标签:参数传递 bind 固定 UNC 栈内存 使用 缓存 现象 实现
ES6之前我们一般使用var来声明变量,提升简单来说就是把我们所写的类似于var a = 123;这样的代码,声明提升到它所在作用域的顶端去执行,到我们代码所在的位置来赋值。
function test() {
console.log(a); // undefined
a = 123;
}
test();
执行顺序如下:
function test() {
var a;
console.log(a); // undefined
a = 123;
}
test();
javascript中不仅仅是变量声明有提升的现象,函数的声明也是一样;具名函数的声明有两种方式:1. 函数声明式 2. 函数字面量式
function test() {} // 函数式声明
let test = function() {} // 字面量声明
函数提升是整个代码块提升到它所在的作用域的最开始执行
console.log(f);
function f() {
console.log(1);
}
// 相当于以下代码
function f() {
console.log(1);
}
console.log(f);
foo(); //1
var foo;
function foo () {
console.log(1);
}
foo = function () {
console.log(2);
}
call和apply其实是同一个东西,区别只有参数不同,call是apply的语法糖,所以就放在一起说了,这两个方法都是定义在函数对象的原型上的(Function.prototype),call和apply方法的作用都是改变函数的执行环境,第一个参数传入上下文执行环境,然后传入函数执行所需的参数。传入call的参数只能是单个参数,不能是数组。apply可传入数组。话不多说直接上代码,看下面的例子:
function ga() {
let x=1;
}
function gb(y) {
return x+y;
}
gb(2) //调用发生报错,因为拿不到x的值
gb.call(ga,2); //使gb在ga环境中执行,可以拿到x,运行正常
上面的代码中由于gb()函数执行依赖于ga()中的变量,所以我们使用了call将gb的运行环境变成了ga。
function gg(x,y,z){
let a=Array.prototype.slice.call(arguments,1,2) //通过slice方法获取到了第二个参数
return a; //返回[2]
}
gg(1,2,3)
// arguments是一个类数组对象,它本身不能调用数组的slice方法,使用call将执行slice方法的对象由数组变为了arguments。
使用apply改写上面的方法
function gg(x,y,z){
let d=[1,2]
let a=Array.prototype.slice.apply(arguments,d) //通过slice方法获取到了第二个参数
return a; //返回[2]
}
gg(1,2,3)
使用apply和call实现继承
function Parent(name) {
this.name = name;
this.sayHello = function() {
alert(name);
}
}
function Child(name) {
// 子类的this传给父类
