标签:rabbit 多个 情况 做了 集群模式 占用 元数据 高可用 git
默认的集群模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
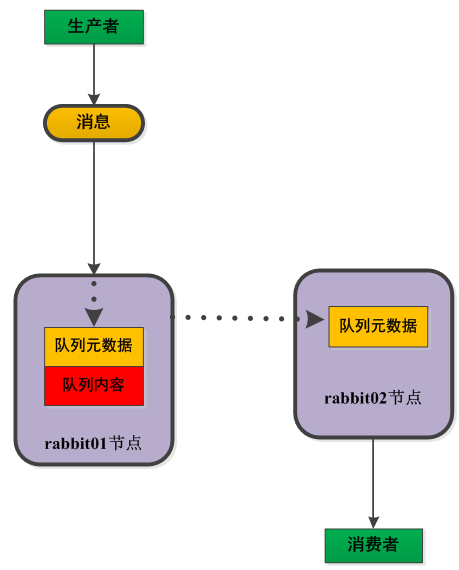
下面表示在集群配置下的不同节点创建队列的情况 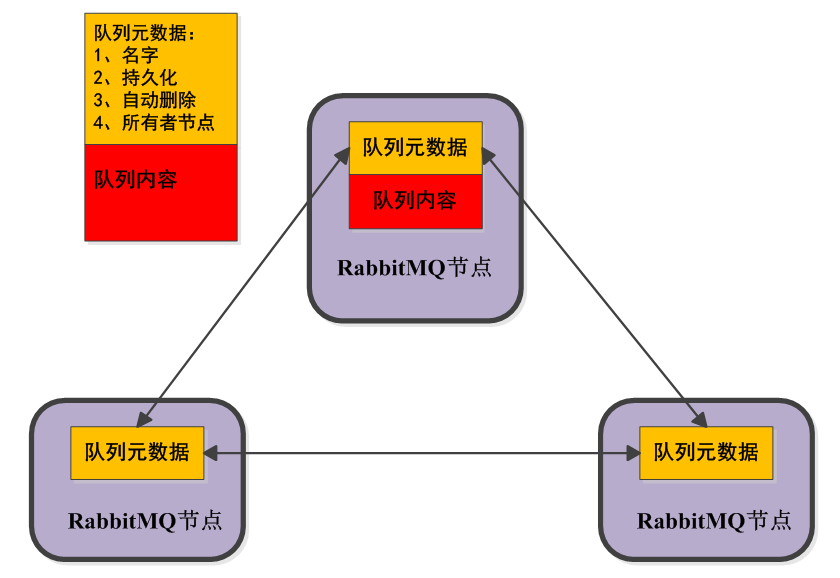
下图表示在集群配置下的不同节点创建交换器和队列的绑定的情况 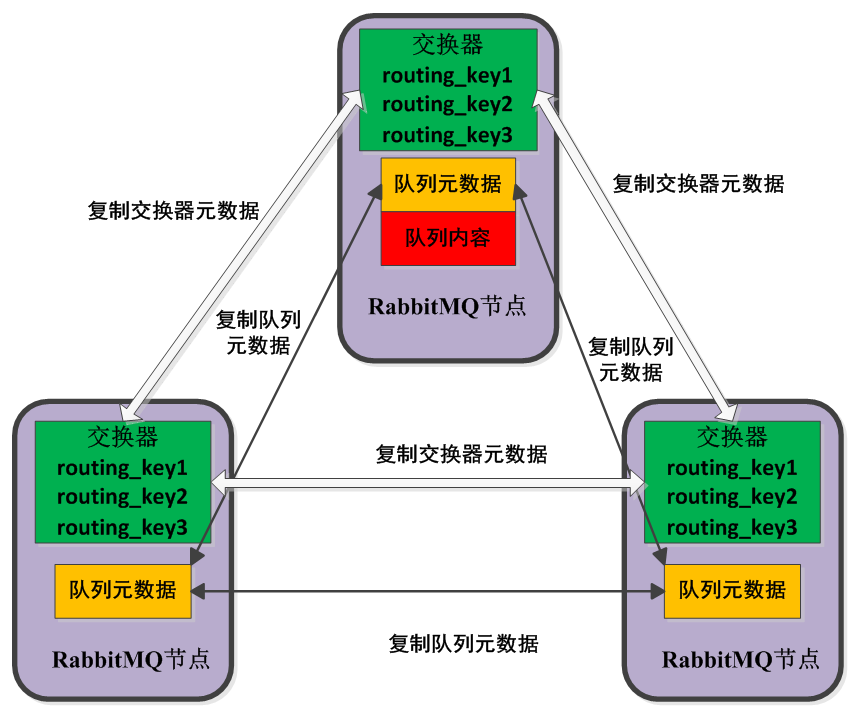
将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。 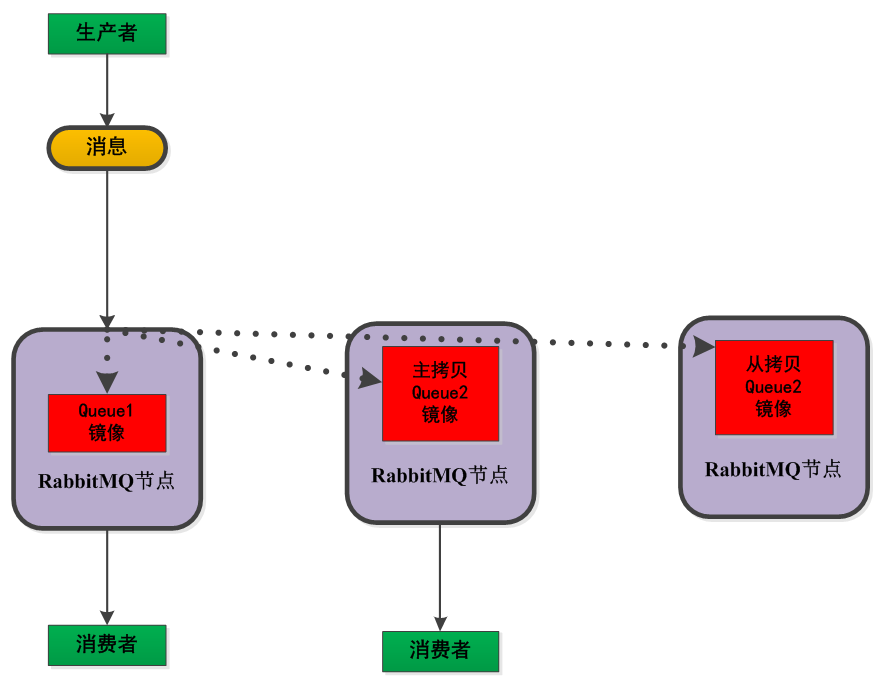
标签:rabbit 多个 情况 做了 集群模式 占用 元数据 高可用 git
原文地址:https://www.cnblogs.com/yungyu16/p/13305127.html