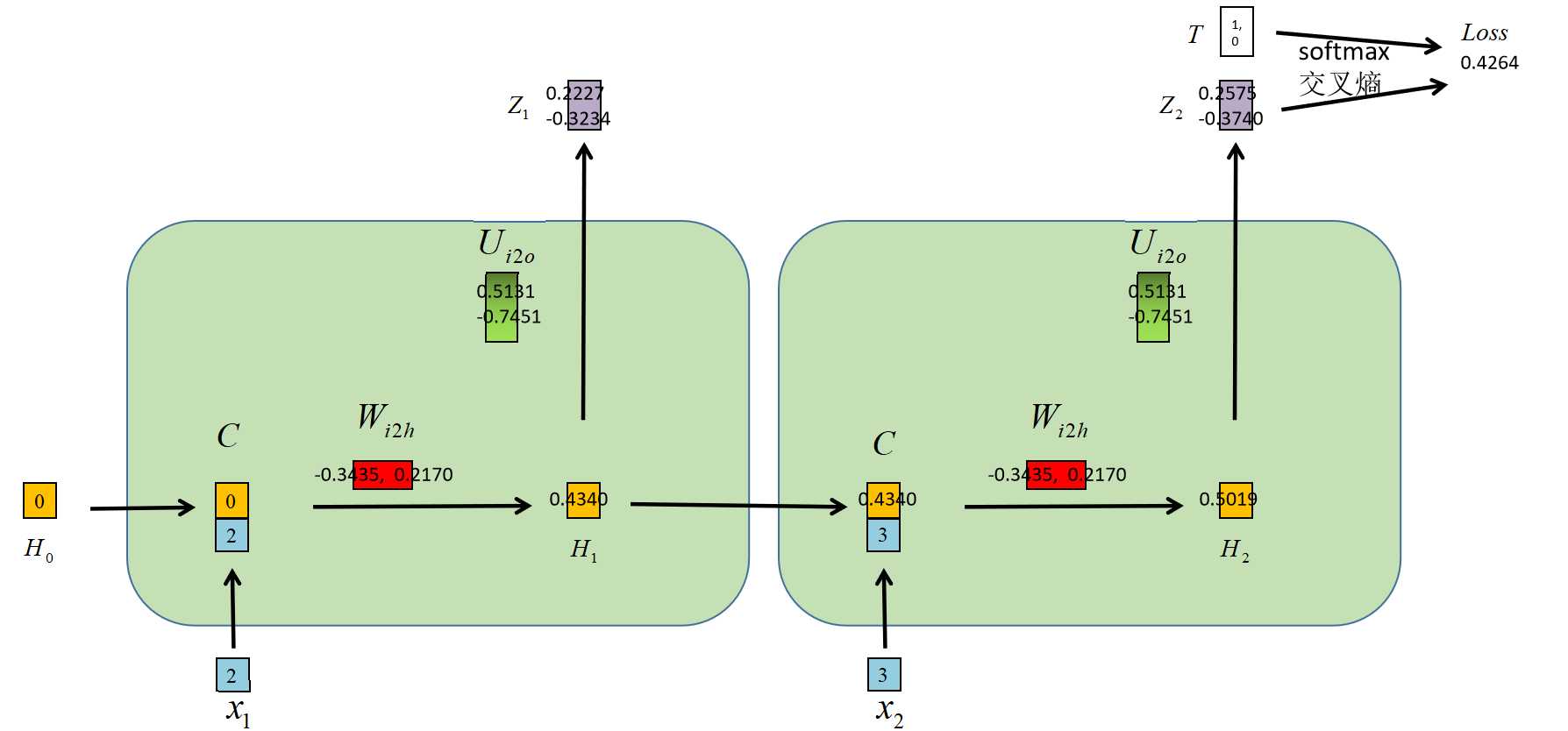
|
梯度反向传播 |
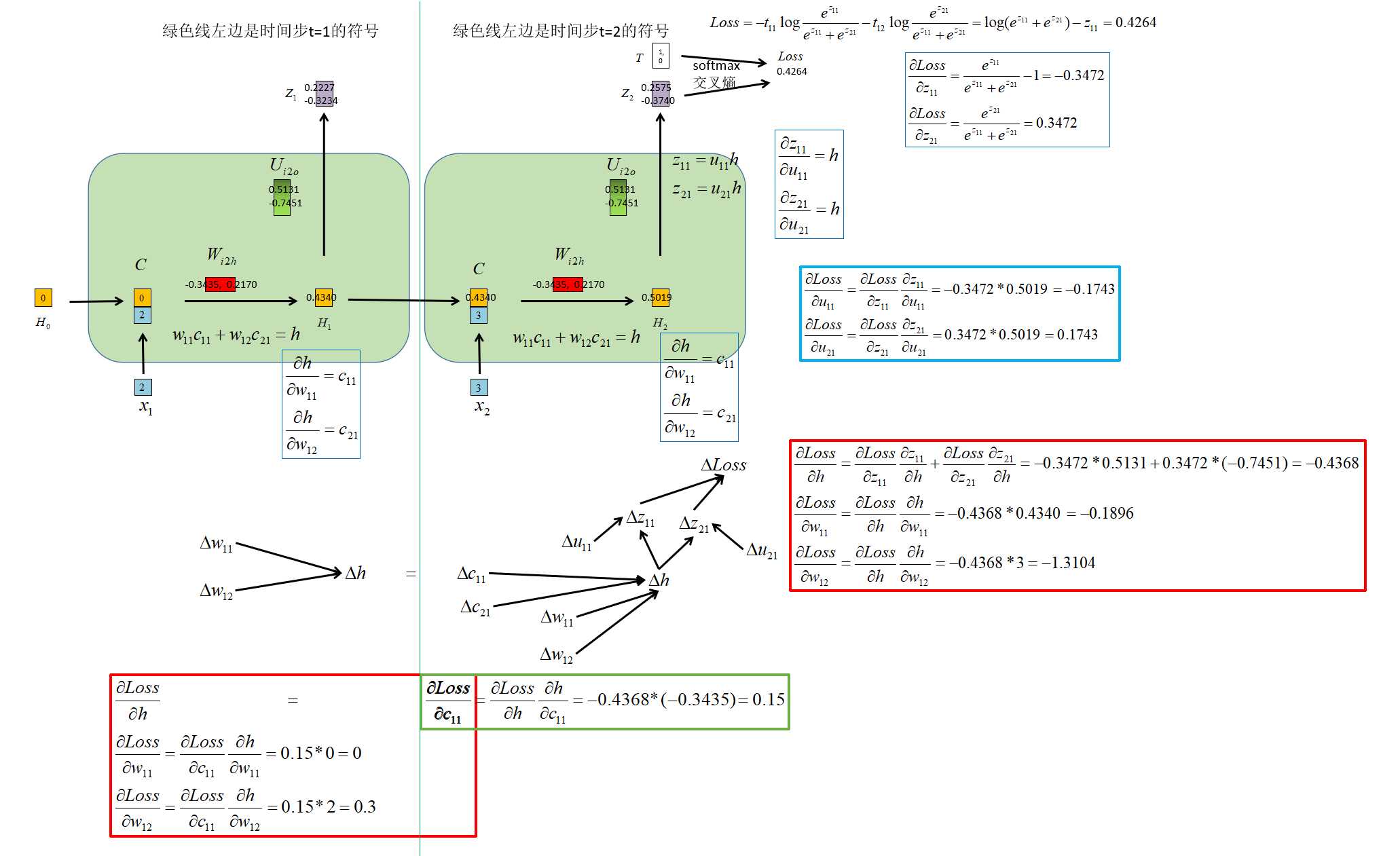
|
梯度更新 |


import torch import torch.nn as nn import torch.nn.functional as F class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size, bias=False) self.i2o = nn.Linear(hidden_size, output_size, bias=False) self.softmax = nn.Softmax(dim=1) def forward(self, input, hidden): combined = torch.cat((hidden, input), 1) hidden = self.i2h(combined) output = self.i2o(hidden) # output = self.softmax(output) return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size) def train(category_tensor, input_tensor): hidden = rnn.initHidden() rnn.zero_grad() for i in range(input_tensor.size()[0]): output, hidden = rnn(input_tensor[i], hidden) loss = criterion(output, category_tensor) loss.backward() # Add parameters‘ gradients to their values, multiplied by learning rate for p in rnn.parameters(): print("梯度值",p.grad.data) p.data.add_(p.grad.data, alpha=-learning_rate) return output, loss.item() if __name__ == ‘__main__‘: