标签:访问 自带 测试 灰度发布 负载 lse local control pid
一. 客户端负载均衡器Ribbon
之前研究nacos的时候也说过服务端负载均衡和客户端负载均衡. 其实我们常用的服务端负载均衡就是nginx
在负载均衡中维护一个可用的服务实例清单, 当客户端请求来临时, 负载均衡服务器按照某种配置好的规则(负载均衡算法), 从可用服务实例清单中, 选取其一去处理客户端请求, 这就是服务端负载均衡, 例如Nginx. 通过nginx进行负载均衡, 客户端发送请求值Nginx, nginx通过负载均衡算法, 在多个服务器之间选择一个进行访问.
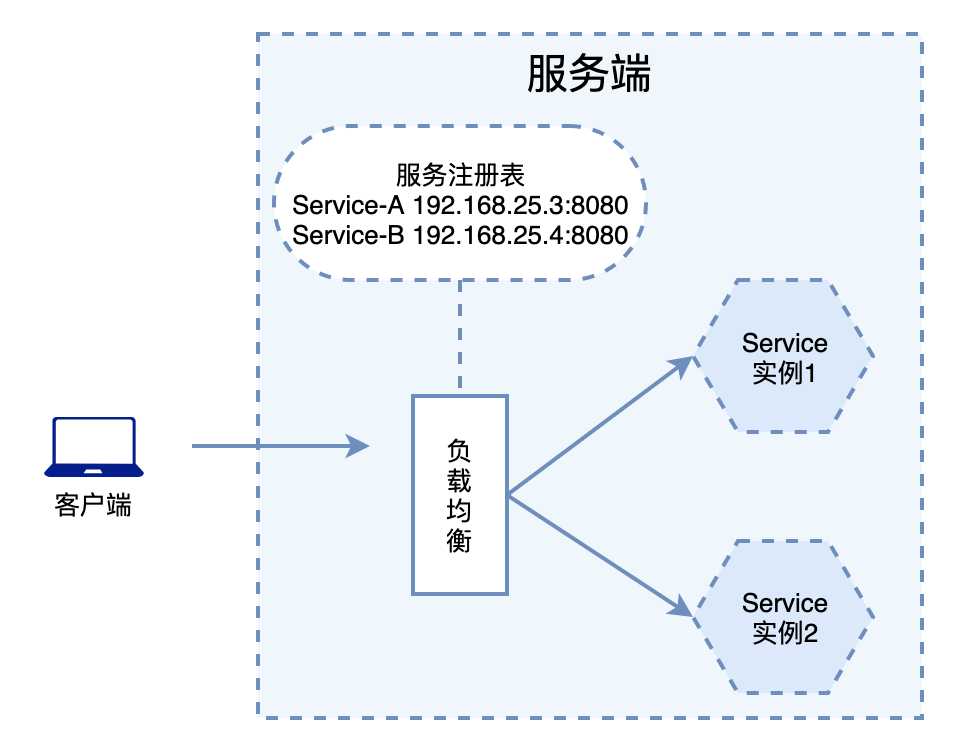
接下来, 我们要讲的ribbon, 就属于客户端负载均衡, 在ribbon客户端会有一个服务实例地址列表, 在发送请求前, 通过负载均衡算法, 选择一个服务实例, 然后进行访问, 这是客户端负载均衡. 即在客户端进行负载均衡算法分配.