Parent.call(this, name);
}
let parent = new Parent("张三");
let child = new Child("李四");
parent.sayHello();
child.sayHello();
bind和apply区别是apply会立刻执行,而bind只是起一个绑定执行上下文的作用。看下面的例子:
function ga() {
let x=1;
(function gb(y) {
return x+y;
}).bind(this) //使用bind将gb函数的执行上下文绑定到ga上
}
gb(2) //运行正常,得到3
// 有些情况下为了方便我们可以直接将ga绑定,而不用在调用的时候再使用apply。
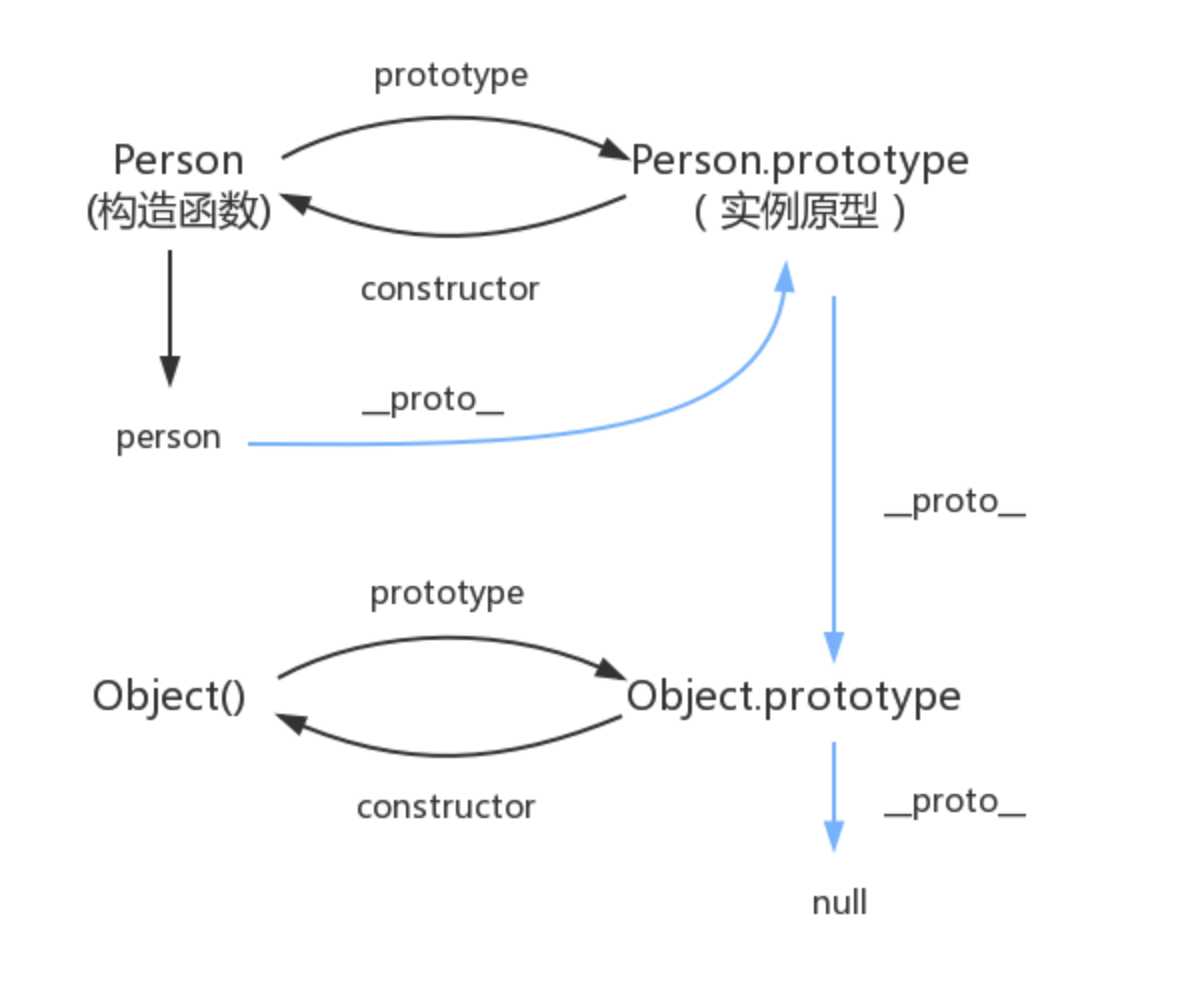
在JavaScript中,每个函数都有一个prototype属性,这个属性指向函数的原型对象(原型就是一个Object的实例,是一个对象)
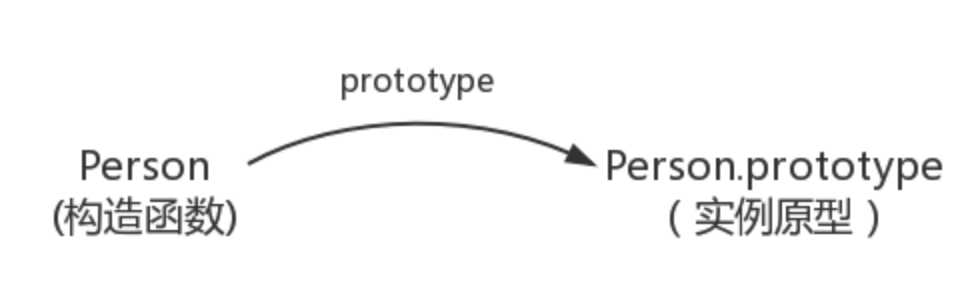
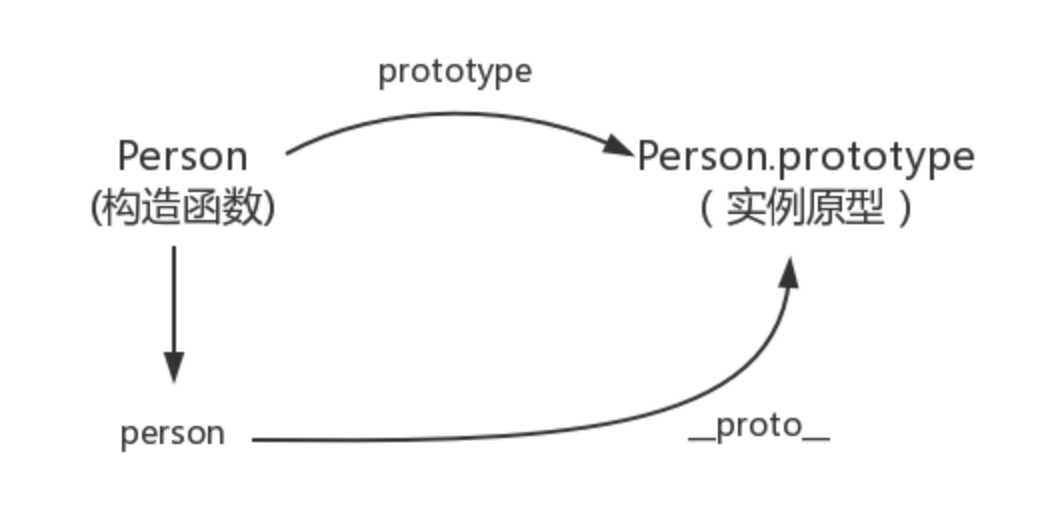
每个对象(除null外)都会有的属性,叫做__proto__,这个属性会指向该对象的原型;绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中,实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter,当使用 obj.__proto__ 时,可以理解成返回了 Object.getPrototypeOf(obj)。
每个原型都有一个constructor属性,指向该关联的构造函数
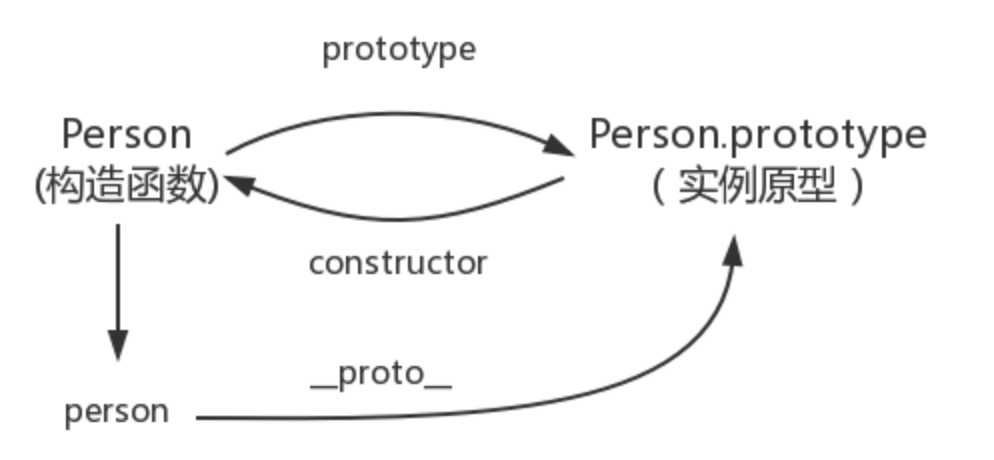
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止
原型的原型是什么?
其实原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 __proto__ 指向构造函数的 prototype
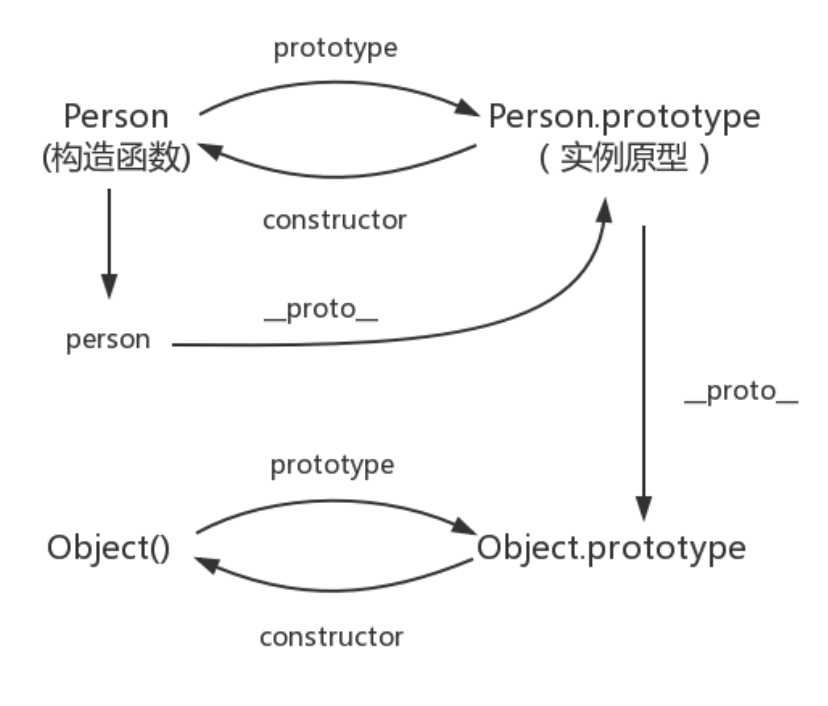
简单的回顾一下构造函数、原型和实例的关系:每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。那么假如我们让原型对象等于另一个类型的实例,结果会怎样?显然,此时的原型对象将包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。假如另一个原型又是另一个类型的实例,那么上述关系依然成立。如此层层递进,就构成了实例与原型的链条。这就是所谓的原型链的基本概念。
如图所示:蓝色即为原型链。
面向对象语言中 this 表示当前对象的一个引用。
但在 JavaScript 中 this 不是固定不变的,它会随着执行环境的改变而改变。
function foo() {
console.log(this.a)
}
var a = 1
foo()
var obj = {
a: 2,
foo: foo
}
obj.foo()
// 以上两者情况 `this` 只依赖于调用函数前的对象,优先级是第二个情况大于第一个情况
