标签:out static images 双向链表 饿汉 overflow 遍历 使用 cte
Collection 和 Map 两种体系
Collection 接口:单列数据,定义了存取一组对象的方法的集合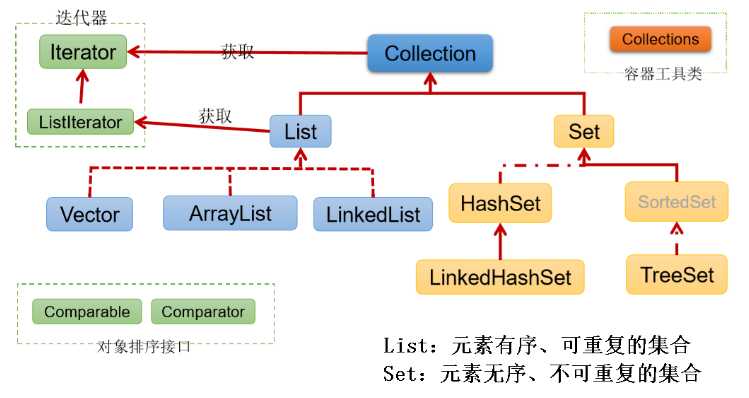
Map 接口:双列数据,保存具有映射关系 "key-value对" 的集合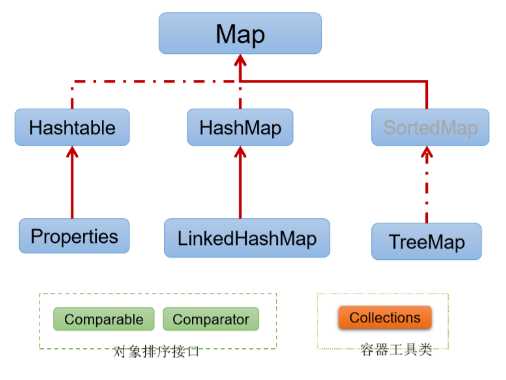
boolean add(Object obj) / addAll(Collection<?> coll):添加元素/某集合的所有元素int size():获取有效元素个数void clear():清空集合boolean isEmpty():是否是空集合boolean contains(Object obj):是通过元素的 equals() 来判断是否是同一个对象boolean containsAll(Collection<? extends E> c):也是调用元素的 equals() 来比较的。拿两个集合的元素挨个比较boolean remove(Object obj):通过元素的 equals() 判断是否是要删除的那个元素。只会删除找到的第 1 个元素boolean removeAll(Collection<?> coll):取当前集合的差集boolean retainAll(Collection<?> c):把交集的结果存在当前集合(this) 中,不影响形参集合 cboolean equals(Object obj):集合是否相等Object[] toArray():转成对象数组// ↑→ public static <T> List<T> asList(T... a)
List list = Arrays.asList(new Integer[]{1, 2, 3});
System.out.println(list); // [1, 2, 3]
List list2 = Arrays.asList(new int[]{1, 2, 3}); // 基本类型数组被当作一个元素
System.out.println(list2); // [[I@4554617c]
List list3 = Arrays.asList(1,2, 3);
System.out.println(list3); // [1, 2, 3]
int hashCode():获取集合对象的哈希值Iterator<E> iterator():返回迭代器对象,用于集合遍历public interface Collection<E> extends Iterable<E>Iterator 对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素Collection<I> 继承了 java.lang.Iterable<I>,该接口有一个 iterator(),那么所有实现了Collection<I> 的集合类都有一个 iterator(),用以返回一个实现了 Iterator<I> 的对象Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建 Iterator 对象,则必须有一个被迭代的集合iterator() 都得到一个全新的迭代器对象,游标(cursor) 默认都在集合的第 1 个元素之前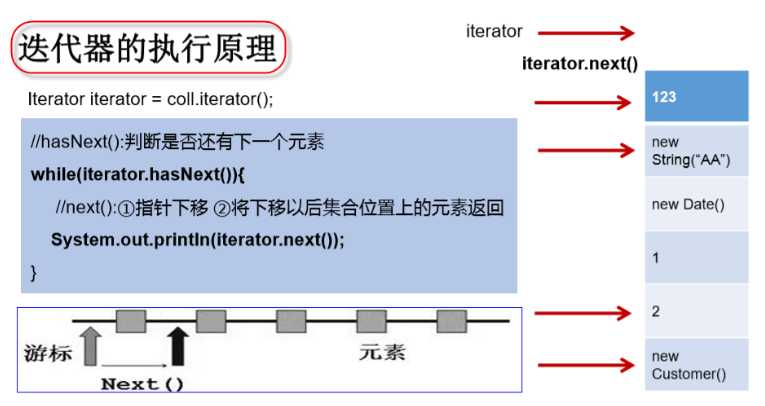
boolean hasNext():判断 iterator 内是否存在下1个元素,如果存在,返回true,否则返回false(注意,这时上面的那个指针位置不变)E next():返回 iterator 内下1个元素,同时上面的指针向后移动一位。如果不断地循环执行next()方法,就可以遍历容器内所有的元素了void remove():删除 iterator 内指针的前1个元素,前提是至少执行过1次 next()迭代的错误写法 // 在调用 it.next() 之前必须要调用 it.hasNext() 进行检测。若不调用,且下一条记录无效,直接调用 it.next() 会抛出 NoSuchElementException
Iterator it = c.iterator();
Object obj;
while((obj = it.next()) != null) // 第 c.size() + 1 次,会抛异常
System.out.println(obj);
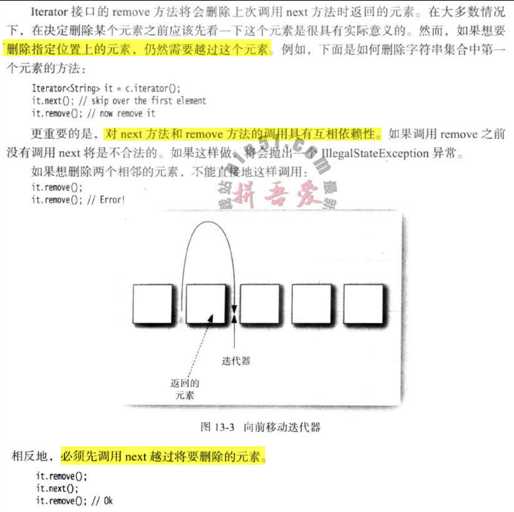
Iterator iter = coll.iterator();
while(iter.hasNext()) {
Object obj = iter.next();
if(obj.equals("Tom")) {
iter.remove();
}
}
