标签:分析 image 其他 line rar nis 线性变换 width margin
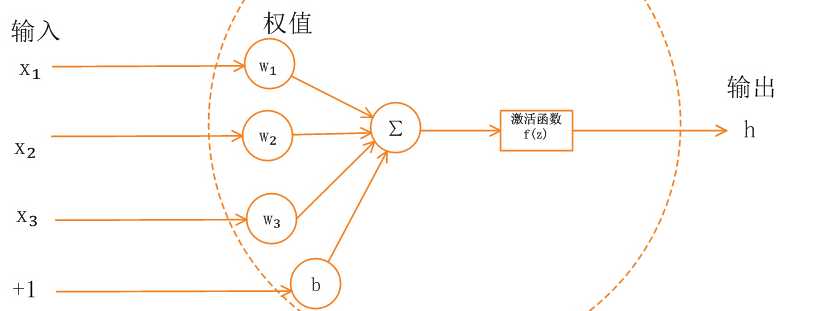
如果我们不使用过激活函数,那么输出将是输入的线性变换,无论最终多少层,都只是线性变换,为了增强神经网络学习任何函数的能力,需要在其中引入非线性的单元,这个单元就是激活函数。
激活函数大致分为两类,饱和和非饱和:

Sigmoid 是常用的非线性的激活函数,它的数学形式如下:
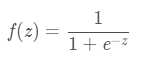
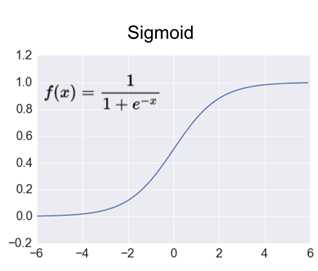
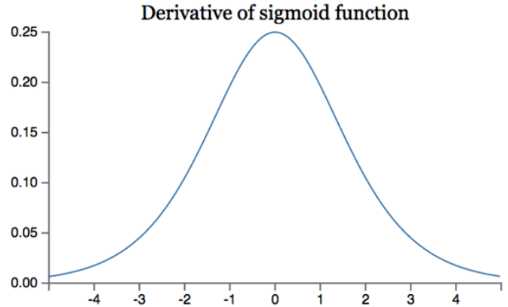
如果我们初始化神经网络的权值为 [0,1] 之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,由于sigmoid函数的导数最大为1/4,所以会导致越乘越小,最终导致梯度消失;当网络权值初始化为 (1,+∞) (1,+∞)(1,+∞) 区间内的值,则会出现梯度爆炸情况。
数学分析见文章::https://www.jianshu.com/p/917f71b06499
Sigmoid 的 output 不是0均值(即zero-centered)。这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间.
tanh函数解析式:
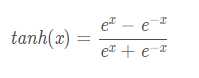
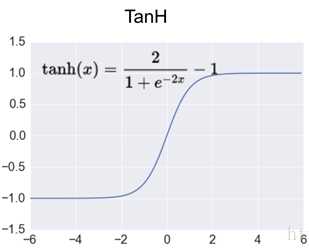
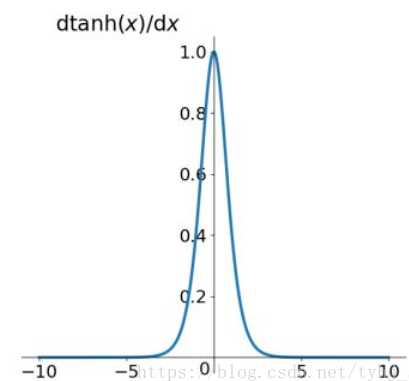
它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
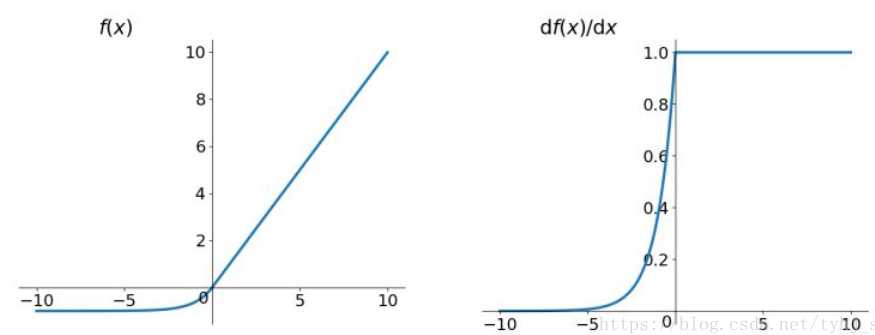
Relu函数的解析式:
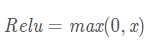
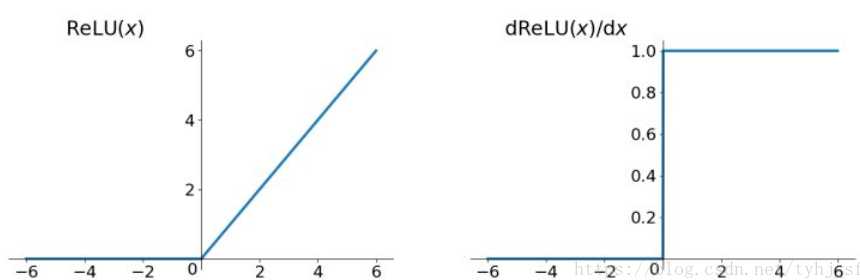
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
(1)ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和;