// 以下情况是优先级最高的,`this` 只会绑定在 `c` 上,不会被任何方式修改 `this` 指向
var c = new foo()
c.a = 3
console.log(c.a)
1
2
undefined
3
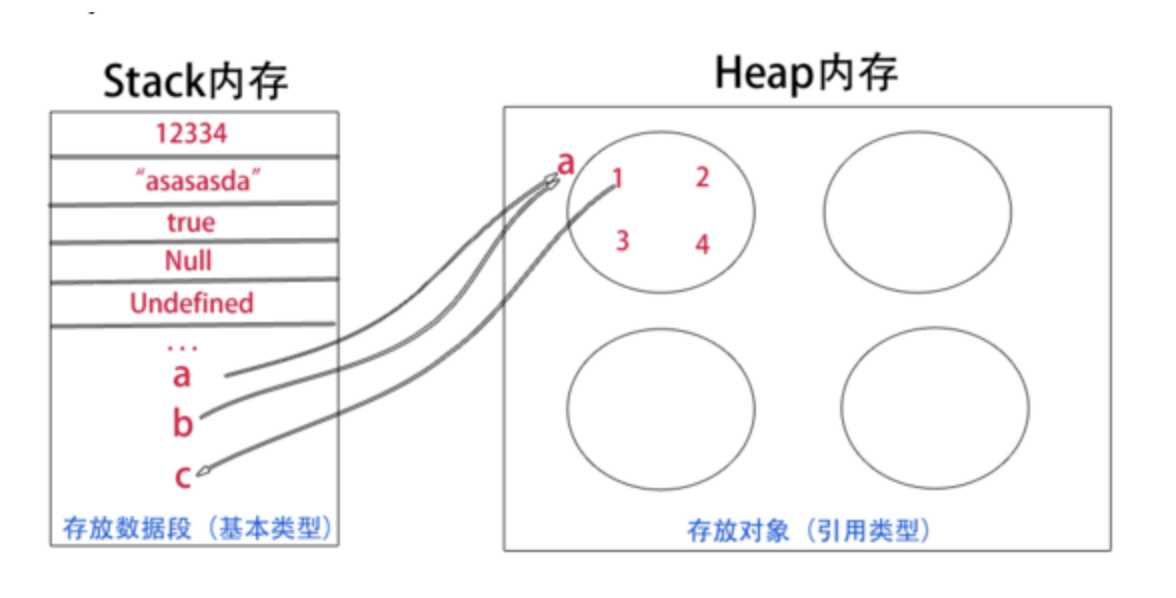
这里先说两个概念:1、堆(heap)2、栈(stack)
堆 是堆内存的简称。
栈 是栈内存的简称。
说到堆栈,我们讲的就是内存的使用和分配了,没有寄存器的事,也没有硬盘的事。
各种语言在处理堆栈的原理上都大同小异。堆是动态分配内存,内存大小不一,也不会自动释放。栈是自动分配相对固定大小的内存空间,并由系统自动释放。
javascript的基本类型就5种:Undefined、Null、Boolean、Number和String,它们都是直接按值存储在栈中的,每种类型的数据占用的内存空间的大小是确定的,并由系统自动分配和自动释放。这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
javascript中其他类型的数据被称为引用类型的数据 : 如对象(Object)、数组(Array)、函数(Function) …,它们是通过拷贝和new出来的,这样的数据存储于堆中。其实,说存储于堆中,也不太准确,因为,引用类型的数据的地址指针是存储于栈中的,当我们想要访问引用类型的值的时候,需要先从栈中获得对象的地址指针,然后,在通过地址指针找到堆中的所需要的数据。
说来也是形象,栈,线性结构,后进先出,便于管理。堆,一个混沌,杂乱无章,方便存储和开辟内存空间;
generator生成器的设计原理:
应用场景:
整个 Generator 函数就是一个封装的异步任务,或者说是异步任务的容器。异步操作需要暂停的地方,都用yield语句注明
Generator 函数是协程在 ES6 的实现,最大特点就是可以交出函数的执行权(即暂停执行)
generator生成器和iterator遍历器是对应的,我们知道iterator遍历器是给不同数据结构提供统一的数据接口机制,那么相对的generator生成器是生成这样一个遍历器,进而使数据结构拥有iterator遍历器接口。换一种方法来说,generator函数提供了可供遍历的状态,所以generator是一个状态机,在其内部封装了多个状态,这些状态可以使用iterator遍历器遍历。
注意:既然generator是一个状态机,所以直接运行generator()函数,并不会执行,相反的是生成一个指向内部状态的指针对象,即一个可供遍历的遍历器。
想运行generator,必须调用遍历器对象的next方法,使得指针移向下一个状态,直到遇到下一个yield表达式(或return语句)为止。Generator 函数是分段执行的,yield表达式是暂停执行的标记,而next方法可以恢复执行。
const test = testGen();
test.next()
// { value: ‘1‘, done: false }
test.next()
// { value: ‘2‘, done: false }
test.next()
// { value: ‘ending‘, done: true }
test.next()
// { value: undefined, done: true }
// 函数有三个状态 1,2,return
function* testGen() {