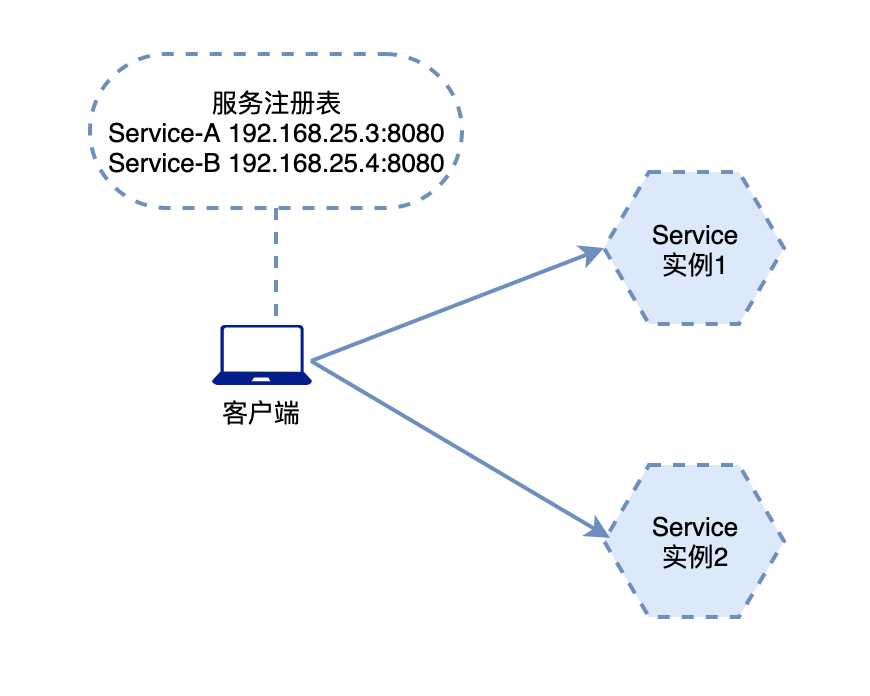
先面我们先来看看ribbon负载均衡的效果
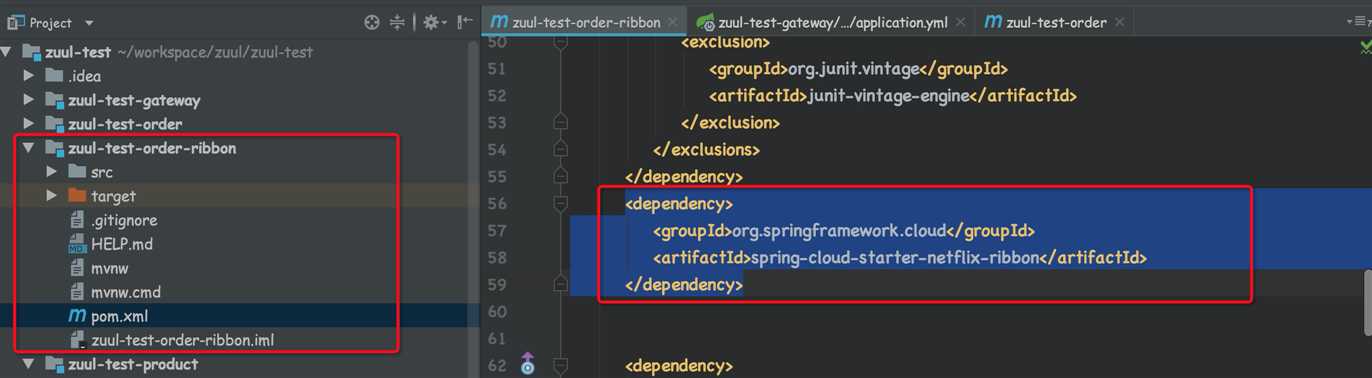
我么拷贝了一个order项目, 为其添加ribbon依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
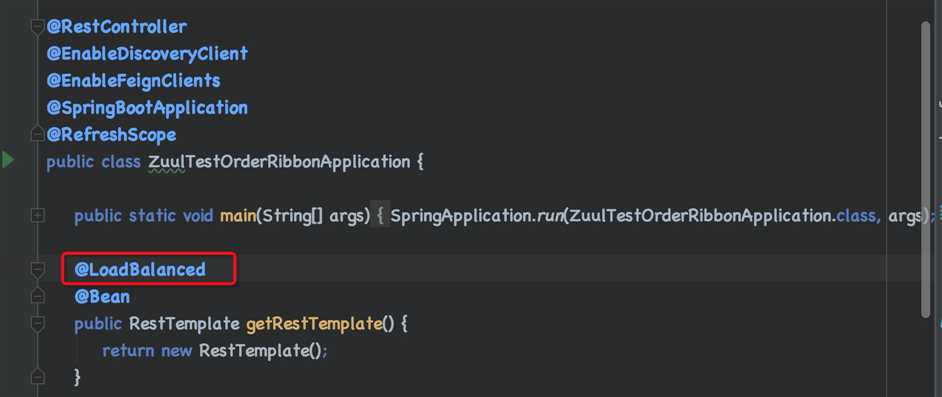
这里在实例化RestTemplate的时候, 增加一个注解@LoadBalanced.
我们之前在研究zuul的时候, 好像没有配置过这个注解呀, 为什么呢?因为在zuul里调用的时候使用feign, feign里面实现了这个负载均衡.
