标签:sed 转移 目录 value 文章 源码 rac 客户 集成
我们都知道,微服务之间通过feign传递,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟超时或者错误都有可能引起整个请求最后的失败。当业务流程足够复杂时,一个完整的HTTP请求调用链一般会经过多个微服务系统,要通过日志来跟踪一整个调用链变得不再那么简单。通过sleuth可以很方便的看出每个采集请求的耗时情况,分析出哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时,可以针对业务做一些优化措施。所以我们可以通过我们可以通过Spring Cloud Sleuth来解决这个问题。这里我们将演示如何通过Spring Cloud Sleuth来追踪这个过程,并借助Zipkin以图形化界面的方式展示。 展示之前,分别介绍一下rabbitmq、sleuth、zinkip。
rabbitmq
sleuth和zinkip
sleuth中的一些术语
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)?,span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
接下来就开始搭建
这里cloud版本用的Greenwich.SR1,boot使用的是2.1.6
1.在pom.xml中 引入sleuth依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2.模拟两个日志 这两个服务之间通过feign调用,由test调用system,这里本来有一个注册中心,这里就不在演示了
test模块
@Slf4j
@RestController
public class TestController {
@Autowired
private IHelloService helloService;
@GetMapping("hello")
public String hello(String name) {
log.info("Feign调用system的/hello服务");
return this.helloService.hello(name);
}
}
在test模块的service包下创建IHelloService
@FeignClient(value = "system",contextId = "helloServiceClient")
public interface IHelloService {
@GetMapping("hello")
String hello(@RequestParam("name") String name);
}
system 模块
@Slf4j
@RestController
public class TestController {
@GetMapping("hello")
public String hello(String name) {
log.info("/hello服务被调用");
return "hello" + name;
}
}
3.访问接口 localhost:8202/test/hello?name=sleuth:会出现两个我们自定义的日志
启动的时候查看test模块产生的
2019-08-23 14:22:51.774 INFO [test,72bb0469bee07104,72bb0469bee07104,false] 22728 --- [nio-8202-exec-1] c.m.f.s.test.controller.TestController : Feign调用system的/hello服务
启动的时候查看system模块产生的
