标签:pool put 区域 变化 流程 不能 follow splay form
之前的项目中使用了可形变卷积,感觉有效果,所以就具体看一下。
论文: http://openaccess.thecvf.com/content_ICCV_2017/papers/Dai_Deformable_Convolutional_Networks_ICCV_2017_paper.pdf
代码: https://github.com/msracver/Deformable-ConvNets
传统的卷积由于规则形状固定,不能完全适应目标的形状,我们期望的应该是一种自适应卷积,或者说可形变(Deformable Convolution )卷积,就像这样:
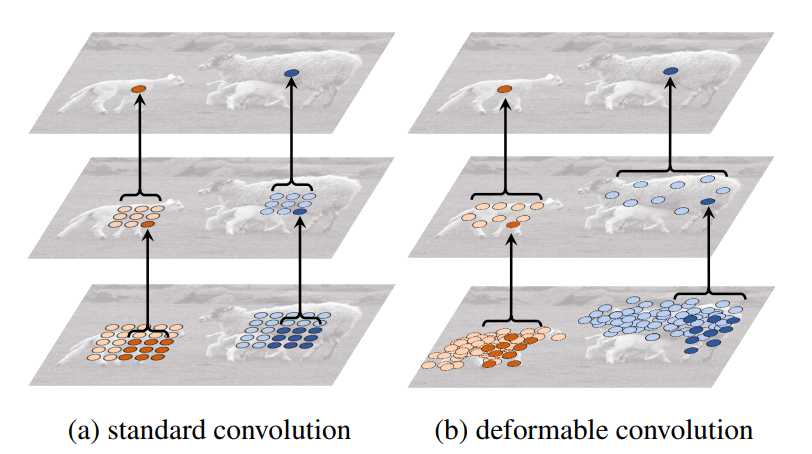
首先看顶层的feature map,我们取两个激活点(分别在大羊和小羊身上),代表的是不同尺度和形状。中间层:top层的feature map经过3*3的卷积后,需要抽样的一些点。最底层:再经过一个3*3的卷积,需要采样的点。通过对比可以明显的看出,可变形卷积的采样位置更符合物体本身的形状和尺寸,而标准卷积的形式却不能做到这一点。能够明显的看到最终的激活点学习了他该学习的特征,这个特征只针对于物体本身,相比原始的卷积它更能排除背景噪声的干扰。