package com.lxl.www.gateway.controller; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.client.discovery.DiscoveryClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; @Slf4j @RestController public class UserController { @Autowired private DiscoveryClient discoveryClient; @Autowired private RestTemplate restTemplate; @GetMapping("get/user") public String getUser() { String forObject = restTemplate.getForObject("http://product/config", String.class); System.out.println(forObject); return forObject; } }
启动order服务1台-里面添加了ribbon依赖配置, 端口号是8080
启动product服务3台, 端口号分别是8081, 8082, 8083
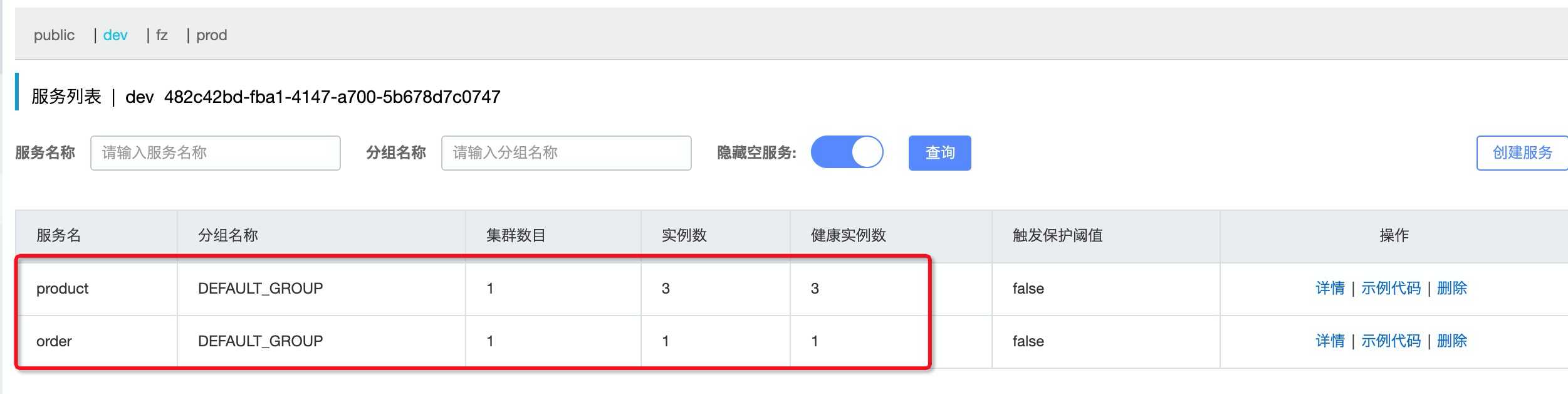
product的详情信息
请求服务
http://localhost:8080/get/order

我们看到调用了3次, 每个实例被调用1次