2019-08-23 14:22:52.469 INFO [system,72bb0469bee07104,43597a6edded6f2e,false] 812 --- [nio-8201-exec-2] c.m.f.s.s.controller.TestController : /hello服务被调用
可以看到,日志里出现了[Test,72bb0469bee07104,72bb0469bee07104,false]信息,这些信息由Spring Cloud Sleuth生成,用于跟踪微服务请求链路。这些信息包含了4个部分的值,它们的含义如下:
下面我们来整合Zipkin
在整合Zipkin之前,我们需要先搭建RabbitMQ。RabbitMQ用于收集Sleuth提供的追踪信息,然后Zipkin Server从RabbitMQ里获取,这样可以提升性能。
在安装RabbitMQ之前,需要先安装Erlang/OTP,下载地址为:http://www.erlang.org/downloads/,下载exe文件安装即可。
安装完毕后,下载RabbitMQ,下载地址为 :
http://www.rabbitmq.com/install-windows.html,下载exe文件安装即可。
安装完RabbitMQ之后,我们到RabbitMQ安装目录的sbin下执行如下命令
rabbitmq-plugins enable rabbitmq_management
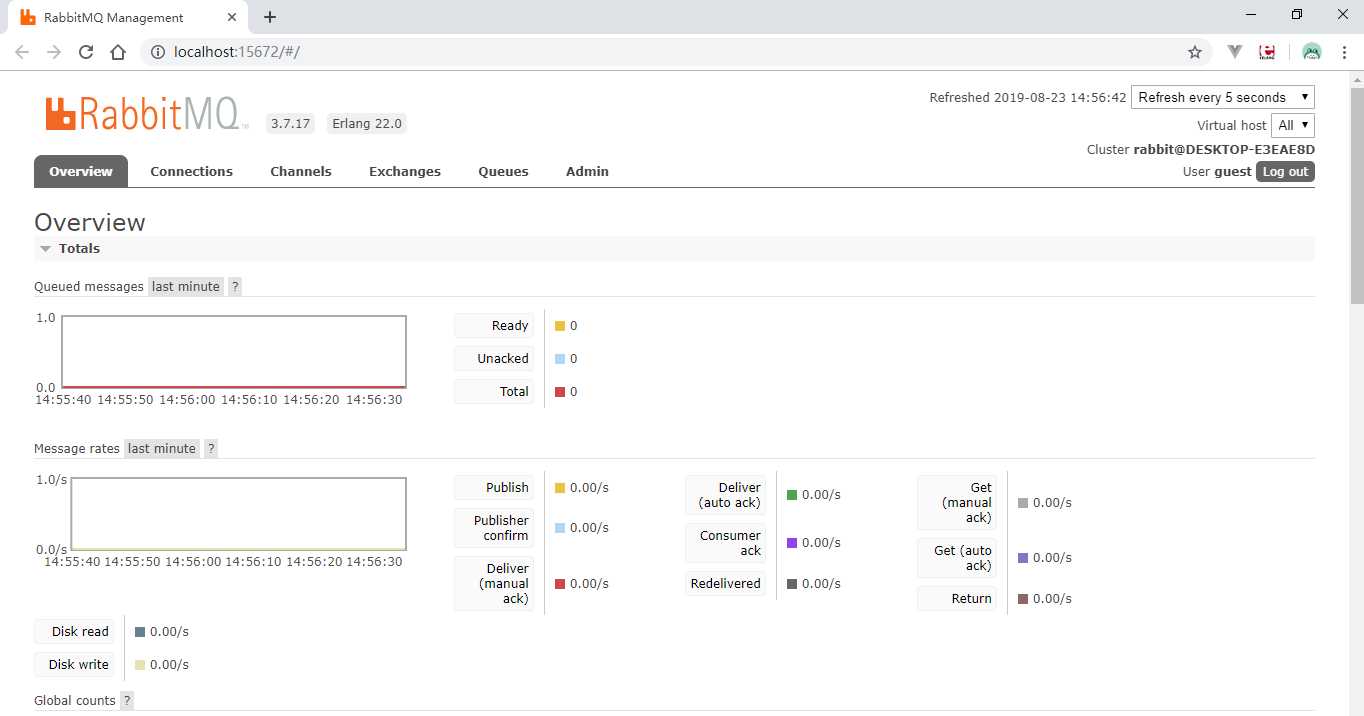
然后在浏览器中输入http://localhost:15672,默认用户名和密码都是guest,登录后可看到:
点击Admin Tab页面,新增一个用户:
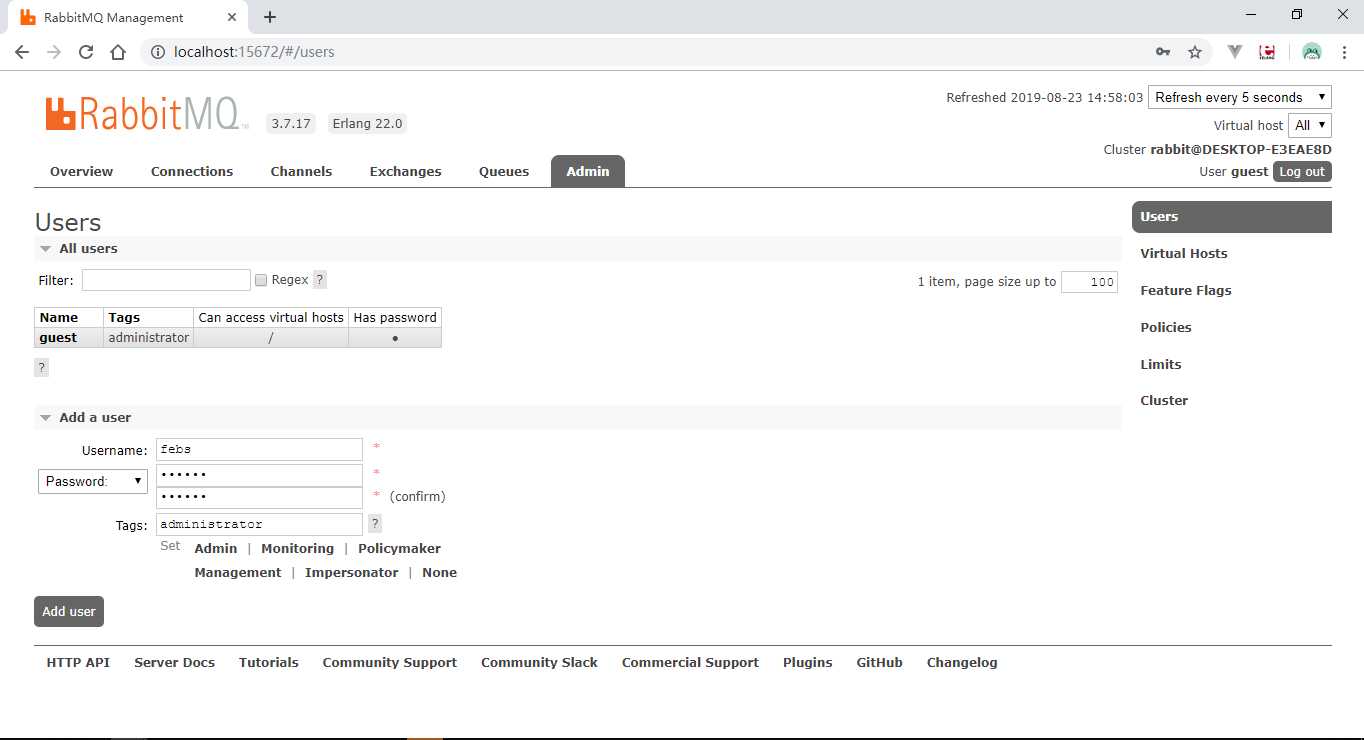
用户名为febs,密码为123456,角色为管理员。新添加的用户还是No access状态,需要进一步对该用户进行授权后,方可以远程通过该用户名访问。点击该新增用户名。进入授权页面,点击Set permission按钮,进行用户授权操作。