(2)由于ReLU线性、非饱和的形式,在SGD中能够快速收敛;
(3)算速度要快很多。ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快
ReLU也有几个需要特别注意的问题:
1)ReLU的输出不是zero-centered
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
为了解决神经元节点死亡的情况,有人提出了Leaky ReLU、P-ReLu、R-ReLU、ELU等激活函数。
函数表达式:
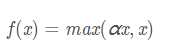
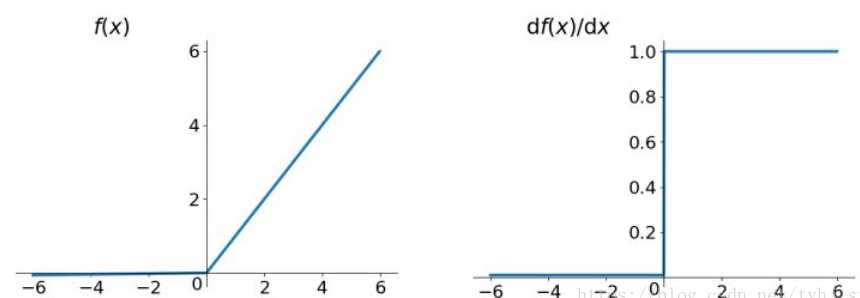
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为αx \alpha xαx而非0,通常α=0.01 \alpha=0.01α=0.01。另外一种直观的想法是基于参数的方法,即ParametricReLU:f(x)=max(αx,x) Parametric ReLU:f(x) = \max(\alpha x, x)ParametricReLU:f(x)=max(αx,x),其中α \alphaα
可由方向传播算法学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
RReLU的英文全称是“Randomized Leaky ReLU”,中文名字叫“随机修正线性单元”。RReLU是Leaky ReLU的随机版本。它首次是在Kaggle的NDSB比赛中被提出来的,其图像和表达式如下图所示:
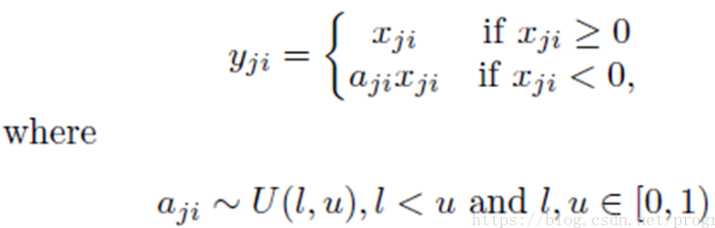
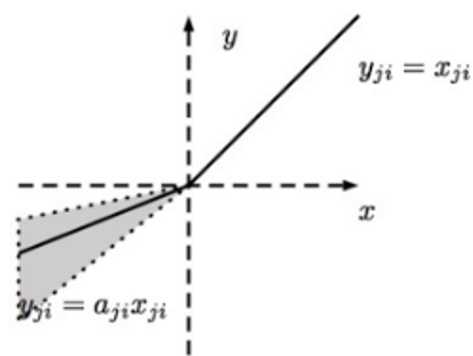
RReLU的核心思想是,在训练过程中,α是从一个高斯分布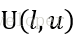
取个平均值。
它试图将激活函数的输出平均值接近零,从而加快学习速度函数表达式:
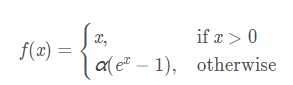
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
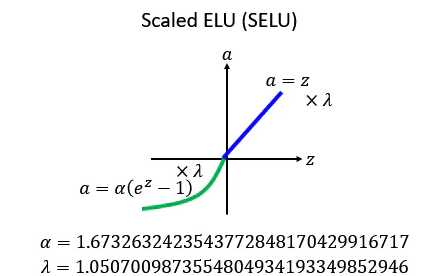