我们看到了ribbon的基本用法, 知道他的一个基本的实现原理, 下面来看看ribbon的基本配置
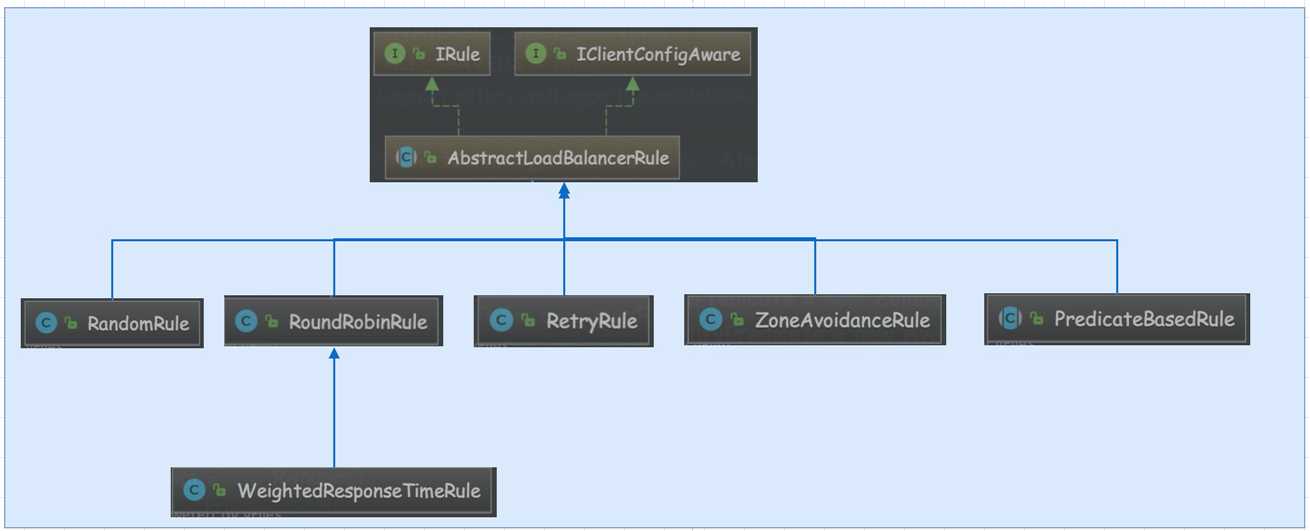
ribbon自带的负债均衡策略一共有6中
最后我们来看看这些策略的具体实现
# 所有实例公用
ribbon:
NFLoadBalanceRuleClassName: com.netflex.loadbalance.RandomRule
#指定服务实例使用
product:
ribbon:
NFLoadBalanceRuleClassName: com.netflex.loadbalance.RandomRule
user:
ribbon:
NFLoadBalanceRuleClassName: com.netflex.loadbalance.RandomRobinRule
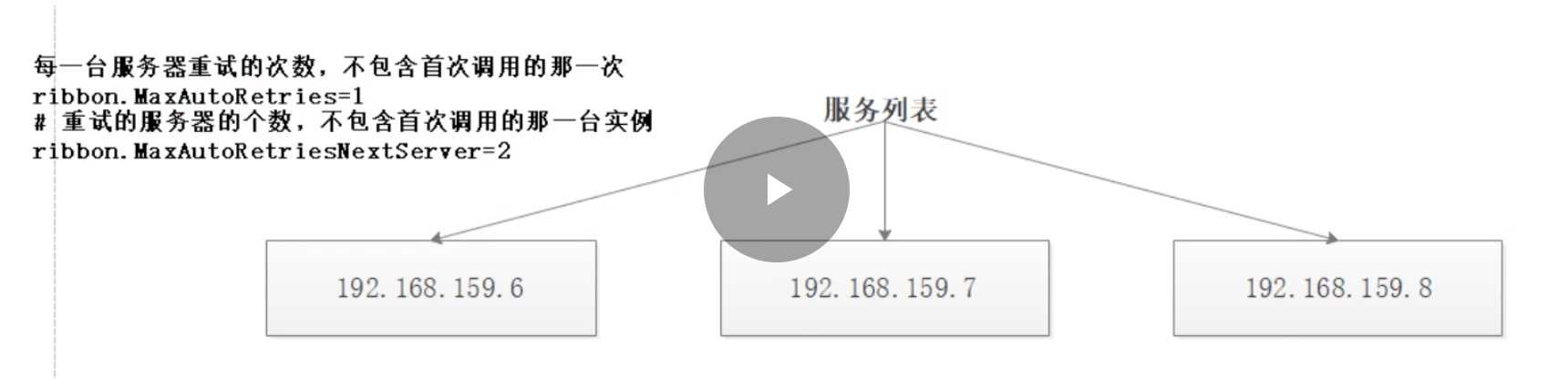
ribbon:
ReadTimeout: 1000
ConnectTimeout: 1000
MaxAutoRetries: 1
MaxAutoRetriesNextServer: 2
OkToRetryOnAllOperations: false
http:
client:
enabled: true
每一台服务器重试的次数, 不包含首次调用的按一次 ribbon.MaxAutoRetries=1 含义是如果调用服务失败了, 那么重试1次
这里的MaxAutoRetriesNextServer是什么意思呢?
重试服务器的个数, 不包含首次调用的那一台实例 ribbon.MaxAutoRetriesNextServer=2 含义是是: 如果负载均衡选择了服务器1, 结果调用失败, 重试还是失败了. 那么这是可以选择重试除了这台服务器的其他服务器. 可以重试几台呢? 可以重试两台
