标签:性能提升 获得 融合 转换 red cpu love -o vgg
深度学习发展至今,依据产生了许多优秀的技术。其中一些技术对特定的数据集或小数据集有着良好的表现;而有一些技术拥有着普遍的适用性,在各个领域、各种架构都有着非常好的性能提升表现,如: batch-normalization, residual-connections。yolo的作者列举了如下的技术(主要是本文使用的):
WRC (Weighted-Residual-Connections) 加权残差连接
CSP (Cross-Stage-Partial-connections)跨阶段部分连接
CmBN (Cross mini-Batch Normalization)交叉小批量标准化
SAT(Self-adversarial-training)自我对抗训练
Mish-activation Mish激活-----> 即将取代Relu激活的存在: https://www.cnblogs.com/think90/p/11857224.html
介绍见附件 Mish激活函数介绍
Mosaic data augmentation 马赛克式数据增强:将几张图片拼接到一起!
DropBlock Regularization 删除块的正则化
介绍见附件 DropBlock正则化介绍
CIoU Loss 正则化函数介绍链接: https://zhuanlan.zhihu.com/p/104236411
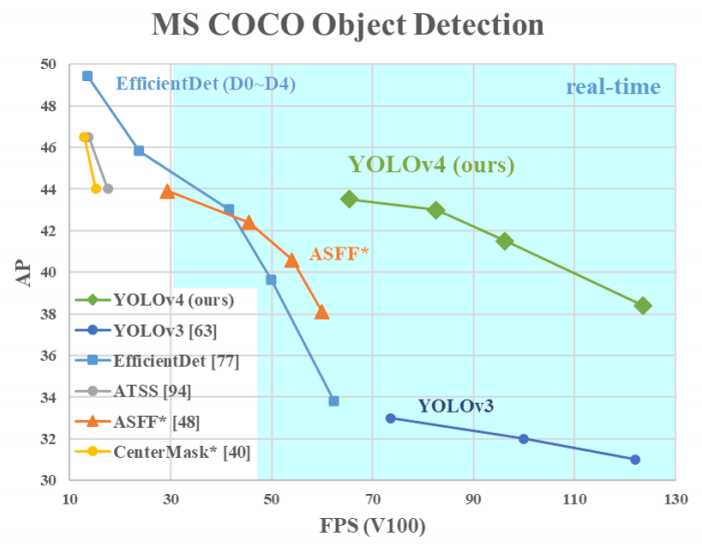
yolov4在一些任务上达到了SOTA状态!在MS COCO数据集上实现了43.5%的\(AP\),65.7的\(AP_{50}\),实时性达到了65帧。代码开源在:https://github.com/AlexeyAB/darknet
当前基于CNN的网络架构主要用于辅助决策(推荐系统),当我们需要实时地决策时,一般网络就不能很好地兼容我们的系统开发了,因为这些网络一般非常庞大(追求模型的性能精度而损失实时性)。作者提出的yolo系列正是考虑了实时性的优秀架构,随着版本的更替,yolo系列模型的精度也在不断提升!而很多公司也正是因为有了yolo系列,视觉检测任务才能够进行(毫不夸张地说)。
yolo-v4可能是原作者的最后一次更新(广大的粉丝当然希望大神不要就此诀别这个领域),它为我们带来了高精度的实时性架构。你只需要一张传统的GPU(如:2080TI)就开源训练属于你自己的模型。
本文中作者的主要工作是提升目标检测器的速度与计算的优化,而不是降低计算量理论指标(BFLOP)!
