标签:运算 多个 created 没有 comm nts top company block
最近FPGA需要用到大量的矩阵运算,需要使用多个shift_RAM对数据进行缓存,考虑到资源消耗问题,做相关记录。
LUTRAM 和 BRAM最主要的却别在于 LUTRAM是使用的没有综合的LUT单元生成的动态RAM,在Design中使用
多少,综合后就会消耗多少RAM。而BRAM他是块RAM,在FPGA中的位置和大小是固定的,在例化一个BRAM后,
即使只是占用到该RAM的一小部分,而综合后,同样会消耗一整块RAM的资源。
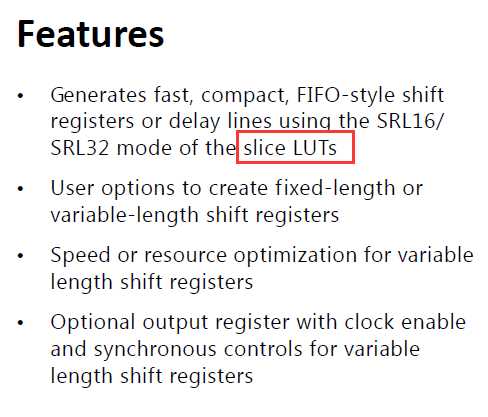
1)查看shift_ram官方手册(pg122), 消耗的为LUTs
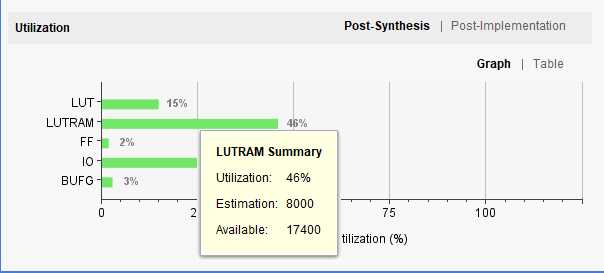
2)综合验证,为了验证,我综合了36个 数据位宽为10bit,深度为640bit的shift_RAM
`timescale 1ns / 1ps ////////////////////////////////////////////////////////////////////////////////// // Company: // Engineer: // // Create Date: 2020/07/15 10:51:34 // Design Name: // Module Name: shift_ram // Project Name: // Target Devices: // Tool Versions: // Description: // // Dependencies: // // Revision: // Revision 0.01 - File Created // Additional Comments: // ////////////////////////////////////////////////////////////////////////////////// module shift_ram( input clk , input [9:0] din , output [9:0] dout ); wire [9:0] c0; wire [9:0] c1; wire [9:0] c2; wire [9:0] c3; wire [9:0] c4; wire [9:0] c5; wire [9:0] c6; wire [9:0] c7; wire [9:0] c8; c_shift_ram_0 u0( .D (din), .CLK (clk), .Q (c0) ); c_shift_ram_0 u1( .D (c0), .CLK (clk), .Q (c1) ); c_shift_ram_0 u2( .D (c1), .CLK (clk), .Q (c2) ); c_shift_ram_0 u3( .D (c2), .CLK (clk), .Q (c3) ); c_shift_ram_0 u4( .D (c3), .CLK (clk), .Q (c4) ); c_shift_ram_0 u5( .D (c4), .CLK (clk), .Q (c5) ); c_shift_ram_0 u6( .D (c5), .CLK (clk), .Q (c6) ); c_shift_ram_0 u7( .D (c6), .CLK (clk), .Q (c7) ); c_shift_ram_0 u8( .D (c7), .CLK (clk), .Q (c8) ); c_shift_ram_0 u9( .D (c8), .CLK (clk), .Q (dout) ); endmodule
`timescale 1ns / 1ps
////////////////////////////////////////////////////////////////////////////////// // Company: // Engineer: // // Create Date: 2020/07/15 10:59:53 // Design Name: // Module Name: shift_tam_top // Project Name: // Target Devices: // Tool Versions: // Description: // // Dependencies: // // Revision: // Revision 0.01 - File Created // Additional Comments: // ////////////////////////////////////////////////////////////////////////////////// module shift_tam_top( input clk , input [39:0] din , output [39:0] dout ); wire [9:0] dout0; wire [9:0] dout1; wire [9:0] dout2; wire [9:0] dout3; assign dout = {dout0,dout1,dout2,dout3}; shift_ram u0( .clk (clk) , .din (din[9:0]) , .dout (dout0) ); shift_ram u1( .clk (clk) , .din (din[19:10]) , .dout (dout1) ); shift_ram u2( .clk (clk) , .din (din[29:20]) , .dout (dout2) ); shift_ram u3( .clk (clk) , .din (din[39:30]) , .dout (dout3) ); endmodule
最后看资源消耗综合报告:从报告中可以看出,主要消耗的还是LUTRAM资源,没有使用到BRAM的资源。
Xilinx 使用shift_RAM消耗分布式RAM(LUTRAM)还是BRAM (Block RAM)?
标签:运算 多个 created 没有 comm nts top company block
原文地址:https://www.cnblogs.com/pangshian/p/13304571.html