这里的OkToRetryOnAllOperations是什么意思呢?
这里是对http方法进行重试设置, 可以设置成true或者false
如果设置为true: 则表示post,put等方法也会进行重试. 这样会导致的问题是, 重复提交. 要避免这个事情的发生, 要保证服务的幂等性
什么是服务的幂等性呢?
看一下这篇文章就明白了: https://www.cnblogs.com/QG-whz/p/10372458.html
在nacos中可以配置服务器的权重
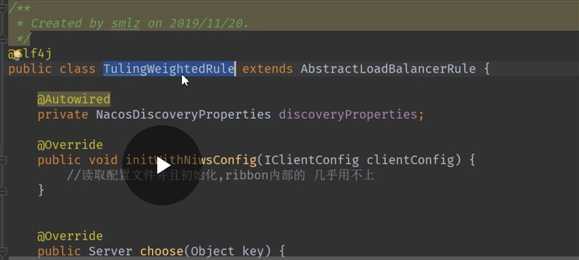
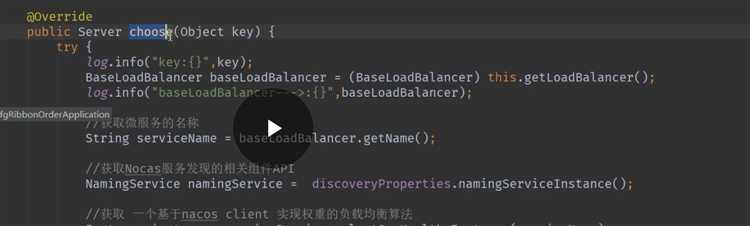
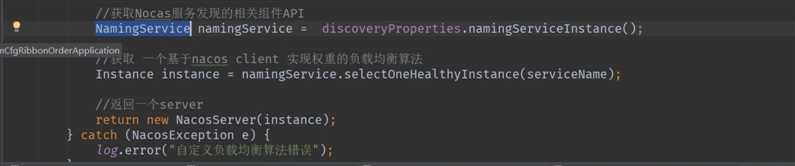
启动服务
配合nacos服务实例设置服务器的权重
测试
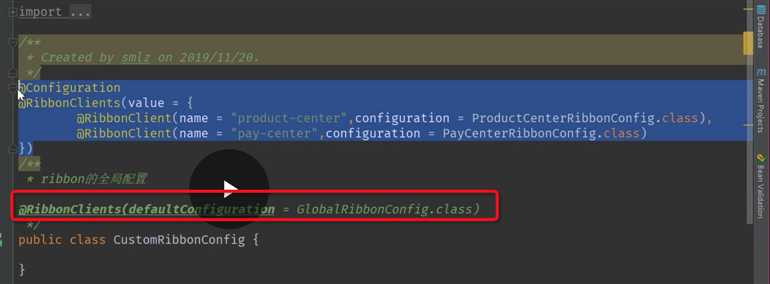
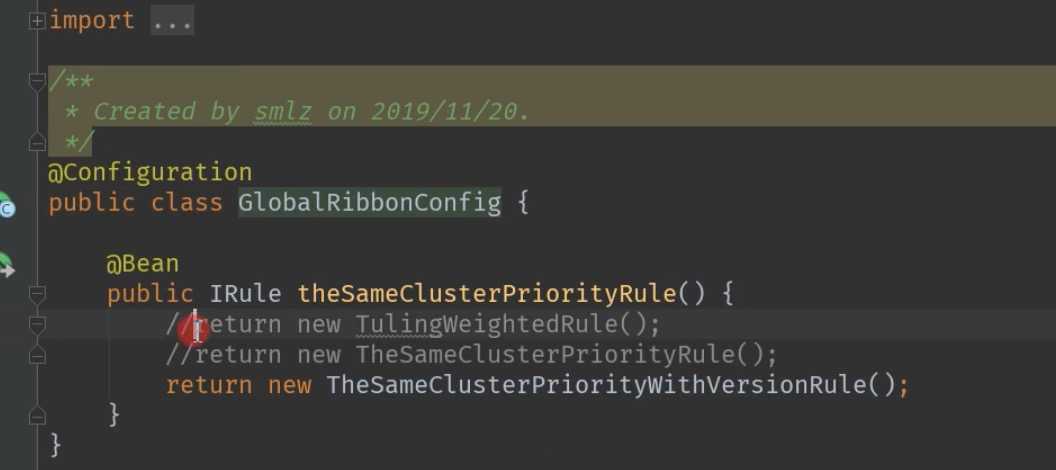
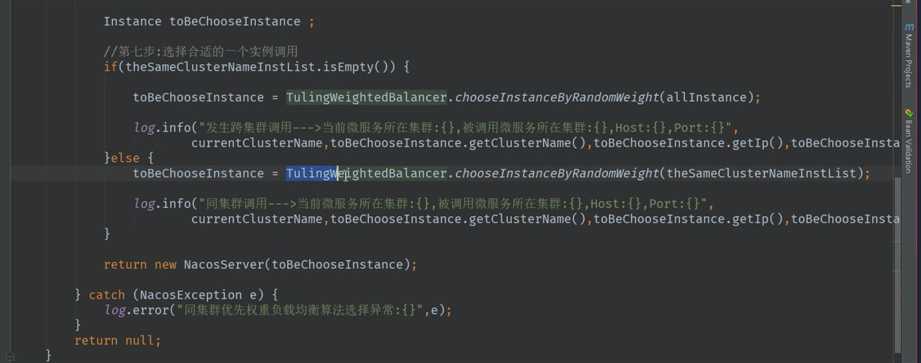
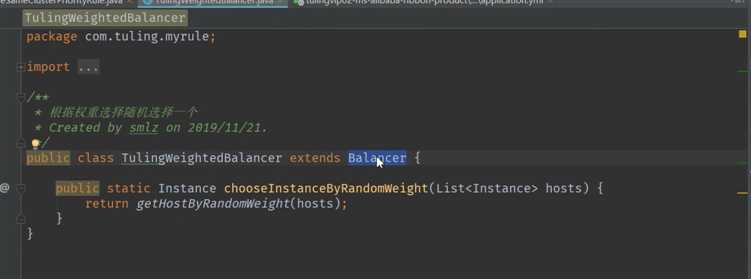
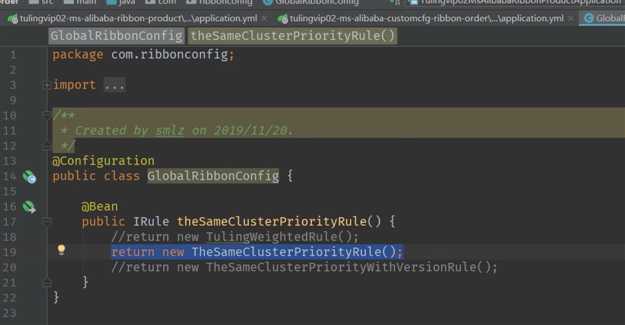
尽量避免跨集群调用
比如, 南京集群的product优先调用南京集群的order . 北京集群的product优先调用北京集群的order.
