标签:命令 核心 splay color use eric with 数据库 box
水平有限,本文仅以流水账的方式 介绍自己 安装 三款软件 的过程。
环境Ubuntu on 虚拟机:
$ cat /proc/version Linux version 4.15.0-54-generic (buildd@lgw01-amd64-014) (gcc version 7.4.0 \
(Ubuntu 7.4.0-1ubuntu1~18.04.1)) #58-Ubuntu SMP Mon Jun 24 10:55:24 UTC 2019
背景
Hadoop 包含 HDFS、MapReduce(两大核心),基于 Hadoop core 实现,对了Hadoop中还有一款 资源管理器YARN。
HBase 一个分布式数据库,列存储模式,HBase将数据存储在HDFS(基于),分布式NoSQL数据库,类似MongoDB、Cassandra,不过,可以处理的数据量级大于MongoDB。
Spark 是一个计算框架,为了解决Hadoop的计算效率低下等问题而生,它基于内存做计算,可以基于Hadoop,也可以不和Hadoop一起使用。
三款软件都属于 Apache基金会,从下面的链接中可以找到 各个软件(Download & Documentation):
https://www.apache.org/index.html#projects-list
安装选择的版本:
Hadoop:hadoop-3.1.3.tar.gz 2019 Oct 21
HBase:hbase-2.2.5-bin.tar.gz 2020/05/21
Spark:spark-3.0.0-bin-hadoop3.2.tgz Jun 18, 2020
注意,
HBase 1.*、2.* 的区别是什么?其 1.6.0 发布于 2020/03/06,看来两个版本都是处于 很好的维护阶段。
spark with hadoop、without hadoop的区别是什么?
作者还没弄明白。
正文
0、准备工作
创建 hadoop用户(不一定是 hadoop),并添加 管理员权限

JDK 8+(Linux上有 OpenJDK 的)
ssh、sshd、pdsh
三种安装模式中的 Pseudo-Distributed Mode(伪分布式) 模式 + YARN资源调度器。
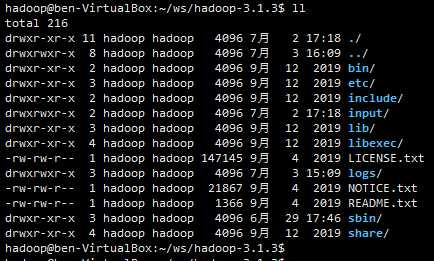
解压hadoop-3.1.3.tar.gz;
修改 etc/hadoop/hadoop-env.sh:
添加export JAVA_HOME=jdk安装目录;
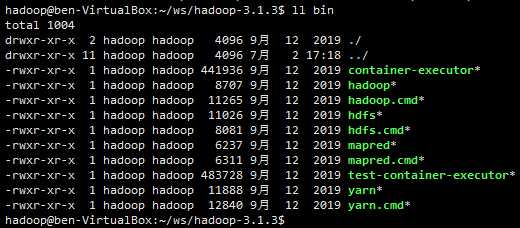
执行 bin/hadoop 可以看到 这个命令的用户;
bin目录 下是 一些 原始命令,sbin目录 下 是 一些服务命令——启动、停止等。
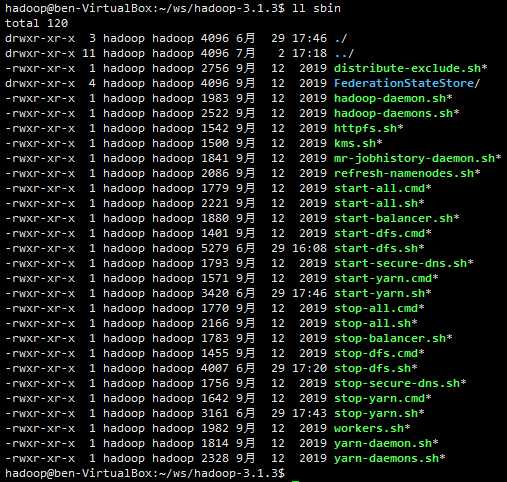
此时,hadoop命令就可以使用了,如官网所说,可以执行一些任务了。
etc下文件:

$ ll etc/hadoop/ total 184 drwxr-xr-x 3 hadoop hadoop 4096 7月 9 08:46 ./ drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 ../ -rw-r--r-- 1 hadoop hadoop 8260 9月 12 2019 capacity-scheduler.xml -rw-r--r-- 1 hadoop hadoop 1335 9月 12 2019 configuration.xsl -rw-r--r-- 1 hadoop hadoop 1940 9月 12 2019 container-executor.cfg -rw-r--r-- 1 hadoop hadoop 866 6月 29 15:50 core-site.xml -rw-r--r-- 1 hadoop hadoop 3999 9月 12 2019 hadoop-env.cmd -rw-r--r-- 1 hadoop hadoop 15934 6月 29 14:48 hadoop-env.sh -rw-r--r-- 1 hadoop hadoop 3323 9月 12 2019 hadoop-metrics2.properties -rw-r--r-- 1 hadoop hadoop 11392 9月 12 2019 hadoop-policy.xml -rw-r--r-- 1 hadoop hadoop 3414 9月 12 2019 hadoop-user-functions.sh.example -rw-r--r-- 1 hadoop hadoop 1072 6月 30 15:03 hdfs-site.xml -rw-r--r-- 1 hadoop hadoop 1484 9月 12 2019 httpfs-env.sh -rw-r--r-- 1 hadoop hadoop 1657 9月 12 2019 httpfs-log4j.properties -rw-r--r-- 1 hadoop hadoop 21 9月 12 2019 httpfs-signature.secret -rw-r--r-- 1 hadoop hadoop 620 9月 12 2019 httpfs-site.xml -rw-r--r-- 1 hadoop hadoop 3518 9月 12 2019 kms-acls.xml -rw-r--r-- 1 hadoop hadoop 1351 9月 12 2019 kms-env.sh -rw-r--r-- 1 hadoop hadoop 1747 9月 12 2019 kms-log4j.properties -rw-r--r-- 1 hadoop hadoop 682 9月 12 2019 kms-site.xml -rw-r--r-- 1 hadoop hadoop 13326 9月 12 2019 log4j.properties -rw-r--r-- 1 hadoop hadoop 951 9月 12 2019 mapred-env.cmd -rw-r--r-- 1 hadoop hadoop 1764 9月 