yield ‘1‘;
yield ‘2‘;
return ‘end‘;
}
Generator的原型方法:
Generator.prototype.throw(),Generator.prototype.return()
throw() 在函数体外抛出错误,然后在 Generator 函数体内捕获
return():返回给定的值,并且终结遍历 Generator 函数
next()、throw()、return() 的共同点
作用都是让 Generator 函数恢复执行,并且使用不同的语句替换yield表达式(带入参)
next()是将yield表达式替换成一个值
throw()是将yield表达式替换成一个throw语句
return()是将yield表达式替换成一个return语句
async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。
(看了很多遍还不是很明白~)
async function fn(args) {
// ...
}
// 等同于
function fn(args) {
return spawn(function* () {
// ...
});
}
function spawn(genF) {
return new Promise(function(resolve, reject) {
const gen = genF();
function step(nextF) {
let next;
try {
next = nextF();
} catch(e) {
return reject(e);
}
if(next.done) {
return resolve(next.value);
}
Promise.resolve(next.value).then(function(v) {
step(function() { return gen.next(v); });
}, function(e) {
step(function() { return gen.throw(e); });
});
}
step(function() { return gen.next(undefined); });
});
}
promise的核心原理其实就是发布订阅模式,通过两个队列来缓存成功的回调(onResolve)和失败的回调(onReject)。
promise的特点:
(1) 构造函数
function Promise(resolver) {}
(2) 原型方法
Promise.prototype.then = function() {}
Promise.prototype.catch = function() {}
(3) 静态方法
Promise.resolve = function() {}
Promise.reject = function() {}
Promise.all = function() {}
Promise.race = function() {}
function Promise (executor) {
var self = this;//resolve和reject中的this指向不是promise实例,需要用self缓存
self.state = ‘padding‘;
self.value = ‘‘;//缓存成功回调onfulfilled的参数
self.reson = ‘‘;//缓存失败回调onrejected的参数