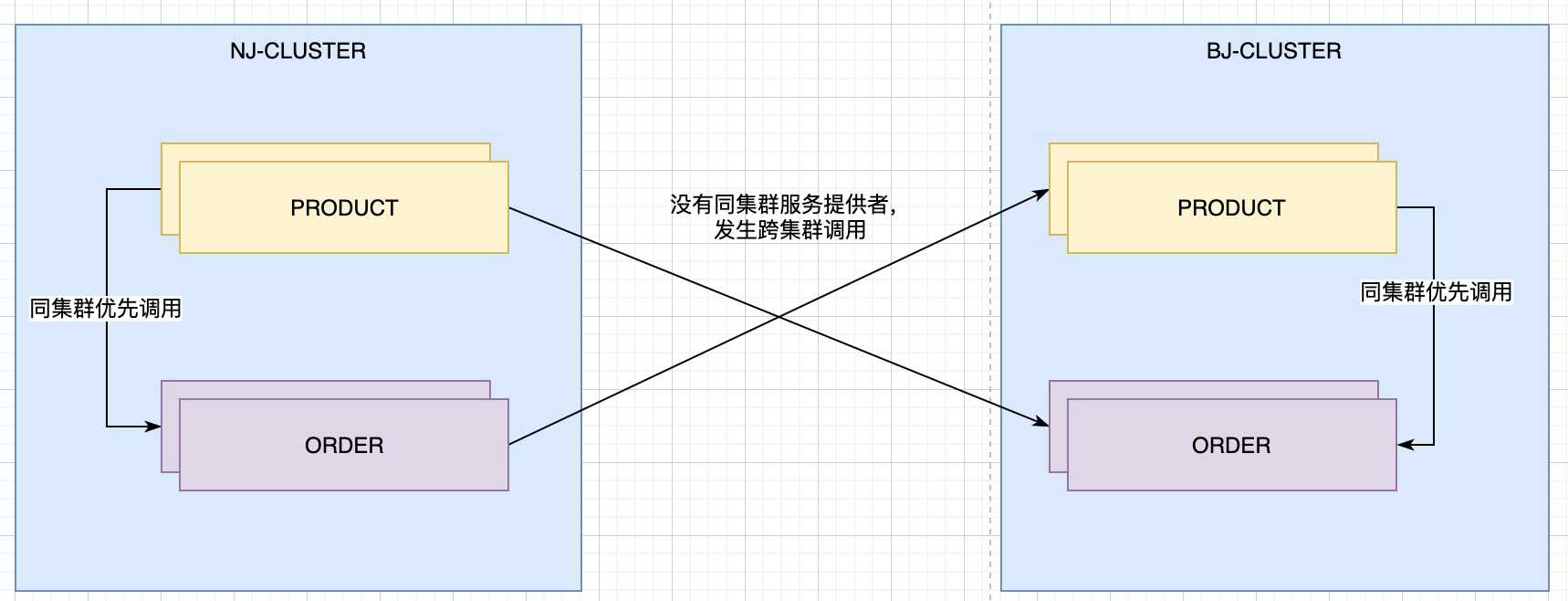
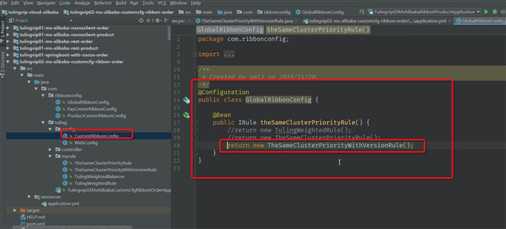
实现如上图所示的功能
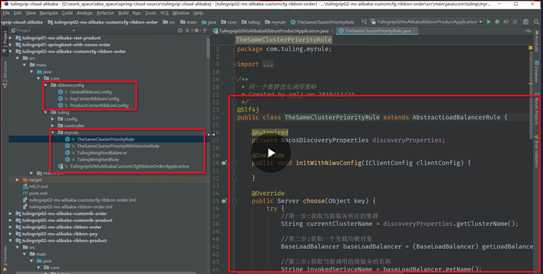
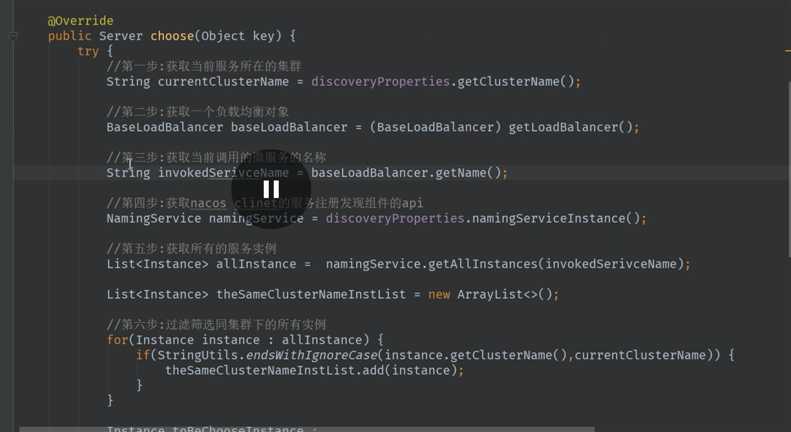
首先确定集群名称
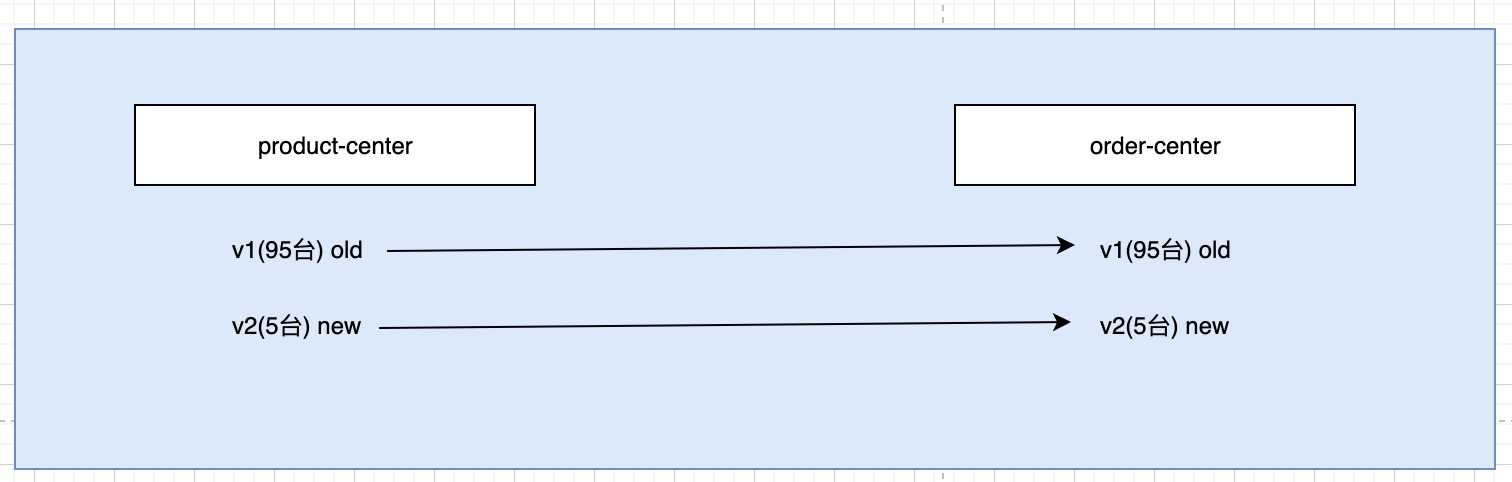
金丝雀发布, 也称为灰度发布, 是什么意思呢?
首先, 我们的product服务实例有100台, order服务实例有100台.
现在都是在v1 版本上
然后新开发了一个变化很大的功能, 要进行灰度测试