12 2019 mapred-env.sh -rw-r--r-- 1 hadoop hadoop 4113 9月 12 2019 mapred-queues.xml.template -rw-r--r-- 1 hadoop hadoop 1027 6月 29 16:49 mapred-site.xml drwxr-xr-x 2 hadoop hadoop 4096 9月 12 2019 shellprofile.d/ -rw-r--r-- 1 hadoop hadoop 2316 9月 12 2019 ssl-client.xml.example -rw-r--r-- 1 hadoop hadoop 2697 9月 12 2019 ssl-server.xml.example -rw-r--r-- 1 hadoop hadoop 2642 9月 12 2019 user_ec_policies.xml.template -rw-r--r-- 1 hadoop hadoop 10 9月 12 2019 workers -rw-r--r-- 1 hadoop hadoop 2250 9月 12 2019 yarn-env.cmd -rw-r--r-- 1 hadoop hadoop 6056 9月 12 2019 yarn-env.sh -rw-r--r-- 1 hadoop hadoop 2591 9月 12 2019 yarnservice-log4j.properties -rw-r--r-- 1 hadoop hadoop 1159 6月 29 17:41 yarn-site.xml hadoop@ben-VirtualBox:~/ws/hadoop-3.1.3$
参考官网,进一步安装 Pseudo-Distributed Mode 的 hadoop。
修改 etc/hadoop/core-site.xml;
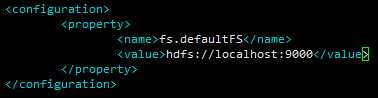
修改 etc/hadoop/hdfs-site.xml:比官网多了 namenode、datanode 的配置,,默认是在 /tmp目录下,重启后 数据丢失,下次由需要重新 格式化,,整个HDFS中,只会有一个 namenode,但是,<value>属性 可以配置 多个值(看到过一篇博文,首个目录后的为 备用)。
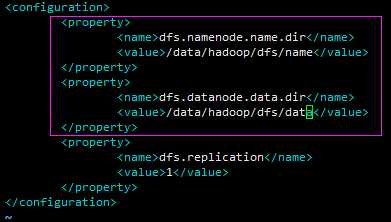
配置无密码登录(ssh localhost):在用户的 HOME目录 下执行,执行后会有 .ssh文件夹
ssh-keygen
上面的配置后,HDFS可用了,也可以执行 hadoop任务(描述准确吗?)。
使用前,需要执行HDFS格式化:
$ bin/hdfs namenode -format
启动HDFS:
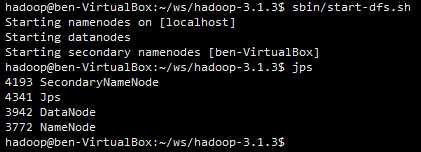
$ sbin/start-dfs.sh
此时,使用 jps命令 可以看到 namenode、datanode、SecondaryNameNode等Java进程:
使用 http://localhost:9870/ 可以看到 一些hadoop的信息。
