标签:技术 html 文件 pycharm recent targe 下载 amp ted
Twisted安装不成功解决办法:把Twisted-17.1.0-cp36-cp36m-win_amd64.whl改为Twisted-17.1.0-py36-none-any.whl然后再进行安装。
Scrapy是一个大而全的爬虫组件;
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
window:
a. pip3 install wheel b. 下载twisted
c. cmd切换到Twisted目录,执行 pip3 install Twisted?17.1.0?py36?none-any.whl d. pip3 install scrapy
1、新建一个文件day125:C:\Python\zh\day125, 切换至此目录下
2、创建project
cmd创建一个project,名称为xdb ---在cmd中:
C:\Python\zh\day125>scrapy startproject xdb
执行上面命令后在day125中会自动生成一个名为xdb的项目,里面有两个文件:
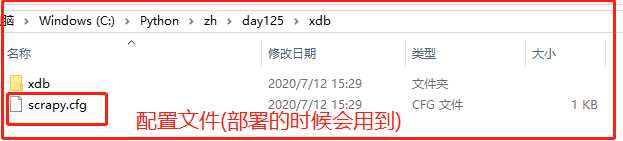
xdb文件中:
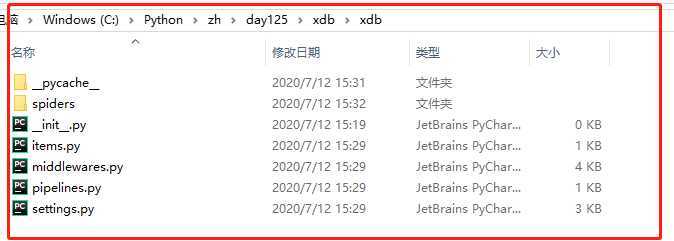
文件说明:
3、创建爬虫项目:
切换至xdb目录下,在cmd中:
C:\Python\zh\day125\xdb>scrapy genspider chouti chouti.com
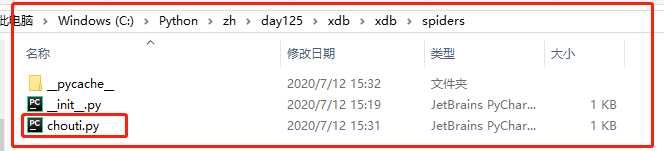
打开chouti.py:
#chouti.py import scrapy class ChoutiSpider(scrapy.Spider): name = ‘chouti‘ allowed_domains = [‘chouti.com‘] start_urls = [‘http://chouti.com/‘] def parse(self, response): pass
4、启动爬虫
scrapy crawl chouti
为了操作方便,在pycharm找到xdb项目并打开
chouti.py
在cmd中启动项目:

--nolog表示不打印日志。
-----------------------------------------------------------------------------------
爬取chouti新闻时:
chouti.py
import scrapy from scrapy.http.response.html import HtmlResponse # import sys,os,io # sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘) #如果项目启动出错可以开打上面两条命令 class ChoutiSpider(scrapy.Spider): name = ‘chouti‘ allowed_domains = [‘chouti.com‘] start_urls = [‘http://chouti.com/‘] def parse(self, response): # print(response,type(response)) # 对象 # print(response.text) """ from bs4 import BeautifulSoup soup = BeautifulSoup(response.text,‘html.parser‘) content_list = soup.find(‘div‘,attrs={‘id‘:‘content-list‘}) """ # xpath:帮助我们找标签,它是HTML内置的解析器 # //表示去当前html子孙中找div并且id=content-list # /表示去儿子里面去找div标签 f = open(‘news.log‘, mode=‘a+‘) #打开一个文件,a+:追加 item_list = response.xpath(‘//div[@id="content-list"]/div[@class="item"]‘) for item in item_list: text = item.xpath(‘.//a/text()‘).extract_first() #取第一个a标签的文本内存 href = item.xpath(‘.//a/@href‘).extract_first() #取第一个a标签的属性 print(href,text.strip()) f.write(href+‘\n‘) #写入爬取的内容 f.close() #上面写入的是第一页的数据,还需要跳转到第二页、第三页写入第二页数据 #找到分页的所有页面 page_list = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract() for page in page_list: from scrapy.http import Request page = "https://dig.chouti.com" + page yield Request(url=page,callback=self.parse) # https://dig.chouti.com/all/hot/recent/2 #通过yield Request()告诉scrapy再次向指定的url发起请求
标签:技术 html 文件 pycharm recent targe 下载 amp ted
原文地址:https://www.cnblogs.com/zh-xiaoyuan/p/13288343.html