在product-center上发布了5台, 在order-center上发布了5台
那么现在用户的流量过来了, 如果请求的是product-center的v1版本的流量, 那么就要全部都走v1版本, 请求的order-center也要是v1版本
如果过来的用户, 请求的v2版本的流量, 那么product和order都走v2版本.
下面我们要实现的功能描述如下:
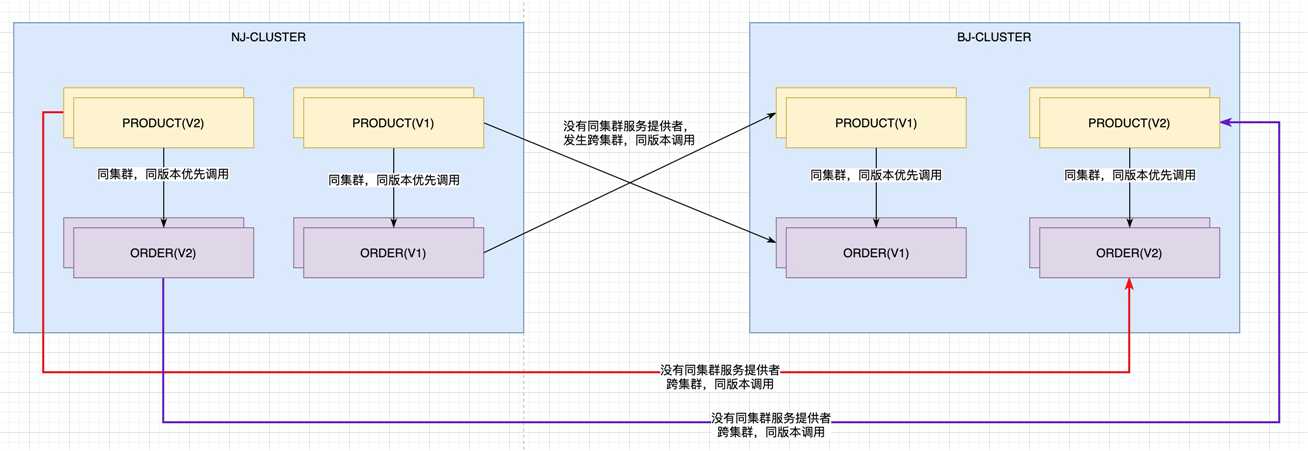
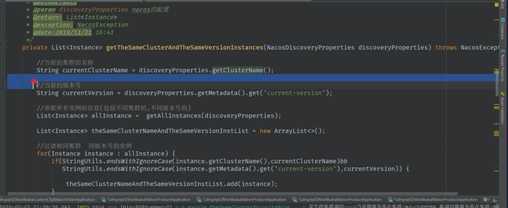
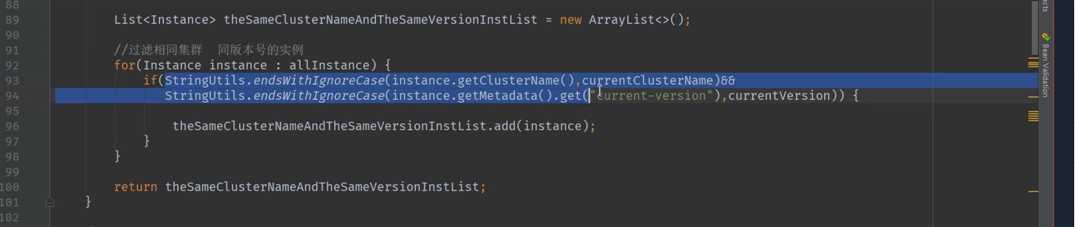
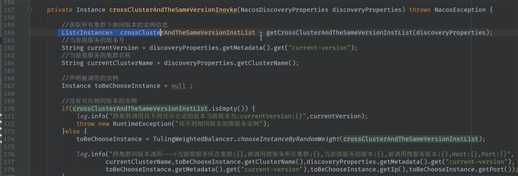