这篇论文的主要贡献为:
开发了一个高效和强大的目标检测模型。它使每个人都可以使用1080ti或2080tiGPU训练一个超快速和准确的目标探测器。
在目标检测训练过程中,作者验证了Bag-of-Freebies与Bag-of-Specials方法在模型中的影响。
Bag-of-Freebies and Bag-of-Specials方法介绍见附件。
方法提出者在yolo-v3上验证此方法在不改变模型建构和损失函数的情况下将性能提升了5个百分点。
————————————————
(1)Bag-of- Freebies
传统的目标探测器是离线训练的,因此,研究者希望利用这一优势,开发出更好的训练方法,使目标检测器在不增加推理成本的情况下获得更好的精度。把这些只改变训练策略或只增加训练成本的方法称为“免费包”。
输入图像可变性,遮挡,多张图数据增强,样式转换(GAN),数据分布不平衡, 不同类别的关联, BBox回归
(2)Bag of specials
对于那些只增加少量推理代价却能显著提高目标检测精度的插件模块和后处理方法,我们称之为“特殊包”。
扩大感受野,注意力机制,特征融合,激励函数,后处理模块(NMS)
————————————————
原文链接:https://blog.csdn.net/xiaoshulinlove/article/details/105760976
修改了一些SOTA方法,使之能够更高效、更适合单张GPU训练,包括CBN、PAN、SAM等。
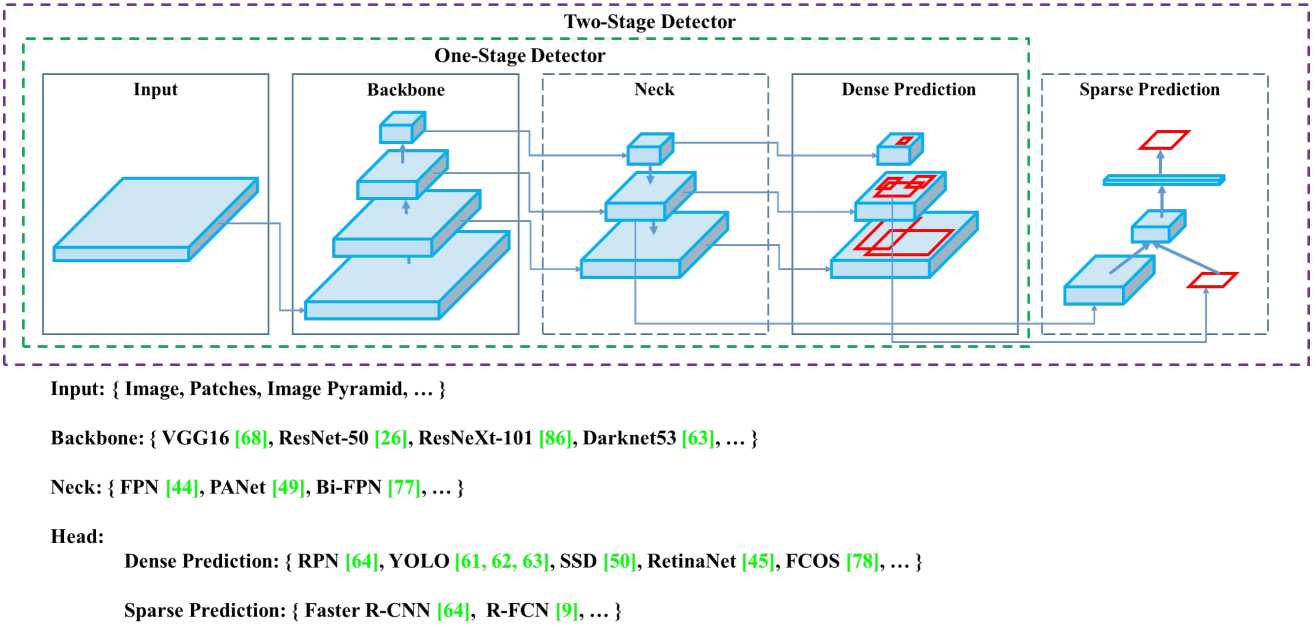
上面的示意图可以清楚地了解整个架构的组成(前提是你得有基本的视觉理论基础)。
最后YOLO v4 作者选择的架构:
YOLO v4 uses:
目前,目标检测比较流行两部分组合的网络架构,即backbone + head。一般情况下,我们需要一个backbone结构,也即我们的骨干网络,预测分类和目标边框回归(在GPU上面燥的情况):常见的有VGG、ResNet、ResNeXt、DenseNet;检测目标在CPU上,常见的有SqueezeNet、MobileNet、ShufflfleNet。head部分一般分为两部分: one-stage object detector and two-stage object detector。 two-stage object detector的代表是R-CNN系列:fast R-CNN、 faster R-CNN 、R-FCN、Libra R-CNN;也可以是基于 anchor-free 的目标检测算法如RepPoints。 one-stage object detector的代表有:yolo系列、SSD、RetinaNet。最近 anchor-free one-stage的目标检测发展迅速,有CenterNet、CornerNet、FCOS等。
最近一段时间的研究,学者经常在backbone和head中加入一些layer,主要是连接不同的stages。这些添加的layer,yolo-v4作者们称之为neck层。这些neck层一般是采用了自上而下的路径与自下而上的路径的组合,需要这种结构的架构如:FPN、Path Aggregation Network (PAN) 、 BiFPN、NAS-FPN。
除了上述的架构外,一些学者将工作重心放到了研究新的backbone(DetNet、DetNAS)或新的全模型(SpineNet、HitDetector)上。
综上,一个物体检测可以由以下几部分组成:
Input: Image, Patches, Image Pyramid(原始图像数据,裁剪后的图像数据、图像金字塔)
