标签:mic enum send super _id rac forward ide layer

import torch
in_channels, out_channels = 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size, in_channels, width, height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
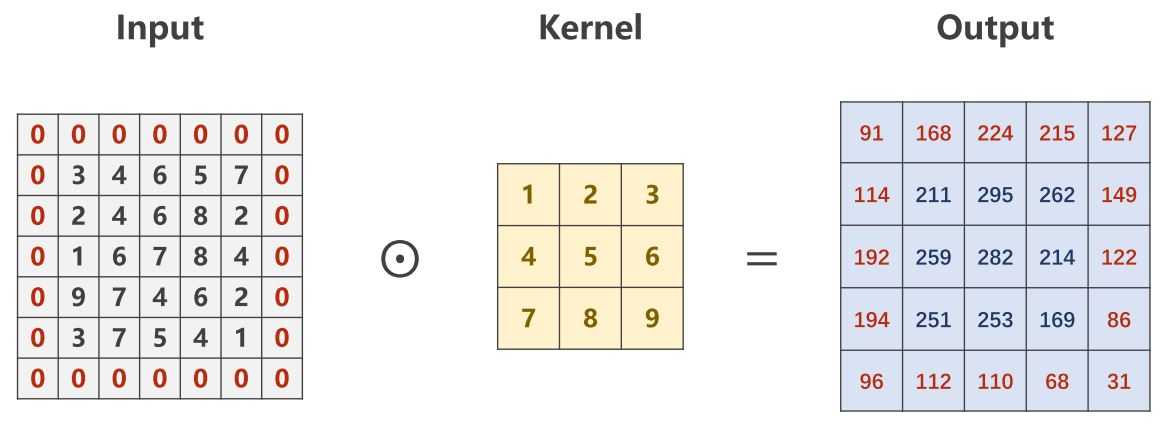
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
import torch
input = [3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6,]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling_layer(input)
print(output)
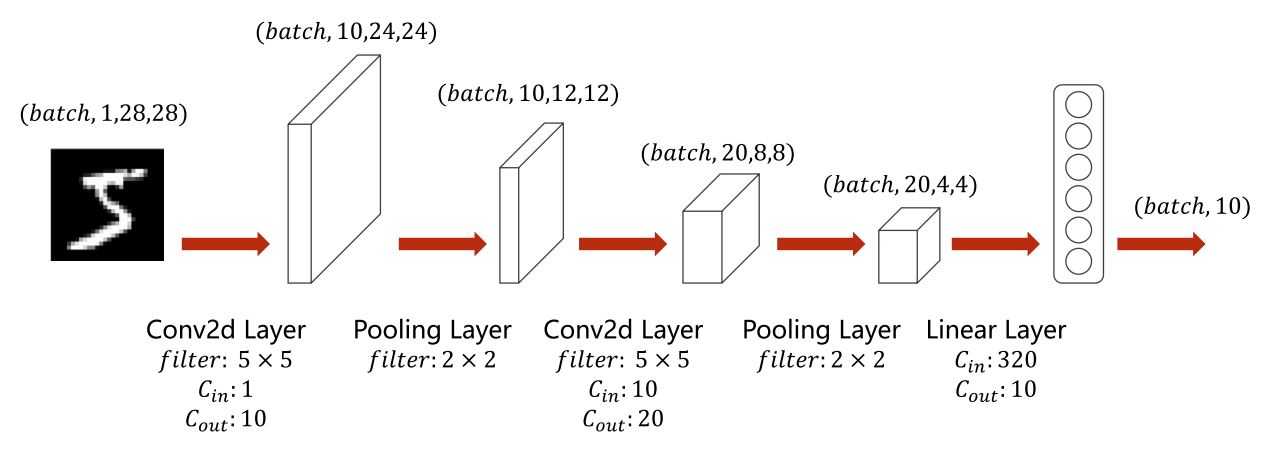
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # Convert parameters and buffers of all modules to CUDA Tensor.
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device) # Send the inputs and targets at every step to the GPU.
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward() optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print(‘[%d, %5d] loss: %.3f‘ % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device) # Send the inputs and targets at every step to the GPU.
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(‘Accuracy on test set: %d %% [%d/%d]‘ % (100 * correct / total, correct, total))
标签:mic enum send super _id rac forward ide layer
原文地址:https://www.cnblogs.com/wang-haoran/p/13298449.html