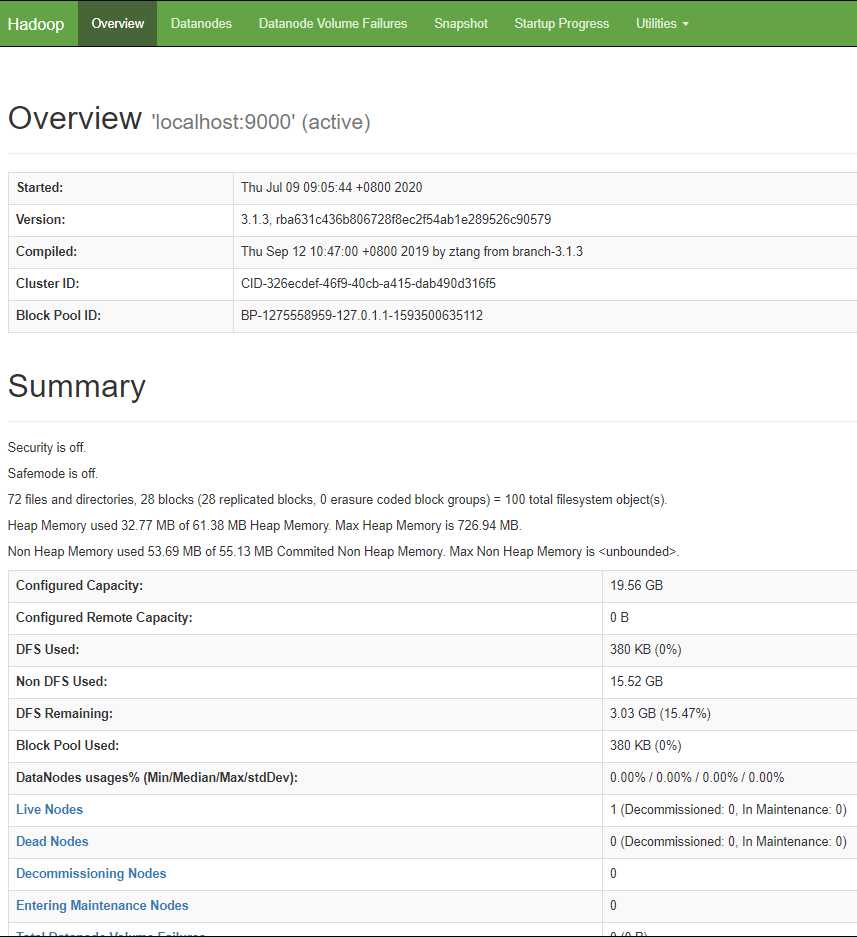
如 官网所讲,此时,可以使用 bin/hdfs 命令 操作HDFS了,建立文件夹、操作文件等。
HDFS 就是一个 以 根目录(/) 为节点的 分布式文件系统,目录结构类似 Linux系统,但是,默认的 根目录下 没有内容。
接下来,配置YARN资源调度器。
修改etc/hadoop/mapred-site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
修改etc/hadoop/yarn-site.xml:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
注意,
配置 yarn.nodemanager.vmem-check-enabled 是为了 避免 任务需要的内存超过虚拟内存大小 时,任务自动失败 的问题。
使用下面的命令 即可 启动yarn资源调度器:
$ sbin/start-yarn.sh
启动成功,使用 jps命令 可以看到其进程:NodeManager、ResourceManager:
~/ws/hadoop-3.1.3$ sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers hadoop@ben-VirtualBox:~/ws/hadoop-3.1.3$ jps 4193 SecondaryNameNode 3942 DataNode 5320 NodeManager 5130 ResourceManager 3772 NameNode 5647 Jps ~/ws/hadoop-3.1.3$
访问下面的链接 可以看到 资源管理器:
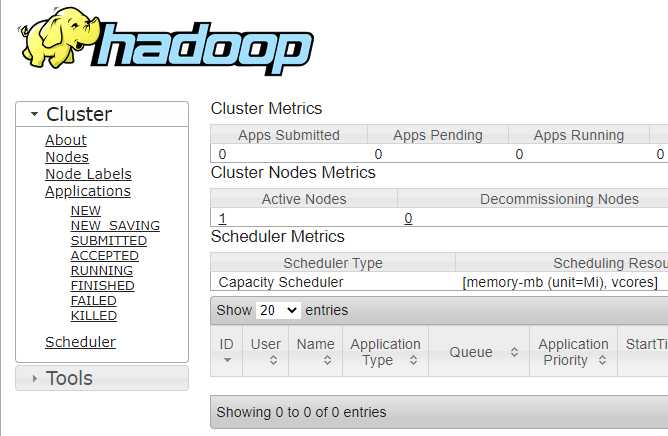
和前一步 没有启动yarn一样 执行hadoop任务,可以在这个页面 看到 任务执行详情。
参考链接:
http://hbase.apache.org/book.html#quickstart
https://foochane.cn/article/2019062801.html
下载2.2.5:hbase-2.2.5-bin.tar.gz;
解压:tar xzvf hbase-2.2.5-bin.tar.gz;
修改 hbase-env.sh:export JAVA_HOME、export HBASE_MANAGES_ZK=false;
修改 hbase-site.xml :hbase.rootdir、hbase.zookeeper.quorum——端口为2182;
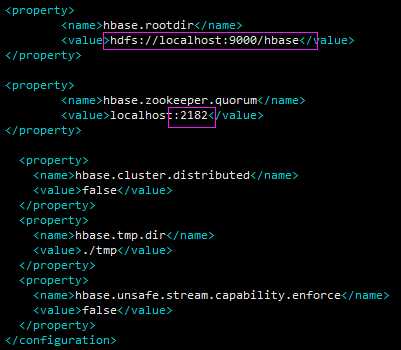
单机 伪分布式部署,故,无需更改 regionservers 文件:默认为 localhost;
配置修改环境。
确保 hdfs、ZooKeeper 已启动,然后,启动 hbase:bin/start-hbase.sh;
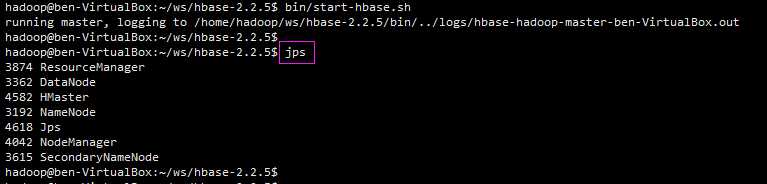
HMaster启动了,成功!