对卷积核中每个采样点的位置都增加了一个偏移变量,可以实现在当前位置附近随意采样而不局限于之前的规则格点。如下图所示,是常见的采样点和可变形卷积采样的对比:
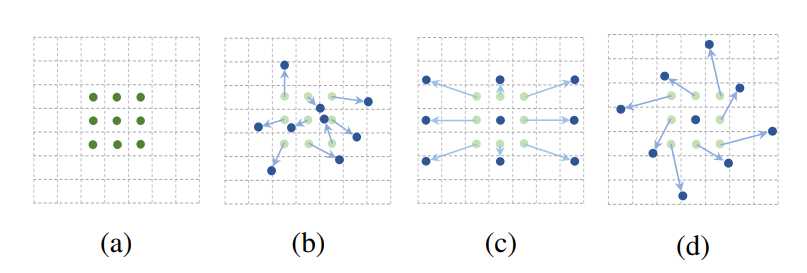
(a)是常见的3x3卷积核的采样方式,(b)是采样可变形卷积,加上偏移量之后的采样点的变化,其中(c)(d)是可变形卷积的特殊形式
可形变卷积是基于一个平行网络学习offset(偏移),使得卷积核在input feature map的采样点发生偏移,集中于我们感兴趣的区域或者目标。
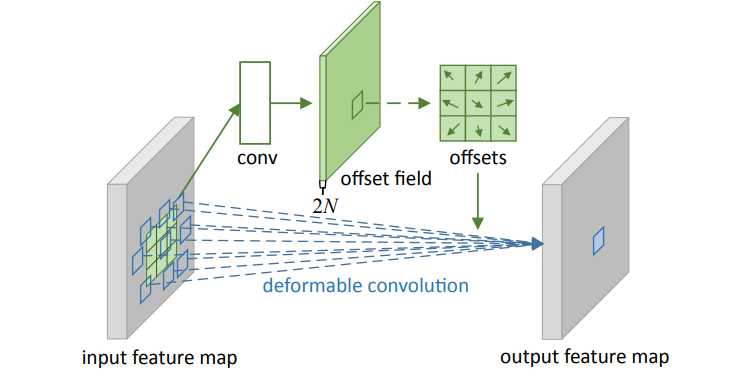
他的具体流程是:

所以可形变卷积这种形变不是发生在卷积核,而是发生在原图产生了offset偏移,在经过正常卷积就达到可变卷积的效果,也就是特征偏移+正常卷积。
相对应可形变卷积还有可形变的roi pooling:
之前我们faster rcnn介绍的roi pooling是通过spp完成的:
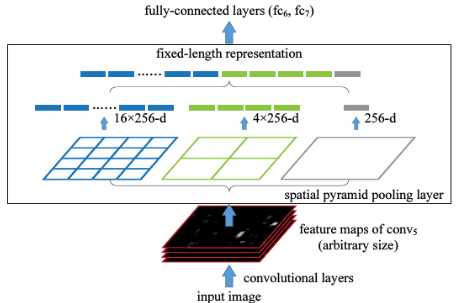
这种就是把一张图分成若干个cell,这种也是规则和形状很固定,所以有了以下的可形变的roi pooling:
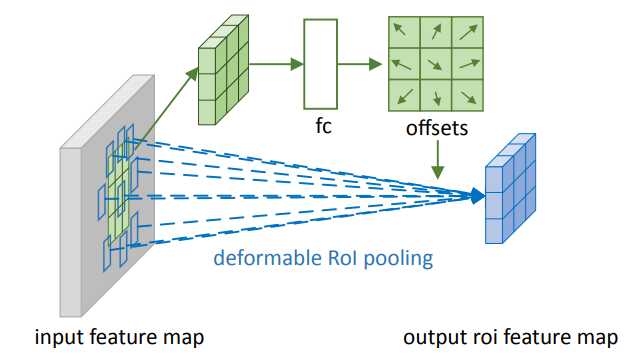