Backbones:VGG16, ResNet-50, SpineNet, EffificientNet-B0/B7, CSPResNeXt50 , CSPDarknet53
Neck:
Heads:
Dense Prediction (one-stage)
RPN、SSD、YOLO、RetinaNet[anchor based];
CornerNet、CenterNet、MatrixNet、FCOS[anchor free]。
Sparse Prediction (two-stage)
Faster R-CNN , R-FCN , Mask R-CNN (anchor based)
RepPoints (anchor free)
一般传统的目标检测模型是在线下训练的,而研究者可以基于这些成果进一步提升模型的精度而没有增加推理的成本。我们将只改变训练策略或只在模型上进行inference的方法称之为:bag of freebies(BOF)--免费包方法。BOF方法典型的就是数据增强(提高样本在不同环境中的模型稳定性), photometric distortions 光学扭曲:改变图片的亮度、饱和度、对比度、色调等;geometric distortions 几何扭曲:旋转、翻转、裁剪、缩放等几何操作。这些数据增强的方法在目标检测中是非常有用的。
数据增强
上面的数据增强方法主要是对像素级的操作,全局的像素信息没有大的变化。一些研究者提出了一些新颖的方法改变全局特征,从而提升模型性能。如 random erase随机搽除、CutOut随机拿一个矩形区域进行零(或其他值)填充;相同的概率被应用到特征图,如DropOut、DropConnect、DropBlock。还有一些研究人员将多幅图像进行区域加权融合。MixUp将两个图像进行叠加,根据比率来调整label;CutMix将裁剪后的图像覆盖到其他图像的矩形区域,并根据混合区域的大小调整标签。 style transfer GAN风格变换也常用于数据增强,它可以有效改善CNN网络对纹理的学习偏差。
数据不平衡
我们的原始数据很多时候是不平衡的,在 two-stage目标检测中经常对负样本采样获取足够的样本量,但是这种方法对one-stage目标检测并不友好,因为检测是属于稠密型预测架构。所以有学者提出了focal loss(焦点损失),用于处理这些问题。另一个严重的问题是我们很难用单一的一个度来衡量数据不同类别直接的关系,如我们常用的label真的可以较好地区分数据本身吗?为了解决这个问题,有学者提出了 label smoothing(标签平滑)技术。即将硬标签替换为软标签。为了获得更好的软标签,Islam等人引入了知识蒸馏的概念进行设计标签优化网络。
BBox回归的目标函数
常用的损失函数是MSE(对象为框的中心坐标,高和宽--BBox),关于这里会出现的问题见附件CIoU Loss介绍,里面有详细的解释。最后我们目前较好的损失为CIoU Loss。
对于那些插件模型和后处理方法,只需要一点点inference成本就可以大幅提升模型精度的方法,我们称之为bag of specials(BOS)----特价包方法。
可增强感受野的方法:SPP、ASPP、RFB;
SPP模型来源于 Spatial Pyramid Matching (SPM) 模型,原始的SPMs模型是将特征图分为\(d\times d\)的块,然后计算词袋特征;SPP引入该思想:在CNN中使用最大池化操作代替词袋( bag-of-word)操作。这里就可以实现特征图的向量化!!!