1. 同集群,同版本优先调用
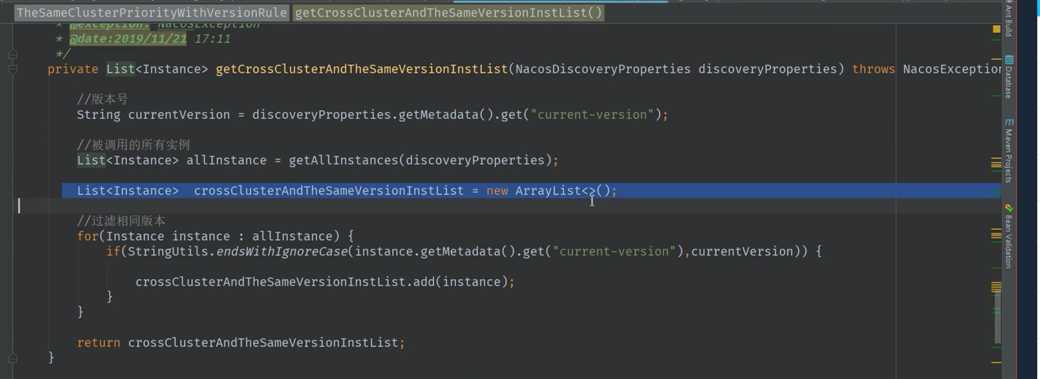
2. 没有同集群的服务提供者, 进行跨集群,同版本调用
3. 不可以进行不同版本间的调用
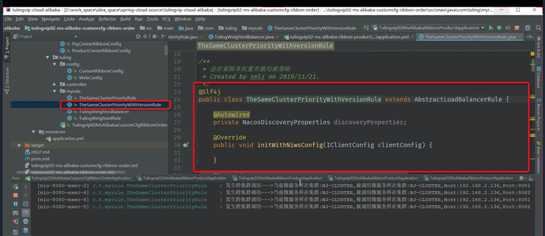
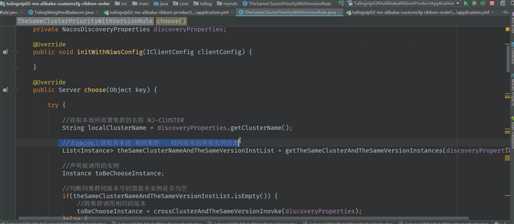
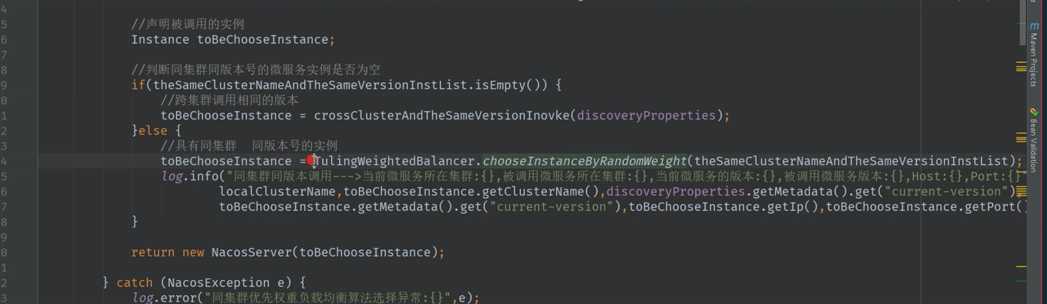

as
标签:访问 自带 测试 灰度发布 负载 lse local control pid
原文地址:https://www.cnblogs.com/ITPower/p/13272866.html