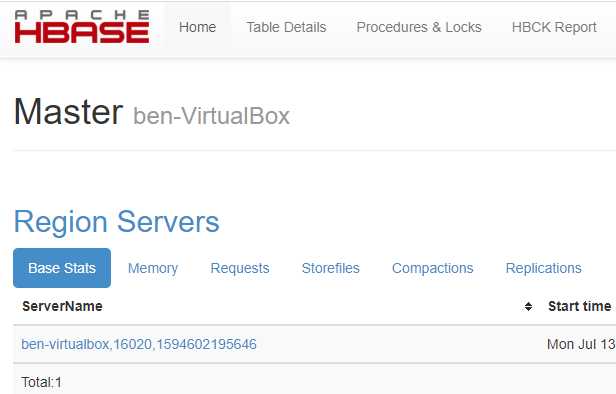
此时,可以访问 localhost:16010 (旧版本的端口 不是 16010);
bin目录下文件:
重点:
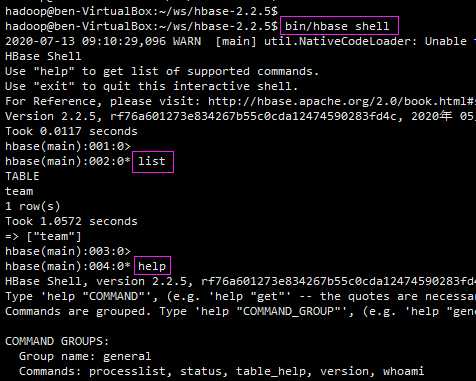
hbase启动后,可以通过 HBase shell 操作它。
list、help……需要摸索,和操作一般数据库差不多。
HBase 启动后,在 HDFS 下会建立一个 /hbase目录:
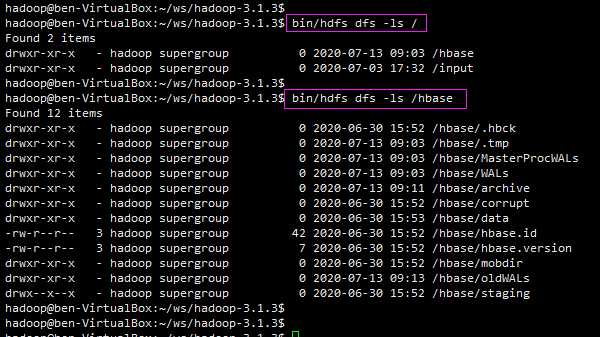
至此,HBase 单机伪分布式 安装完毕。

提前安装Scala:
下载scala-2.13.3.tgz,解压,修改 ~/.bashrc文件(修改后执行 source);
命令行输入 scala,进入交互式命令行:
开始Spark安装:
下载 spark-3.0.0-bin-hadoop3.2.tgz , 解压;
修改spark-env.sh;
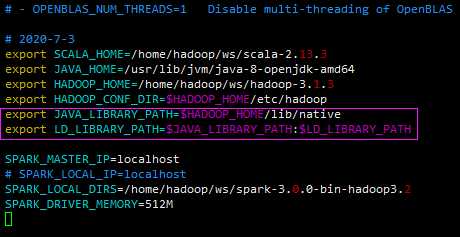