remove(),不是集合对象的 remove(obj)next() 或在上一次调用 next() 之后已经调用了 remove(), 再调用 remove() 都会报 IllegalStateExceptionJDK5.0 起,提供了 for each 循环迭代访问 Collection 和 数组。编译器简单地将 for each 循环翻译为带有迭代器的循环。 for each 循环可以与任何实现了 Iterator<I> 的对象一起工作,这个接口直播暗含了一个方法:Iterator<E> iterator()。
Collection<I> 扩展了 Iterator<I>。因此,对于标准类库中的任何集合都可以使用 for each 循环。


List 替代数组List<I> 的实现类常用的有:ArrayList、LinkedList 和 VectorJDK 7
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private transient Object[] elementData;
private int size;
public ArrayList() {
this(10);
}
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
}
JDK 8
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData;
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
ArrayList list = new ArrayList(); // 底层创建了长度是 10 的 Object[] elementDatalist.add(123); // elementData[0] = new Integer(123);list.add(11); // 如果此次的添加导致底层 elementData[] 容量不够,则扩容ArrayList list = new ArrayList(int capacity)ArrayList list = new ArrayList(); // 底层 Object[] elementData 初始化为{},并没有创建长度为 10 的数组list.add(123); // 第一次调用 add() 时,底层才创建了长度 10 的数组,并将 数据123 添加到 elementData[0]public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {}
// 双向链表
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
}
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
void add(int index, E ele):在 index 位置插入 eleboolean addAll(int index, Collection<? extends E> c):从 index 位置开始将 c 中的所有元素添加进来E get(int index):获取指定 index 位置的元素int indexOf(E obj):返回 obj 在集合中首次出现的位置int lastIndexOf(E obj):返回 obj 在集合中末次出现的位置E remove(int index):移除指定 index 位置的元素,并返回此元素E set(int index, E ele):设置指定 index 位置的元素为 eleList<E> subList(int fromIndex, int toIndex):返回 [fromIndex, toIndex) 位置的子集合
Set<I> 是 Collection 的子接口,Set<I> 没有提供额外的方法Set<I> 不允许包含相同(根据 equals())的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败Set<I> 存储无序、不可重复的数据
equals() 判断时,不能返回 true,即相同的元素不能重复添加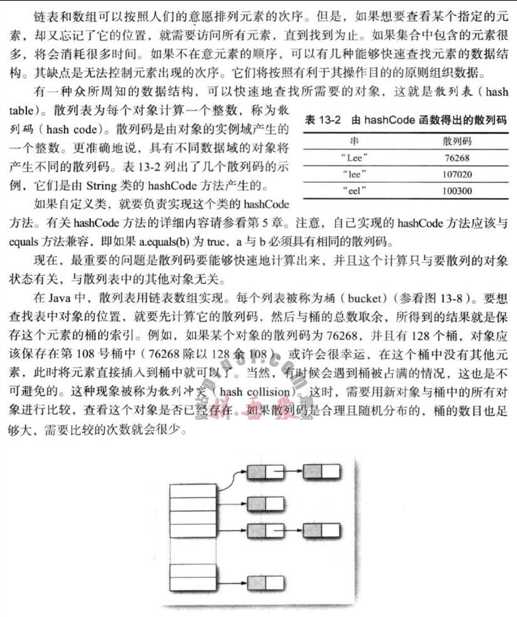

Set<I> 的典型实现,大多数时候使用 Set 集合时都使用这个实现类hashCode() 比较相等,并且两个对象的 equals() 返回值也相等equals() 和 hashCode(),以实现对象相等规则。即:"相等的对象必须具有相等的散列码"
hashCode() 的基本原则
hashCode() 应该返回相同的值equals() 比较返回 true 时,这两个对象的 hashCode() 的返回值也应相等equals() 比较的 Field,都应该用来计算 hashCode 值equals() 的基本原则
equals() 的时候,总是要改写 hashCode(),根据一个类的 equals()(改写后),两个截然不同的实例有可能在逻辑上是相等的。但是,根据 Object.hashCode(),它们仅仅是两个对象, 因此,违反了 "相等的对象必须具有相等的散列码"equals() 的时候一般都需要同时复写 hashCode()。通常参与计算 hashCode() 的对象的属性也应该参与到 equals() 中进行计算hashCode(),有 31 这个数字?