相比普通ROI Pooling,同样增加了一个offset,下图为网络结构:具体操作为,首先,通过普通的ROI Pooling得到一个feature map,如上图中的绿色块,通过得到的这个feature map,加上一个全连接层,生成每一个位置的offset,然后处理方式和可形变卷积一样,为了让offset的数据和ROI 的尺寸匹配,需要对offset进行微调,此处不是重点。全连接层的参数可以通过反向传播进行学习。
代码学习:
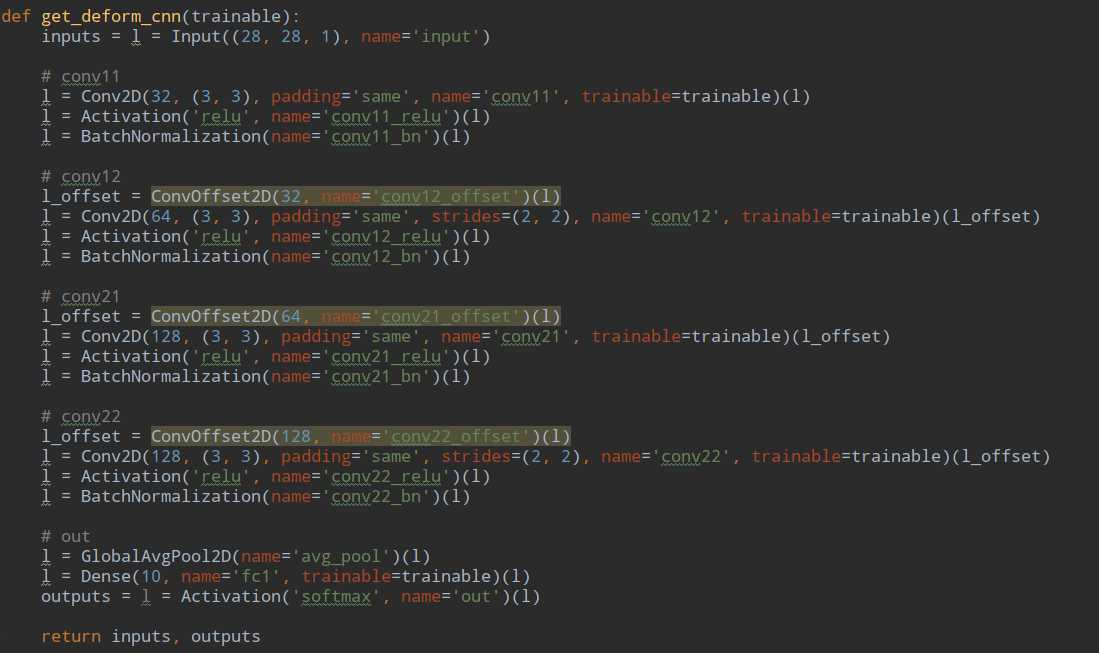
在CNN中就是这样用的,l_offset表示发生位移后的新的图像,然后用它来进行新的卷积,这个ConvOffset2D是这样定义的:
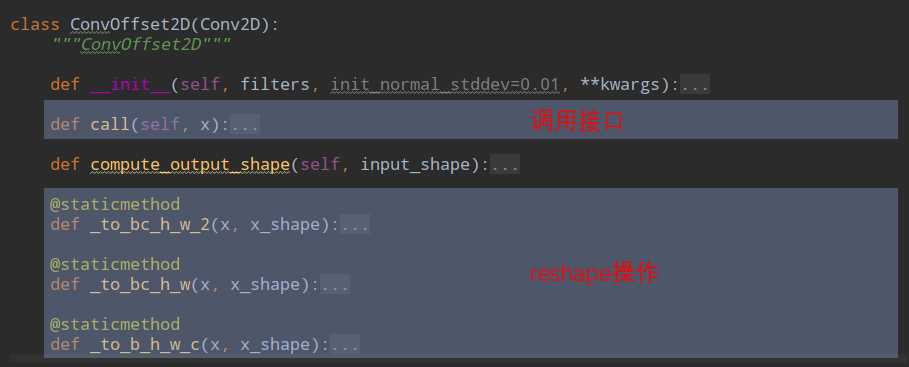

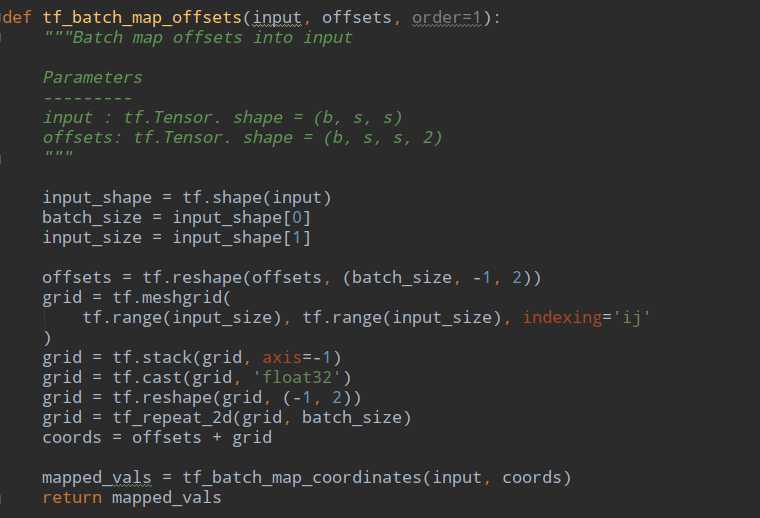
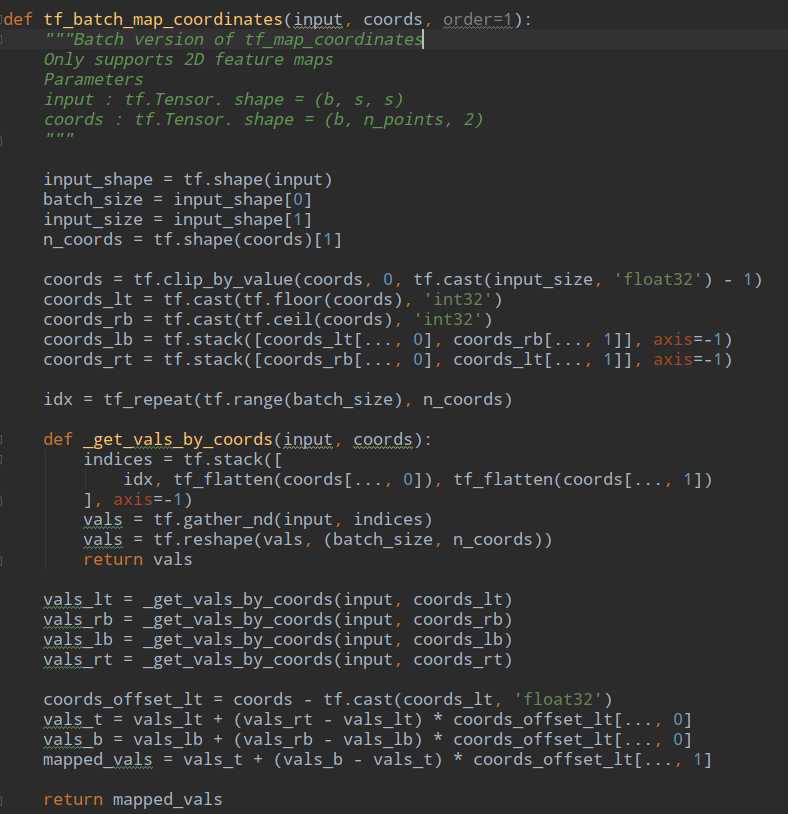
x_offset就是输入x在offsets的偏移上得到的新的图,这个计算发生在:
标签:pool put 区域 变化 流程 不能 follow splay form
原文地址:https://www.cnblogs.com/super-zheng/p/13299590.html