ASPP模型在SPP模型上对kernel采样膨胀系数k,即空洞卷积。
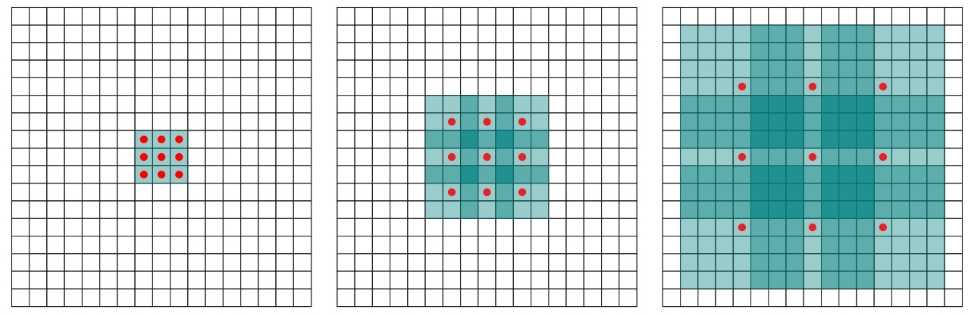
RFB 模型类似地设置了膨胀系数为k,步长为1.
……更多模型介绍参考论文
LaTeX:https://www.codecogs.com/latex/eqneditor.php
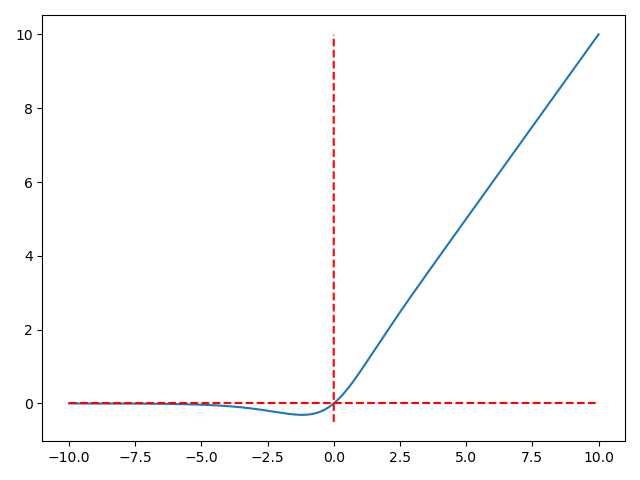
softplus函数
Mish激活函数
Mish激活简单来说就是:Mish = x * tanh(ln(1+e^(x))),即:
Mish的图像
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 500)
y = x * np.tanh(np.log(1 + np.exp(x)))
y1 = 0 * x
x2 = [0 for _ in range(-50, 1000, 1)]
y2 = [i/100 for i in range(-50, 1000, 1)]
plt.plot(x, y)
plt.plot(x, y1, c="red", linestyle=‘--‘)
plt.plot(x2, y2, c="red", linestyle=‘--‘)
plt.show()
class Mish(nn.model):
def __init__(self):
super().__init__()
print("Mish activation loaded …")
def forward(self, x):
x =x * (torch.tanh(F.softplus(x)))
return x
# softplus是ReLU的平滑版本
arxiv链接:https://arxiv.org/pdf/1810.12890.pdf
博客资源(参考):https://blog.csdn.net/qq_14845119/article/details/85103503

上图中的(a)是训练的原始图像;(b)中的浅绿色是被激活的区域,“X”标识了被dropout的区域;(c)中的dropout方式就是我们这里需要提及的DropBlock正则化。
(b)中的正则化方式,被drop掉的区域特征容易从周边区域学习得到,而(c)采用了DropBlock的方式,将较大一块区域的信息drop掉,网络就会学习对象剩余部分的特征,依据这些特征进行正确分类,提高了模型的泛化能力!
