标签:ali png 回顾 red preview ice HERE versions war
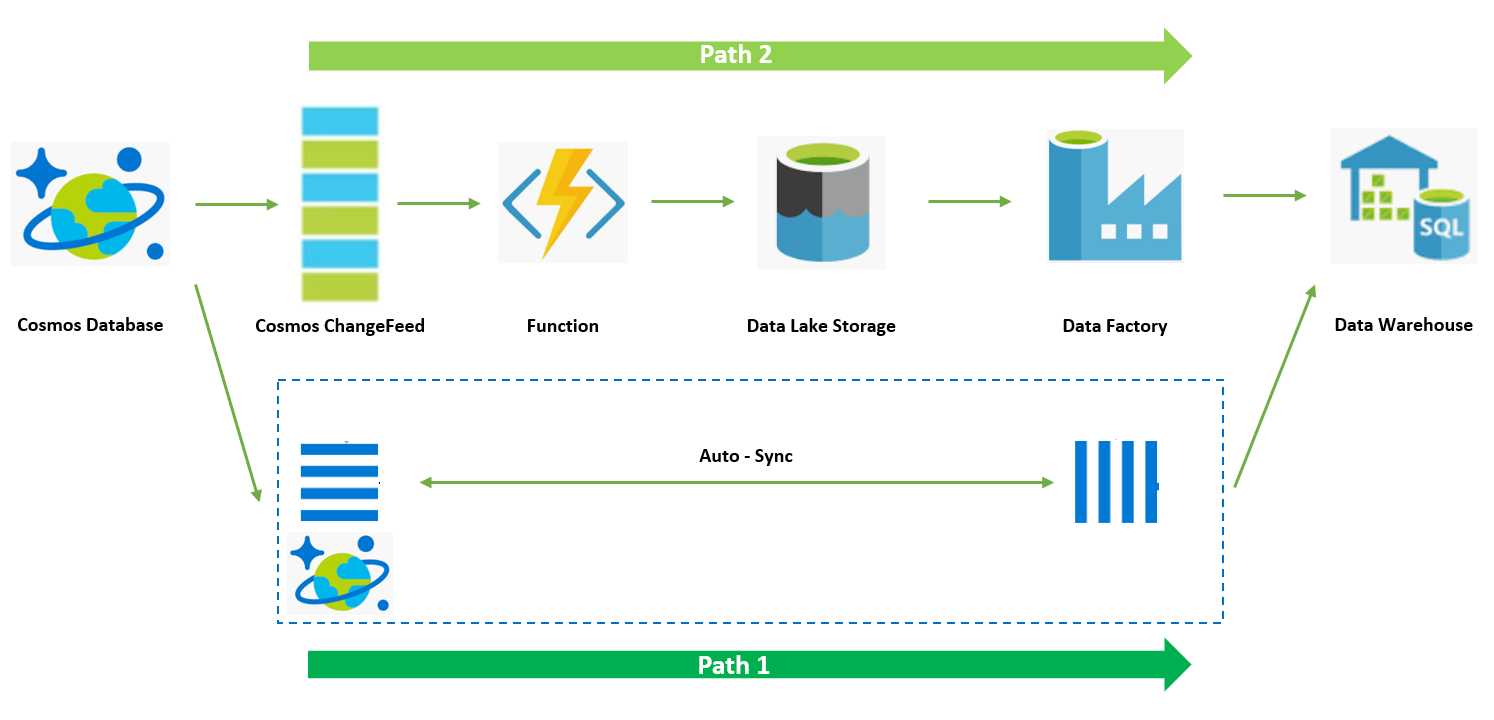
上一篇我们介绍到通过 Date Warehouse T-SQL Script 来实现 CDC 数据的 ETL 和 Update,本篇 Blog 带大家通过 Data Factory 工具将该数据处理水线实现自动话,大体思路是将前面的 Data Warehouse ETL 和 Update 通过存储过程在 DW 中函数化,然后通过在 Data Factory 中创建数据水线来调起存储过程,整个水线的触发可以通过 Data Lake 中新的的 CDC 数据产生作为事件触发条件。
下面开始进行操作:
1. 创建存储过程,将上一篇中 ELT 和 Update T-SQL 脚本通过存储过程进行实现;
CREATE PROCEDURE CdcdemoUpsert AS BEGIN CREATE TABLE dbo.[demotable_upsert] WITH ( DISTRIBUTION = HASH(ID) , CLUSTERED COLUMNSTORE INDEX ) AS -- New rows and new versions of rows SELECT s.[ID] , s.[PRICE] , s.[QUANTITY] FROM dbo.[stg_demotable] AS s UNION ALL -- Keep rows that are not being touched SELECT p.[ID] , p.[PRICE] , p.[QUANTITY] FROM dbo.[demotable] AS p WHERE NOT EXISTS ( SELECT * FROM [dbo].[stg_demotable] s WHERE s.[ID] = p.[ID] ); RENAME OBJECT dbo.[demotable] TO [demotable_old]; RENAME OBJECT dbo.[demotable_upsert] TO [demotable]; DROP TABLE [dbo].[demotable_old]; DROP TABLE [dbo].[stg_demotable]; END ;
2. 创建 Data Factory Pipeline,先通过 Copy Activity 将 Data Lake 中的 CDC 数据拷贝至 Data Warehouse 中的 Staging Table,再通过调用存储过程实现对 DW 中生产表格的 Update 操作,此步骤可以将下面的 Data Factory Pipeline Json 描述文件导入到 Data Factory 中并按照自己环境中的 SQL Pool 和 Data Lake 连接参数进行修改

{
"name": "CDC_Pipeline",
"properties": {
"activities": [
{
"name": "Copy_CDC_Data",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "SqlDWSink",
"preCopyScript": "IF OBJECT_ID(‘[dbo].[stg_demotable]‘) IS NOT NULL\nBEGIN\n DROP TABLE [dbo].[stg_demotable]\nEND;\nCREATE TABLE [dbo].[stg_demotable]\n(\n [ID] VARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,\n [PRICE] INT NOT NULL,\n [QUANTITY] INT NOT NULL\n)\nWITH\n(\n DISTRIBUTION = ROUND_ROBIN,\n CLUSTERED COLUMNSTORE INDEX\n);",
"allowCopyCommand": true,
"disableMetricsCollection": false
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": {
"name": "id",
"type": "Int16"
},
"sink": {
"name": "ID",
"type": "String"
}
},
{
"source": {
"name": "price",
"type": "Int16"
},
"sink": {
"name": "PRICE",
"type": "Int32"
}
},
{
"source": {
"name": "quantity",
"type": "String"
},
"sink": {
"name": "QUANTITY",
