标签:send 分类 home == %s color 处理 mini its
1.配置文件代码(需要配置稳健获取内容、以及文件存储地方’)
# coding=utf-8 import warnings class DefaultConfigs(object): env = ‘default‘ model_name = "resnet" # 训练模型:活参数 #base_folder = "/opt/facetrain/keji/" # 活参数,根据自己的目录修改,后面的参数都是根据这个参数变化,最重要修改这个参数 base_folder = "F:/pytest/算法交接/keji/" data_dir = base_folder + "sucai/" # 1 活参数,训练照片的目录 folder_add_argument = base_folder # 2 liunx 命令的参数 acc_txt = base_folder + "acc.txt" # 3 训练结束后准确率文档 log_txt = base_folder + "log.txt" # 4 训练结束后,日志文档 best_acc_txt = base_folder + "best_acc.txt" # 5 训练结束后,最好的准确率文档 personInfo_txt = base_folder + "personInfo.txt" # train_data = "./data/train/" # where is your train images data # test_data = "./data/test/" # your test data # load_model_path = None # weights = "./checkpoints/" # best_models = "./checkpoints/best_models/" # debug_file=‘./tmp/debug‘ # Number of classes in the dataset num_classes = 5 # 活参数,需要修改:参与训练的人数 人为数据classes数目 # Batch size for training (change depending on how much memory you have) batch_size = 4 # 活参数,可以不修改:批处理大小(batch_size) 类似于IO的byte[] # Number of epochs to train for EPOCH = 2 # 活参数,可以不修改:进行50代运算 # Flag for feature extracting. When False, we finetune the whole model, # when True we only update the reshaped layer params # feature_extract = True feature_extract = False # 特征提取,如果为假,微调整个模型;如果为真只更新层的参数 .参数值一般不变 lr = 0.00005 # learning rate 学习率,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值,越大则在最小值附近越震荡,越小则收敛的越慢 lr_decay = 0.5 # 学习率衰减没有用到 weight_decay = 5e-4 # 防止过拟合的参数,过度拟合反而训练出来的不准 pre_epoch = 0 # 初始代数 topk = 5 # 最相似的前几个人 #没有用到 def parse(self, kwargs): """ update config by kwargs """ for k, v in kwargs.items(): if not hasattr(self, k): warnings.warn("Warning: opt has not attribut %s" % k) setattr(self, k, v) print(‘user config:‘) for k, v in self.__class__.__dict__.items(): if not k.startswith(‘__‘): print(k, getattr(self, k)) DefaultConfigs.parse = parse config = DefaultConfigs()
2.模型训练代码
# -*- coding: utf-8 -*- """ @author: Administrator """ from torchvision import transforms as T from torch.utils.data import DataLoader from torchvision import datasets, models, transforms import torch from torch import nn import torch.optim as optim import argparse import warnings import os from config import config warnings.filterwarnings("ignore") data_dir = config.data_dir # 保存图片的目录 folder_add_argument = config.folder_add_argument # 2 liunx 命令的参数 acc_txt = config.acc_txt # 3 训练结束后准确率文档 log_txt = config.log_txt # 4 训练结束后,日志文档 best_acc_txt = config.best_acc_txt # 5 训练结束后,最好的准确率文档 personInfo_txt = config.personInfo_txt # 6 训练期间,身份对应的字典项输出到文档 num_classes = config.num_classes # 人数 batch_size = config.batch_size # 缓冲区大小 pre_epoch = config.pre_epoch # 初始迭代次数 EPOCH = config.EPOCH # 定义已经遍历数据集的次数 LR = config.lr # 学习率,算法中用 model_name = config.model_name # 使用的模型 feature_extract = config.feature_extract # 特征提取,如果为假,微调整个模型;如果为真只更新层的参数 def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad = False def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True): # Initialize these variables which will be set in this if statement. Each of these # variables is model specific. net = None input_size = 0 if model_name == "resnet": """ Resnet18 """ net = models.resnet18(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.fc.in_features net.fc = nn.Linear(num_ftrs, num_classes) pre = ‘net_060.pth‘ #net.load_state_dict(torch.load(pre)) # GPU训练 device = torch.device(‘cpu‘) net.load_state_dict(torch.load(pre, map_location=device)) # CPU训练 input_size = 224 elif model_name == "resnet34": """ Resnet34 """ net = models.resnet34(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) net.fc = nn.Linear(8192, num_classes) # pre=‘net_015.pth‘ # net.load_state_dict(torch.load(pre)) input_size = 299 elif model_name == "alexnet": """ Alexnet """ net = models.alexnet(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier[6].in_features net.classifier[6] = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "vgg": """ VGG11_bn """ net = models.vgg11_bn(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier[6].in_features net.classifier[6] = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "squeezenet": """ Squeezenet """ net = models.squeezenet1_0(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) net.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1, 1), stride=(1, 1)) net.num_classes = num_classes input_size = 224 elif model_name == "densenet": """ Densenet """ net = models.densenet121(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier.in_features net.classifier = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "inception": """ Inception v3 Be careful, expects (299,299) sized images and has auxiliary output """ net = models.inception_v3(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) # Handle the auxilary net num_ftrs = net.AuxLogits.fc.in_features net.AuxLogits.fc = nn.Linear(num_ftrs, num_classes) # Handle the primary net num_ftrs = net.fc.in_features net.fc = nn.Linear(num_ftrs, num_classes) input_size = 299 else: print("Invalid model name, exiting...") exit() return net, input_size # Initialize the model for this run net, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True) # Print the model we just instantiated # print(net, input_size) # Detect if we have a GPU available device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # Send the model to GPU net = net.to(device) data_transforms = { ‘train‘: transforms.Compose([ transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)), transforms.RandomRotation(degrees=15), #transforms.RandomResizedCrop(input_size), transforms.ColorJitter(), transforms.RandomHorizontalFlip(), transforms.CenterCrop(size=224), #Image net standards transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), ‘val‘: transforms.Compose([ #transforms.Resize(input_size), transforms.Resize(256), transforms.CenterCrop(input_size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } # Create training and validation datasets image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in [‘train‘, ‘val‘]} # print(len(image_datasets[‘train‘])) # Create training and validation dataloaders 把image_datasets转换成训练模型需要的数据 dataloaders_dict = { x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in [‘train‘, ‘val‘]} # print(len(dataloaders_dict[‘train‘])) a = image_datasets[‘train‘].class_to_idx # train文件夹下的身份证文件夹-->字典 dict_new = {value:key for key,value in a.items()} # 对字典a(包含序号与身份证)交换key与value #print(dict_new) # 参数设置,使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多 parser = argparse.ArgumentParser(description=‘PyTorch resnet Training‘) parser.add_argument(‘--outf‘, default= folder_add_argument, help=‘folder to output images and model checkpoints‘) # 输出结果保存路径 # parser.add_argument(‘--net‘, default=‘/home/dell/Desktop/zhou/resnet.pth‘, help="path to net (to continue training)") #恢复训练时的模型路径 args = parser.parse_args() params_to_update = net.parameters() print("Params to learn:") if feature_extract: params_to_update = [] for name, param in net.named_parameters(): if param.requires_grad == True: params_to_update.append(param) print("\t", name) else: for name, param in net.named_parameters(): if param.requires_grad == True: print("\t", name) # 定义损失函数和优化方式 criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵,多用于多分类问题 optimizer = optim.SGD(params_to_update, lr=LR, momentum=0.9, weight_decay=config.weight_decay) # 优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减) ii = 0 if __name__ == "__main__": f1 = open(personInfo_txt, ‘w+‘) print(dict_new, file=f1) # (train文件夹下的身份证文件夹)交换后的字典-->输出到personInfo.txt中 f1.close() # 输出完毕后关闭 best_acc = 0 # 初始化best test accuracy print("Start Training, resnet!") # 定义遍历数据集的次数 with open(acc_txt, "w") as f: with open(log_txt, "w")as f2: for epoch in range(pre_epoch, EPOCH): ii = ii + 1 if (ii % 50 == 0): LR = LR * 0.1 print(‘\nEpoch: %d‘ % (epoch + 1)) net.train() sum_loss = 0.0 correct = 0.0 total = 0.0 for i, data in enumerate(dataloaders_dict[‘train‘], 0): # 准备数据 length = len(dataloaders_dict[‘train‘]) inputs, labels = data inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() # forward + backward outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 每训练1个batch打印一次loss和准确率 sum_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += predicted.eq(labels.data).cpu().sum() print(‘[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% ‘ % (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total)) f2.write(‘%03d %05d |Loss: %.03f | Acc: %.3f%% ‘ % (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total)) f2.write(‘\n‘) f2.flush() # 每训练完一个epoch测试一下准确率 print("Waiting Test!") with torch.no_grad(): correct = 0 total = 0 for data in dataloaders_dict[‘val‘]: net.eval() images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) # 取得分最高的那个类 (outputs.data的索引号) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).cpu().sum() print(‘测试分类准确率为:%.3f%%‘ % (100 * correct / total)) acc = 100. * correct / total # 每个epoch保存一次模型 if (ii % 1 == 0): print(‘Saving model......‘) torch.save(net.state_dict(), ‘%s/net_%03d.pth‘ % (args.outf, epoch + 1)) # 将每次测试结果实时写入acc.txt文件中 f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc)) f.write(‘\n‘) f.flush() # 记录最佳测试分类准确率并写入best_acc.txt文件中 if acc > best_acc: f3 = open(best_acc_txt, "w") f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc)) f3.close() best_acc = acc print("Training Finished, TotalEPOCH=%d" % EPOCH)
3.测试代码
# coding=utf-8 from __future__ import print_function, division import ast import torch import torch.nn as nn import numpy as np import torchvision from torchvision import datasets, models, transforms import matplotlib.pyplot as plt from config import config import os import torch.nn.functional as F import warnings warnings.filterwarnings("ignore") plt.ion() # interactive mode 画曲线 # to the ImageFolder structure # data_dir = "/home/cc/Desktop/keji/sucai/" data_dir = config.data_dir # 存图片的地址 # Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception] # Number of classes in the dataset num_classes = config.num_classes # 参与训练的人数 人为数据classes数目 # Batch size for training (change depending on how much memory you have) batch_size = config.batch_size # 批处理大小(batch_size) 类似于IO的byte[] pre_epoch = config.pre_epoch # 定义已经遍历数据集的次数 EPOCH = config.EPOCH # 需要训练的总代数 LR = config.lr # 学习率 model_name = config.model_name # 训练模型 feature_extract = config.feature_extract # 特征提取,如果为假,微调整个模型 k = config.topk # 最相似的前几个人 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 机器是cpu还是gpu def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad = False def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True): # Initialize