HashSet 底层:数组 + 链表的结构
当向 HashSet 集合中存入一个元素 a,HashSet 首先调用元素 a 所在类的 hashCode(),计算元素 a 的 hashCode 值,此 hashCode 值接着通过某种散列函数计算出在 HashSet 底层数组中的存放位置(这个散列函数会与底层数组的长度相计算得到在 数组中的下标,并且这种散列函数计算还尽可能保证能均匀存储元素,越是散列分布, 该散列函数设计的越好) ,判断数组此位置上是否已经有元素:
equals()
equals() 返回 true,则元素 a 添加失败equals() 返回 false,则元素 a 添加成功 ---> [情况3]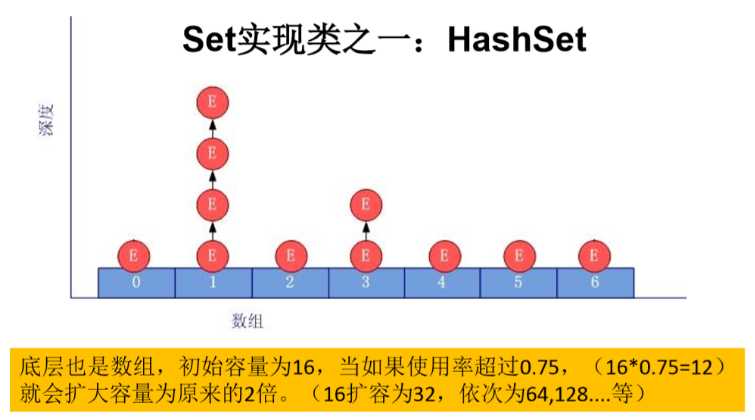
对于添加成功的 [情况2] 和 [情况3] 而言,元素 a 与已经存在指定索引位置上数据以链表的方式存储:
public void test() {
HashSet set = new HashSet();
Person p1 = new Person("AA",21);
Person p2 = new Person("BB",22);
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);
set.add(new Person("CC",21));
System.out.println(set);
set.add(new Person("AA",22));
System.out.println(set);
}
-------------------------------------
[Person{name=‘CC‘, age=21}, Person{name=‘BB‘, age=22}]
[Person{name=‘CC‘, age=21}, Person{name=‘BB‘, age=22}, Person{name=‘CC‘, age=21}]
[Person{name=‘CC‘, age=21}, Person{name=‘BB‘, age=22}, Person{name=‘CC‘, age=21}, Person{name=‘AA‘, age=22}]
TreeSet 是 SortedSet<I> 的实现类,TreeSet 可以确保集合元素处于排序状态TreeSet 底层使用 [红黑树] 结构存储数据Comparator<? super E> comparator()E first()E last()E lower(Object e)E higher(Object e)SortedSet<E> subSet(fromElement, toElement)SortedSet<E> headSet(toElement)SortedSet<E> tailSet(fromElement)TreeSet 会调用集合元素的 compareTo(T obj) 来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。所以,如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable<I>
Comparable 的典型实现:

compareTo(),后面添加的所有元素都会调用 compareTo() 进行比较compareTo(T obj) 比较返回值equals() 时,应保证该方法与 compareTo(T obj) 有一致的结果:如果两个对象通过 equals() 比较返回 true,则通过 compareTo(T obj) 比较应返回 0。 否则,让人难以理解。Comparable<I>,如果元素所属的类没有实现 Comparable<I>,或不希望按照升序(默认情况)的 方式排列元素或希望按照其它属性大小进行排序,则考虑使用 [定制排序]。定制排序,通过 Comparator<I> 来实现,需要重写 compare(T o1, T o2)int compare(T o1, T o2),比较 o1 和 o2 的大小:如果方法返回正整数,则表示 o1 大于 o2;如果返回 0,表示相等;返回负整数,表示 o1 小于 o2。Comparator 比较两个元素返回了 0Comparator<I> 的实例作为形参传递给 TreeSet 的构造器:TreeSet(Comparator<? super E> comparator)ClassCastException标签:out static images 双向链表 饿汉 overflow 遍历 使用 cte
原文地址:https://www.cnblogs.com/liujiaqi1101/p/13289266.html