扩展型指数线性单元激活函数比较新,介绍它的论文包含长达 90 页的附录(包括定理和证明等)。当实际应用这个激活函数时,必须使用 lecun_normal 进行权重初始化。如果希望应用 dropout,则应当使用 AlphaDropout。
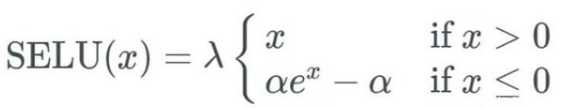
它相对于ELU做了一个新的变化:就是现在把每一个值的前面都乘上一个,然后他告诉你说
跟
应该设多少,这是作者推导出来的,很麻烦的推导,详情也可以看作者的github:https://github.com/bioinf-jku/SNNs,
它是一个非常神奇的激活函数,他把sigmoid乘上得到她的output:
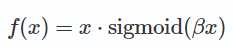
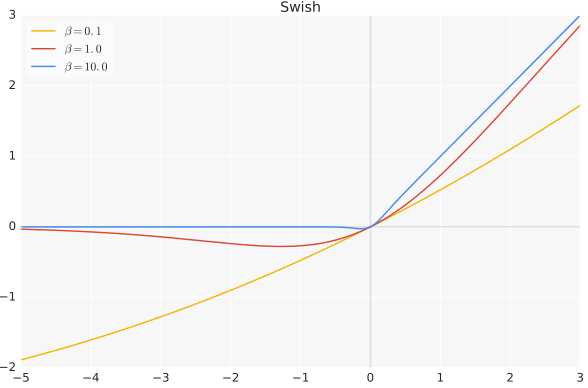
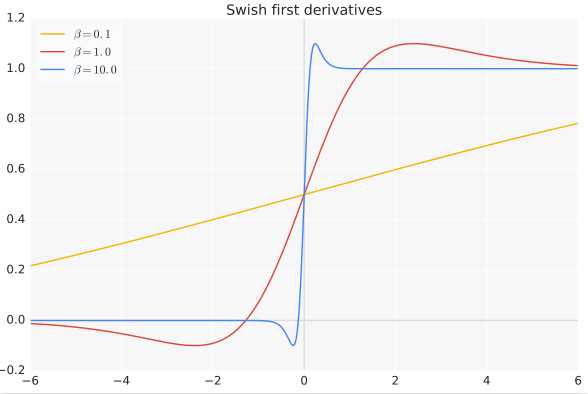
β是个常数或可训练的参数.Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。例如,仅仅使用 Swish 单元替换 ReLU 就能把 Mobile NASNetA 在 ImageNet 上的 top-1 分类准确率提高 0.9%,Inception-ResNet-v 的分类准确率提高 0.6%。
当β = 0时,Swish变为线性函数f(x)=x/2
β → ∞, σ(x)=(1+exp(−x))−1。 为0或1. Swish变为ReLU: f(x)=2max(0,x)。Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
(1)通常来说,不能把各种激活函数串起来在一个网络中使用。
(2)首先尝试ReLU,速度快。如果使用ReLU,那么一定要小心设置学习率(learning rate),并且要注意不要让网络中出现很多死亡神经元。如果死亡神经元过多的问题不好解决,可以试试Leaky ReLU、PReLU、或者Maxout。
(3)尽量不要使用sigmoid激活函数,可以试试tanh,不过我还是感觉tanh的效果会比不上ReLU和Maxout,sigmoid/tanh在RNN(LSTM、注意力机制等)结构中有所应用,作为门控或者概率值;
标签:分析 image 其他 line rar nis 线性变换 width margin
原文地址:https://www.cnblogs.com/super-zheng/p/13292531.html