DropBlock模块主要有两个超参数:block_size、\(\gamma\)
block_size表示Block的边长,block_size=1时就是dropout技术!
\(\gamma\) 表示区域被DropBlock的概率,这个参数和dropout技术一样!
DropBlock保证drop掉的特征点与传统的dropout技术一样多,即图中的“X”一样多
这里概率的函数表达式为:
传统的dropout技术drop掉的元素一共有:
\(\left ( 1-keep\_prob \right )feat\_size^{2}\)
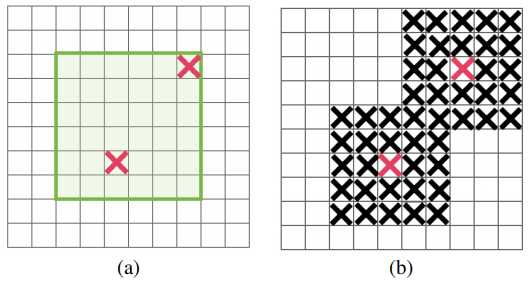
绿色区域标识了可以进行DropBlock的区域,红色的“X”表示要DropBlock的中心点,黑色的“X”表示了根据红色的“X”生成的DropBlock区域!
现在我们使用DropBlock drop掉的元素有:
上式的第二项是可能被删除的中心元素(以当前点为中心划定block)概率;第三项是每个bolck的元素个数。从期望的角度,两种算法是会drop掉相同期望值的元素个数!
上式第二项实际上划定了一个DropBlock 的区域,即边缘无法满足block_size的地方不能进行DropBlock操作;
论文中的试验结果
训练时使用block_size=7,keep_prob=0.9,测试时使用block_size=7,keep_prob=1.0,可以获得更好的效果。具体使用需要根据具体情况设定!
https://zhuanlan.zhihu.com/p/104236411
IoU损失由旷视于2016年ACM提出。
IoU即两个对象bbox的交并比(交/并)!
也有很多模型直接使用1-IoU作为IoU损失。
GIoU Loss在2019年的CVPR由斯坦福学者提出。
IoU损失的缺点
GIoU的公式
定义一个外接矩形C,它是包含预测框与真实框的下确界;
GIoU的值为:
GIoU的性质
引用链接:https://zhuanlan.zhihu.com/p/104236411
当真实框完全包含预测框时,IoU与GIoU是一样的,此时GIoU退化为IoU。作者加入框的中心点归一化距离,优化了此类问题!
好的目标框回归损失应该考虑三个重要的几何因素:重叠面积,中心点距离,长宽比。基于问题一,作者提出了DIoU Loss,相对于GIoU Loss收敛速度更快,该Loss考虑了重叠面积和中心点距离,但没有考虑到长宽比;针对问题二,作者提出了CIoU Loss,其收敛的精度更高,以上三个因素都考虑到了。
\(L_{DIoU}=1-IoU+\frac{\rho ^{2}\left ( b,b^{gt} \right )}{c^{2}}\)
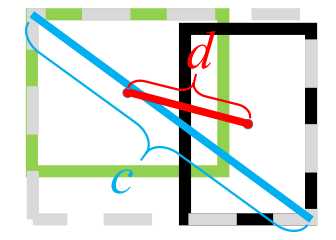
其中\(\rho\)表示欧式距离,\(b,b^{gt}\)分别表示预测框、真实框的中心,\(c\)表示GIoU 中的外接矩形C的对角线长度。
论文:https://arxiv.org/pdf/1911.08287.pdf
代码:https://github.com/Zzh-tju/DIoU-darknet
? https://github.com/Zzh-tju/CIoU
参考链接:https://blog.csdn.net/stezio/article/details/87816785
博客链接:https://blog.csdn.net/weixin_38715903/article/details/103999227
博客链接:https://blog.csdn.net/CarryLvan/article/details/104394960
yolo-v4:Optimal Speed and Accuracy of Object Detection解析
标签:性能提升 获得 融合 转换 red cpu love -o vgg
原文地址:https://www.cnblogs.com/dan-baishucaizi/p/13300363.html