n_hidden = 1 n_categories = 2 n_letters = 2 rnn = RNN(n_letters, n_hidden, n_categories) weight_i2h = torch.tensor([ [-0.3435, 0.2170] ]) weight_i2o = torch.tensor([ [0.5131], [-0.7451] ]) rnn.i2h._parameters["weight"].data = weight_i2h # 自定义 rnn.i2o._parameters["weight"].data = weight_i2o # 自定义 for p in rnn.parameters(): print("初始化权重",p.data) criterion = nn.CrossEntropyLoss() learning_rate = 0.1 n_iters = 1 all_losses = [] for iter in range(1, n_iters + 1): category_tensor = torch.tensor([0]) # 第0类,哑编码:[1, 0] input_tensor = torch.tensor([ [[2.]], # 第1个字符的编码 [[3.]] # 第2个字符的编码 ]) output, loss = train(category_tensor, input_tensor) print("迭代次数",iter, output, loss) """ 初始化权重 tensor([[-0.3435, 0.2170]]) 初始化权重 tensor([[ 0.5131], [-0.7451]]) 梯度值 tensor([[-0.1896, -1.0103]]) 梯度值 tensor([[-0.1743], [ 0.1743]]) 迭代次数 1 tensor([[ 0.2575, -0.3740]], grad_fn=<MmBackward>) 0.42643341422080994 """
|
面试时的变相问法 |
|
参考资料 |
标签:操作 维度 let gif close init alt nts nbsp
原文地址:https://www.cnblogs.com/itmorn/p/13276387.html