self.onResolved = []; // 专门存放成功的回调onfulfilled的集合
self.onRejected = []; // 专门存放失败的回调onrejected的集合
function resolve (value) {
if(self.state===‘padding‘){
self.state===‘resolved‘;
self.value=value;
self.onResolved.forEach(fn=>fn())
}
}
function reject (reason) {
self.state = ‘rejected‘;
self.value = reason;
self.onRejected.forEach(fn=>fn())
}
try{
executor(resolve,reject)
}catch(e){
reject(e)
}
}
Promise.prototype.then=function (onfulfilled,onrejected) {
var self=this;
if(this.state===‘resolved‘){
onfulfilled(self.value)
}
if(this.state===‘rejected‘){
onrejected(self.value)
}
if(this.state===‘padding‘){
this.onResolved.push(function () {
onfulfilled(self.value)
})
}
}
Promise.prototype.catch = function (onrejected) {
return this.then(null, onrejected)
};
Promise.reject = function (reason) {
return new Promise((resolve, reject) => {
reject(reason)
})
};
Promise.resolve = function (value) {
return new Promise((resolve, reject) => {
resolve(value);
})
};
Promise.all=function (promises) {
return new Promise((resolve,reject)=>{
let results=[],i=0;
for(let i=0;i<promises.length;i++){
let p=promises[i];
p.then((data)=>{
processData(i,data)
},reject)
}
function processData (index,data) {
results[index]=data;
if(++i==promises.length){
resolve(results)
}
}
})
};
//在每个promise的回调中添加一个resolve(就是在当前的promise.then中添加),有一个状态改变,就让race的状态改变
Promise.race=function (promises) {
return new promises((resolve,reject)=>{
for(let i=0;i<promises.length;i++){
let p=promises[i];
p.then(resolve,reject)