单机,无需更改 slaves;
修改 ~/.bashrc文件:

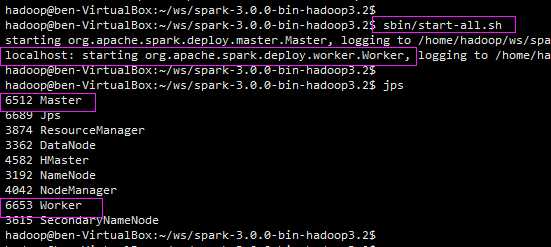
启动Hadoop后,启动Spark:
$SPARK_HOME/sbin/start-all.sh
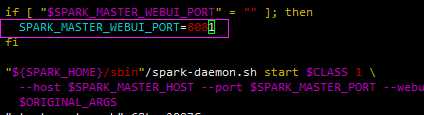
注意,
start-all.sh 中会启动 start-master.sh ,其中会配置 Master的 端口为 8080,会存在 冲突,修改后才可以启动成功。
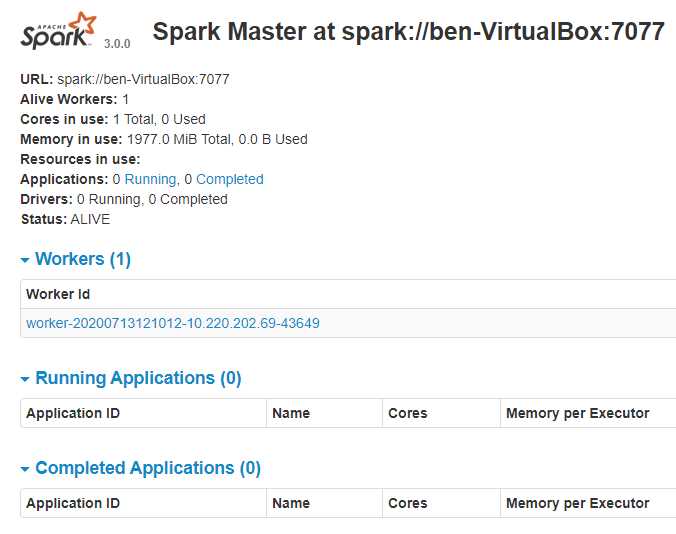
访问 localhost:8081 可得:
说明,start-history-server.sh 的作用 未测试,不启动也是可以的。
bin目录 下的文件列表:
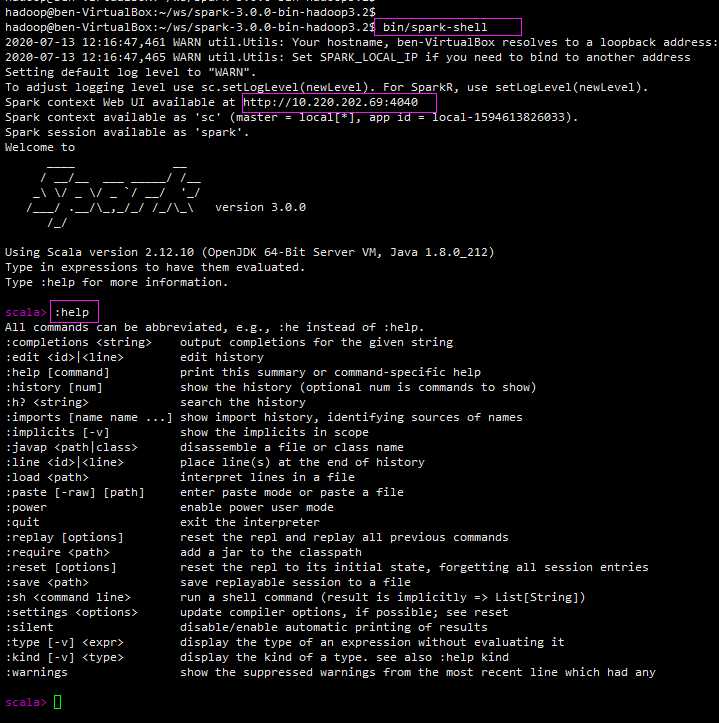
执行 spark-shell 启动 交互式接口;
启动成功,则可以使用 4040端口访问:
Spark启动了,接下来,怎么使用Spark呢?