"type": "Int32"
}
}
]
}
},
"inputs": [
{
"referenceName": "CDC_Data",
"type": "DatasetReference",
"parameters": {
"DataSetFileName": {
"value": "@pipeline().parameters.CDCFileName",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "AzureSynapseAnalyticsTable1",
"type": "DatasetReference"
}
]
},
{
"name": "CDC_Upsert_StoredProcedure",
"type": "SqlPoolStoredProcedure",
"dependsOn": [
{
"activity": "Copy_CDC_Data",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"sqlPool": {
"referenceName": "cdcdemo",
"type": "SqlPoolReference"
},
"typeProperties": {
"storedProcedureName": "[dbo].[CdcdemoUpsert]"
}
}
],
"parameters": {
"CDCFileName": {
"type": "string"
}
},
"annotations": []
},
"type": "Microsoft.Synapse/workspaces/pipelines"
}
3. 创建 Data Factory Pipeline 触发条件,定义 Data Lake CDC 文件创建作为触发条件,其中 blobPathBeginWith 参数和 scope 参数替换为相应 Data Lake 存储参数值。
{
"name": "CDCDemoTrigger",
"properties": {
"annotations": [],
"runtimeState": "Stopped",
"pipelines": [
{
"pipelineReference": {
"referenceName": "CDC_Pipeline",
"type": "PipelineReference"
},
"parameters": {
"CDCFileName": "@trigger().outputs.body.fileName"
}
}
],
"type": "BlobEventsTrigger",
"typeProperties": {
"blobPathBeginsWith": "<datalakecdcfilepath>",
"blobPathEndsWith": ".csv",
"ignoreEmptyBlobs": true,
"scope": "<datalakestorageaccountresourceid>",
"events": [
"Microsoft.Storage.BlobCreated"
]
}
}
}
4. 通过在 Cosmos 中仿真数据变更操作,查看整个 Pipeline 工作日志
通过上述配置我们实现了通过 Data Factory 数据水线工具自动化完成 CDC 由数据湖导入 Data Warehouse 并更新 Data Warehouse 数据表格的工作。目前 Azure Synapse Analysis 处于 Preview 阶段,所以在内置的 Data Factory 中还不支持通过 Managed Identity 连接 SQL Pool, 且不支持 Blob Event Trigger Pipleline。Managed Identity 问题大家可以使用 ServicePrinciple 作为 Workaround, Blob Event Trigger 会在七月底支持,测试过程中大家可以通过手动触发的方式或者使用非 Synapse Analysis 内置 Data Factory 来实现相同逻辑。到此为止整个 Cosmos DB ChangeFeed 数据完整的处理流程已经完毕,大家回顾一下整个过程还是需要花些功夫才可以打通整个流程。下一篇 Blog 也是这个系列的最后一篇,将为大家介绍直通模式 Synapse Link 实现 Cosmos DB 一跳对接 Data Warehouse 的方案。
Azure Synapse Analysis 开箱 Blog - 伍 -- Data Factory Data Pipeline Automation
标签:ali png 回顾 red preview ice HERE versions war
原文地址:https://www.cnblogs.com/wekang/p/13282417.html