}
})
一般来说没有被引用的对象就是垃圾,就是要被清除, 有个例外如果几个对象引用形成一个环,互相引用,但根访问不到它们,这几个对象也是垃圾,也要被清除。
JS中最常见的垃圾回收方式是标记清除。
工作原理:是当变量进入环境时,将这个变量标记为“进入环境”。当变量离开环境时,则将其标记为“离开环境”。标记“离开环境”的就回收内存。
工作流程:
1. 垃圾回收器,在运行的时候会给存储在内存中的所有变量都加上标记。
2. 去掉环境中的变量以及被环境中的变量引用的变量的标记。
3. 再被加上标记的会被视为准备删除的变量。
4. 垃圾回收器完成内存清除工作,销毁那些带标记的值并回收他们所占用的内存空间。
引用计数 方式
工作原理:跟踪记录每个值被引用的次数。
工作流程:
1. 声明了一个变量并将一个引用类型的值赋值给这个变量,这个引用类型值的引用次数就是1。
2. 同一个值又被赋值给另一个变量,这个引用类型值的引用次数加1.
3. 当包含这个引用类型值的变量又被赋值成另一个值了,那么这个引用类型值的引用次数减1.
4. 当引用次数变成0时,说明没办法访问这个值了。
5. 当垃圾收集器下一次运行时,它就会释放引用次数是0的值所占的内存。
新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。
在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。
在讲算法前,先来说下什么情况下对象会出现在老生代空间中:
这个问题通常可以通过 JSON.parse(JSON.stringify(object)) 来解决。
但是该方法也是有局限性的:
undefinedsymbol手动实现:
// 定义一个深拷贝函数 接收目标target参数
function deepClone(target) {
// 定义一个变量
let result;
// 如果当前需要深拷贝的是一个对象的话
if (typeof target === ‘object‘) {
// 如果是一个数组的话
if (Array.isArray(target)) {
result = []; // 将result赋值为一个数组,并且执行遍历
for (let i in target) {
// 递归克隆数组中的每一项
result.push(deepClone(target[i]))
}
// 判断如果当前的值是null的话;直接赋值为null
} else if(target===null) {
result = null;
// 判断如果当前的值是一个RegExp对象的话,直接赋值
} else if(target.constructor===RegExp){
result = target;
}else {
// 否则是普通对象,直接for in循环,递归赋值对象的所有值
result = {};
for (let i in target) {
result[i] = deepClone(target[i]);
}
}
// 如果不是对象的话,就是基本数据类型,那么直接赋值
} else {
result = target;
}
// 返回最终结果
return result;
}
标签:参数传递 bind 固定 UNC 栈内存 使用 缓存 现象 实现
原文地址:https://www.cnblogs.com/tjyoung/p/13288874.html