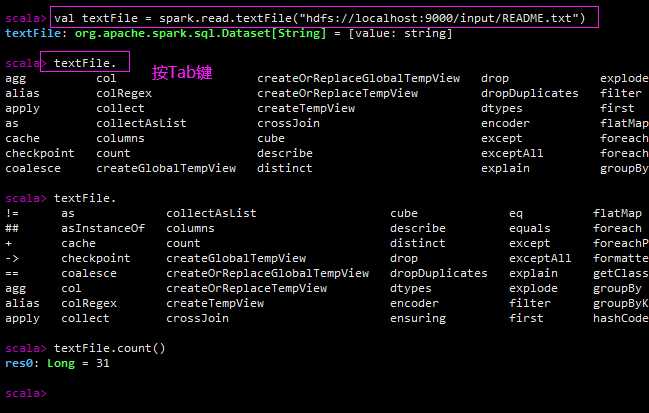
统计HDFS中一个文件的行数:
4040端口 所在的页面 可以看到 任务 更详细的信息:
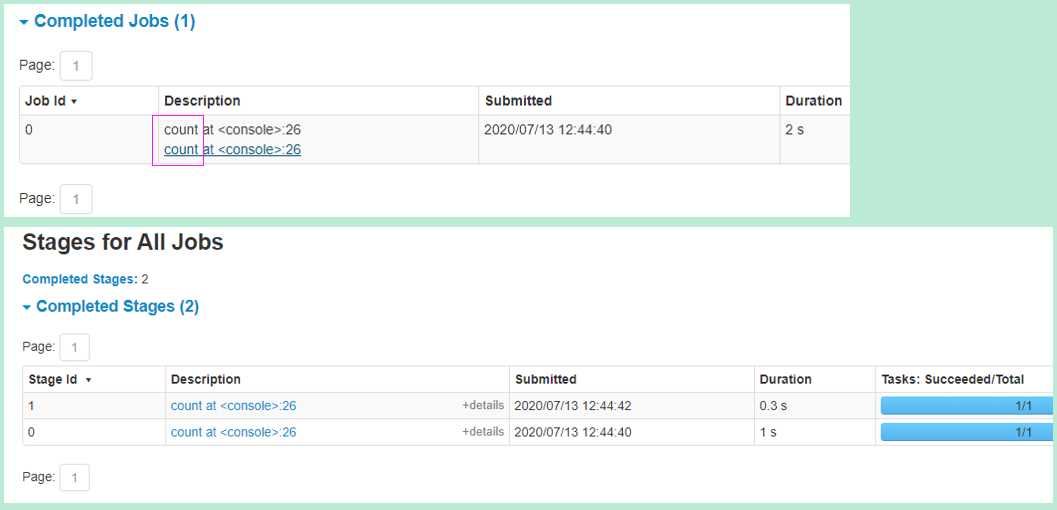
就这样,
安装好了,接下来 可以 一边学习 一边实践了(Learning by Doing) ......
参考资料:
1、Hadoop: Setting up a Single Node Cluster.
https://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-common/SingleCluster.html
2、网友 foochane 的 大数据 分类
https://foochane.cn/categories/%E5%A4%A7%E6%95%B0%E6%8D%AE/page/2/
hadoop https://foochane.cn/article/2019051901.html
hbase https://foochane.cn/article/2019062801.html
spark https://foochane.cn/article/2019051904.html
后记
作者尽量保证文章的准确性,如有谬误,还请指正(不强求)。
yarn.nodemanager.vmem-check-enabled
标签:命令 核心 splay color use eric with 数据库 box
原文地址:https://www.cnblogs.com/luo630/p/13271637.html