these variables which will be set in this if statement. Each of these # variables is model specific. net = None input_size = 0 if model_name == "resnet": """ Resnet18 """ net = models.resnet18(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.fc.in_features net.fc = nn.Linear(num_ftrs, num_classes) pre = ‘net_060.pth‘ #pre = ‘net_050.pth‘ # net.load_state_dict(torch.load(pre)) # gpu训练 device = torch.device(‘cpu‘) net.load_state_dict(torch.load(pre, map_location=device)) # CPU训练 input_size = 224 elif model_name == "resnet34": """ Resnet34 """ net = models.resnet34(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) # coding=utf-8 net.fc = nn.Linear(8192, num_classes) # pre=‘net_015.pth‘ # net.load_state_dict(torch.load(pre)) input_size = 299 elif model_name == "alexnet": """ Alexnet """ net = models.alexnet(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier[6].in_features net.classifier[6] = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "vgg": """ VGG11_bn """ net = models.vgg11_bn(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier[6].in_features net.classifier[6] = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "squeezenet": """ Squeezenet """ net = models.squeezenet1_0(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) net.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1, 1), stride=(1, 1)) net.num_classes = num_classes input_size = 224 elif model_name == "resnet101": """ Resnet101 """ net = models.resnet101(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.fc.in_features net.fc = nn.Linear(num_ftrs, num_classes) pre = ‘/home/cc/Desktop/dj/123/train3_resnet/train_resnet101/net_018.pth‘ net.load_state_dict(torch.load(pre)) input_size = 224 elif model_name == "densenet": """ Densenet """ net = models.densenet121(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier.in_features net.classifier = nn.Linear(num_ftrs, num_classes) input_size = 224 elif model_name == "densenet169": """ Densenet """ net = models.densenet169(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) num_ftrs = net.classifier.in_features net.classifier = nn.Linear(num_ftrs, num_classes) #net.load_state_dict(torch.load(pre)) input_size = 224 elif model_name == "inception": """ Inception v3 Be careful, expects (299,299) sized images and has auxiliary output """ net = models.inception_v3(pretrained=use_pretrained) set_parameter_requires_grad(net, feature_extract) # Handle the auxilary net num_ftrs = net.AuxLogits.fc.in_features net.AuxLogits.fc = nn.Linear(num_ftrs, num_classes) # Handle the primary net num_ftrs = net.fc.in_features net.fc = nn.Linear(num_ftrs, num_classes) input_size = 299 else: print("Invalid model name, exiting...") exit() return net, input_size # Initialize the model for this run model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True) pre = ‘net_060.pth‘ data_transforms = { ‘test‘: transforms.Compose([ # transforms.RandomResizedCrop(input_size), # transforms.RandomHorizontalFlip(), transforms.Resize(256), transforms.CenterCrop(input_size), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), # ‘val‘: transforms.Compose([ # transforms.Resize(input_size), # transforms.CenterCrop(input_size), # transforms.ToTensor(), # transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # ]), } image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[‘test‘]) for x in [‘test‘]} # print(len(image_datasets[‘train‘])) # Create training and validation dataloaders dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=1, shuffle=False, num_workers=2) for x in [‘test‘]} ‘‘‘ a=image_datasets[‘train‘].class_to_idx ‘‘‘ # person_dict = {0: ‘140112199012187729‘, 1: ‘140112199012197730‘, 2: ‘140112199012197731‘, 3: ‘140112199012197732‘, # 4: ‘140112199012197733‘} # train文件夹下的身份证文件夹-->字典 file_object = open(config.personInfo_txt) # 打开训练后的personInfo.txt文件(里面包含训练人的字典) try: person_dict_string = file_object.read() # 读取字典为字符串 finally: file_object.close() # 读取完毕后关闭 if len(person_dict_string) != 0: # 判空 person_dict = ast.literal_eval(person_dict_string) # 转字符串为字典 o = 0 oi = 0 if __name__ == ‘__main__‘: for phase in [‘test‘]: model_ft.eval() # training/evaluation mode, # 评估模型 model_ft = model_ft.to(device) for data in dataloaders_dict[phase]: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model_ft(images) m = nn.Softmax() ps = m(outputs) # ps = torch.exp(outputs) # Find the topk predictions topk, topclass = ps.topk(k, dim=1) # print(topk,topclass) top_classes = [person_dict[class_] for class_ in topclass.cpu().numpy()[0]] # person字典的值 # print(top_classes) top_p = topk.cpu().detach().numpy() print(top_p, top_classes) # 概率,身份证号
4.测试接口代码:(需要把训练出来的模型net_060.pth与personInfo.txt导入到对应目录下D:\阳光三级\算法交接\py-fr)
import ast import io import json import torch from torchvision import models import torchvision.transforms as transforms from PIL import Image from flask import Flask, jsonify, request import torch.nn as nn num_classes = 5 app = Flask(__name__) # imagenet_class_index = json.load(open(‘face.json‘)) model = models.resnet18() # 训练模型 num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, num_classes) pre = ‘F:\pytest\算法交接\py-fr/net_060.pth‘ # 训练的模型 device = torch.device("cpu") # cpu训练 model.load_state_dict(torch.load(pre, map_location=device)) # cpu训练 model.eval() k = 4 # topN 要返回的top人数 #base_folder = "/opt/pytorch-flask-api/" # 基础目录 base_folder = "F:\pytest\算法交接\py-fr/" # 基础目录 personInfo_txt = base_folder + "personInfo.txt" # 目录下的参加训练人员的字典 file_object = open(personInfo_txt) # 打开训练后的personInfo.txt文件(里面包含训练人的字典) try: person_dict_string = file_object.read() # 读取字典为字符串 finally: file_object.close() # 读取完毕后关闭 if len(person_dict_string) != 0: # 判空 person_dict = ast.literal_eval(person_dict_string) # 转字符串为字典 print(person_dict) def transform_image(image_bytes): ‘‘‘ 对图片进行预处理 :param image_bytes: 传入的图片 :return: 处理过适合模型的图片参数 ‘‘‘ my_transforms = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) image = Image.open(io.BytesIO(image_bytes)) return my_transforms(image).unsqueeze(0) def get_prediction(image_bytes): ‘‘‘ 预测函数 :param image_bytes:传入的图片 :return: topN的身份证列表 ‘‘‘ # person_dict = {0: ‘140112199012187729‘, 1: ‘140112199012197730‘, 2: ‘140112199012197731‘, 3: ‘140112199012197732‘, # 4: ‘140112199012197733‘} tensor = transform_image(image_bytes=image_bytes) outputs = model.forward(tensor) ps = torch.exp(outputs) # Find the topk predictions topk, topclass = ps.topk(k, dim=1) # print(topk,topclass) top_classes = [person_dict[class_] for class_ in topclass.cpu().numpy()[0]] # print(top_classes) # top_p = topk.cpu().detach().numpy() # print(top_p,top_classes) return top_classes @app.route(‘/predict‘, methods=[‘POST‘]) def predict(): if request.method == ‘POST‘: file = request.files[‘file‘] img_bytes = file.read() class_id = get_prediction(image_bytes=img_bytes) # 返回的是一个列表 return jsonify({‘class_id‘: class_id}) if __name__ == ‘__main__‘: app.run()
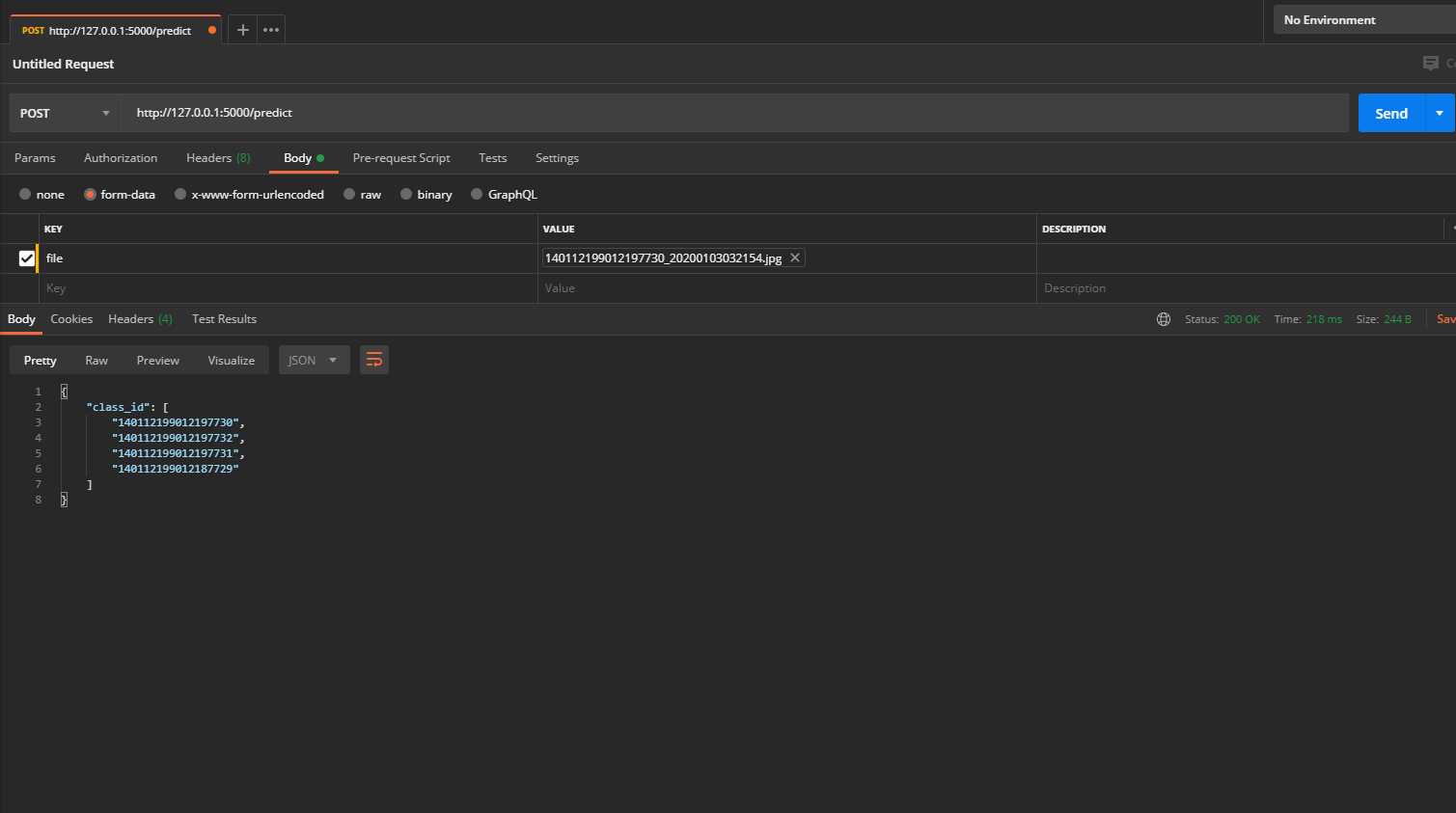
5.postman接口测试:
标签:send 分类 home == %s color 处理 mini its
原文地址:https://www.cnblogs.com/gao109214/p/13278983.html