标签:函数 image 删除 架构 用户注册 用户 切分 64bit bit
整理自:https://mp.weixin.qq.com/s/8KTK_Bz8netP6R5MNSKeFw
搬运贴,如果有侵权请联系删除
优点:
缺点:
数据库层面的负载均衡,既要考虑数据量的均衡,又要考虑负载的均衡。
优点:
缺点:
使用uid来进行水平切分之后,对于uid属性上的查询,可以直接路由到库,对于非uid属性上的查询,就悲剧了
缺点:会增加一次数据库查询,性能会有所下降
缺点:仍然多了一次网络交互,即一次cache查询
缺点:生成uid 函数设计需要非常讲究技巧,有uid生成冲突风险,一般不采用
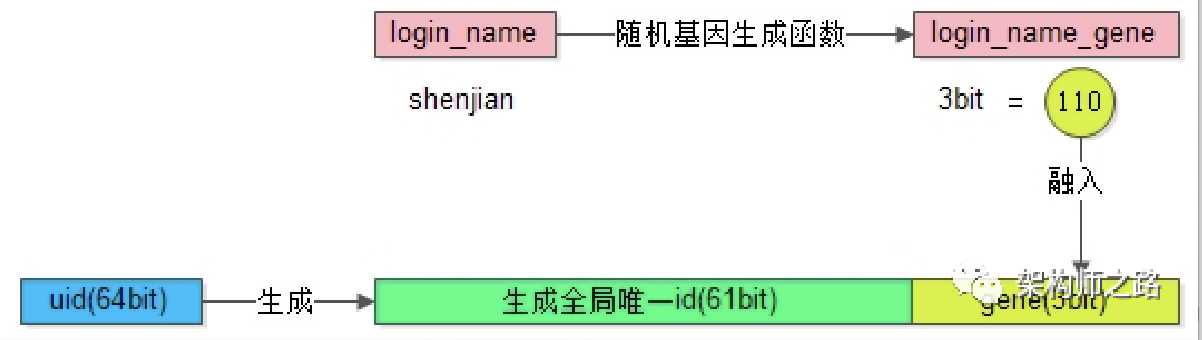
相对完美,在分库时经常使用
不需要访问实时库,通过MQ或者线下异步同步数据,使用更契合大量数据允许接受更高延时的“索引外置”或者“HIVE”的设计方案
标签:函数 image 删除 架构 用户注册 用户 切分 64bit bit
原文地址:https://www.cnblogs.com/lanse1993/p/13305183.html