安装好RabbitMQ后,我们开始整合Zipkin。在较低版本的Spring Cloud中,我们可以自己搭建Zipkin Server,现在我们只能使用官方搭建好的Zipkin Server,地址为:https://github.com/openzipkin/zipkin
在cmd窗口下运行下面这条命令(windows下没有curl环境的话,可以在git bash中运行这条命令),下载zipkin.jar:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
如果下载速度极慢,可以复制链接到迅雷下载中下载,下载后重命名为zipkin.jar即可。
zipkin支持将追踪信息保存到MySQL数据库,所以在运行zipkin.jar之前,我们先准备好相关库表,SQL脚本地址为:
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql。
库表准备好后,运行下面这条命令启动zipkin.jar:
java -jar zipkin.jar --server.port=8402 --zipkin.storage.type=mysql --zipkin.storage.mysql.db=febs_cloud_base --zipkin.storage.mysql.username=root --zipkin.storage.mysql.password=123456 --zipkin.storage.mysql.host=localhost --zipkin.storage.mysql.port=3306 --zipkin.collector.rabbitmq.addresses=localhost:5672 --zipkin.collector.rabbitmq.username=febs --zipkin.collector.rabbitmq.password=123456
上面命令指定了数据库链接和RabbitMQ链接信息。更多可选配置可以解压zipkin.jar,查看zipkin\BOOT-INF\classes路径下的zipkin-server-shared.yml配置类源码。
启动好zipkin.jar后,在对应模块的pom里引入如下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
修改对应模块的application.yml
spring:
zipkin:
sender:
type: rabbit
sleuth:
sampler:
probability: 1
rabbitmq:
host: localhost
port: 5672
username: febs
password: 123456
spring.zipkin.sender.type指定了使用RabbitMQ收集追踪信息;
spring.sleuth.sampler.probability默认值为0.1,即采样率才1/10,发送10笔请求只有一笔会被采集。为了测试方便,我们可以将它设置为1,即100%采样;
spring.rabbitmq用于配置RabbitMQ连接信息,你可能会问,为什么刚刚RabbitMQ端口是15672,这里却配置为5672,是不是写错了呢?其实不是,15672是RabbitMQ的管理页面端口,5672是AMPQ端口。
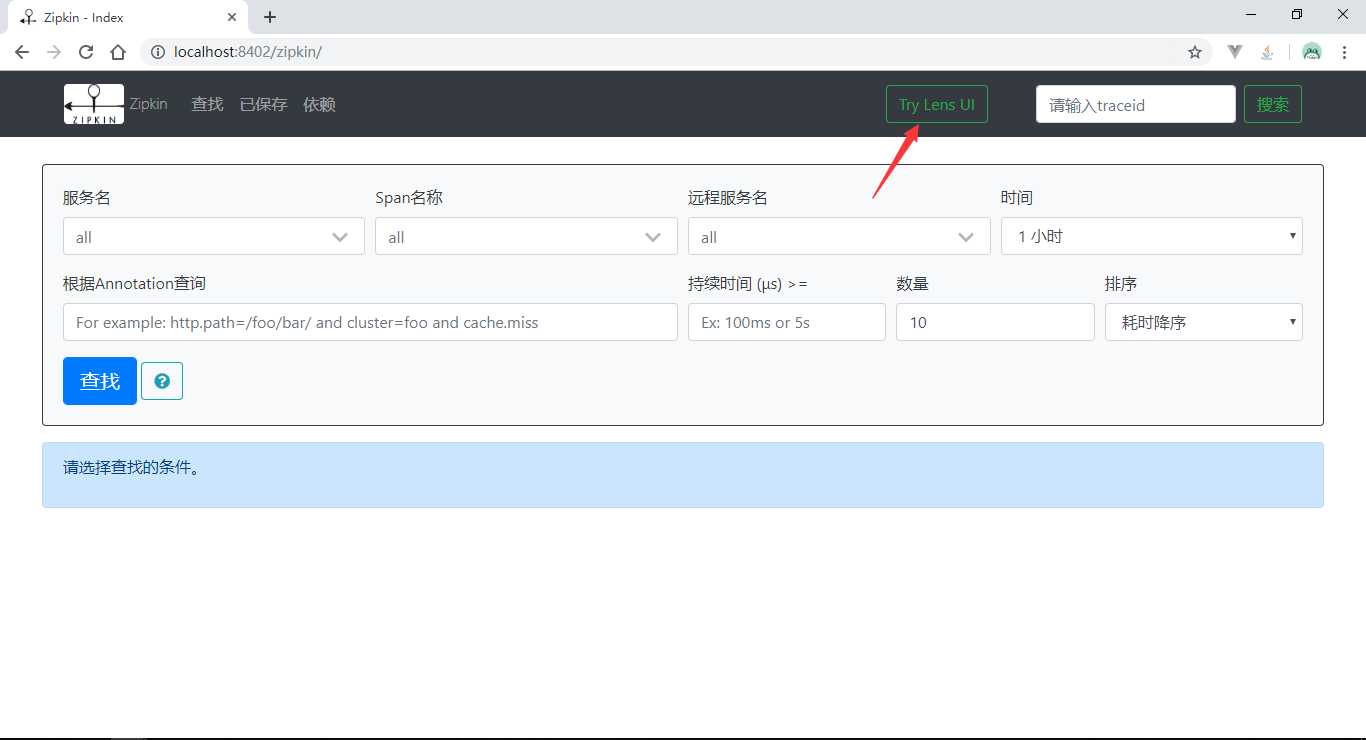
添加好配置后,启动system和test模块,发送一笔localhost:8202/test/hello?name=夏天请求后,使用浏览器访问http://localhost:8402/zipkin/链接,然后点击图中所示
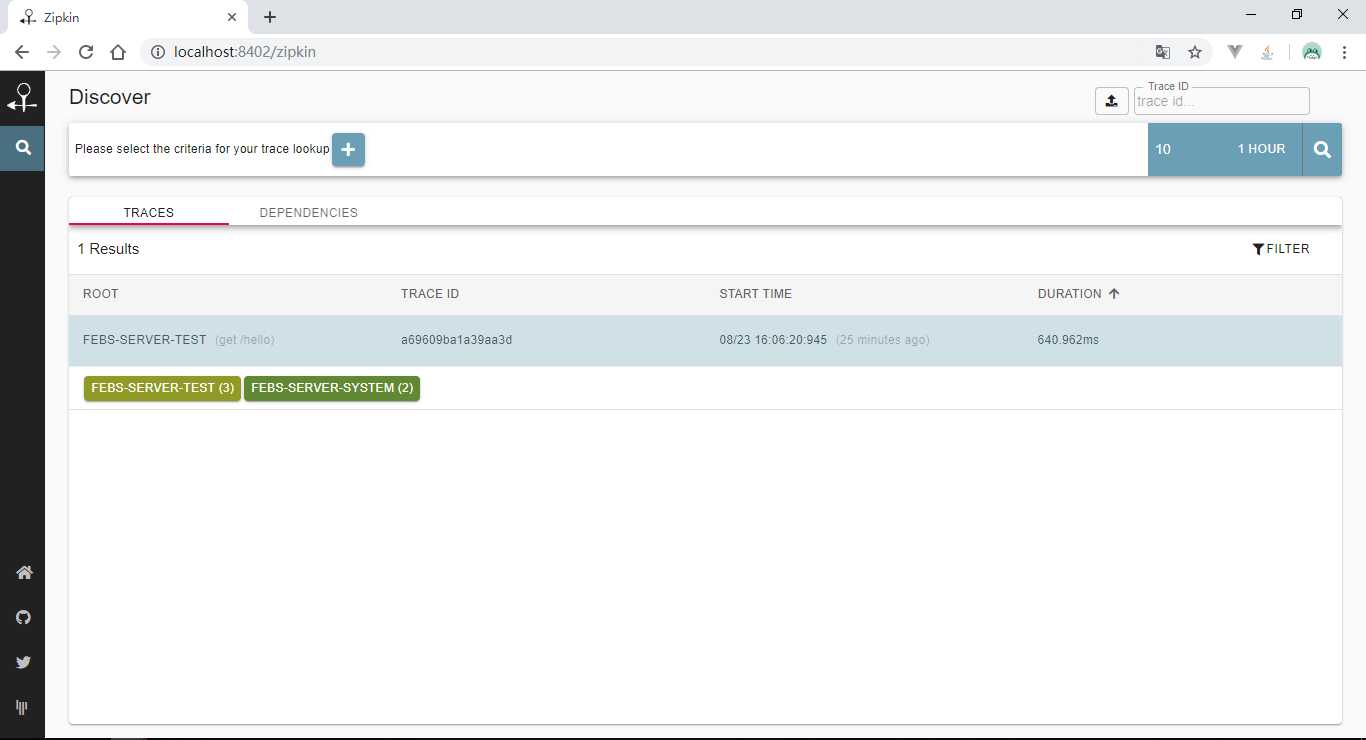
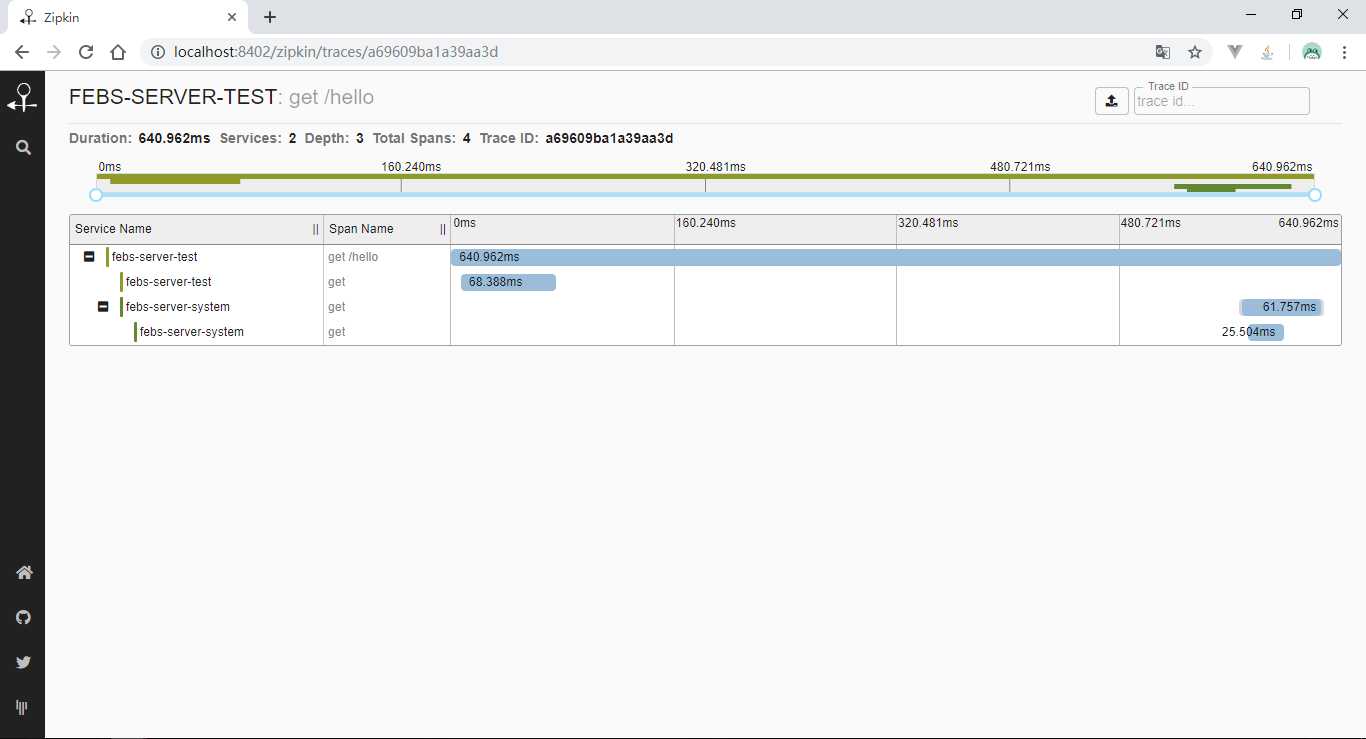
查看依赖关系:
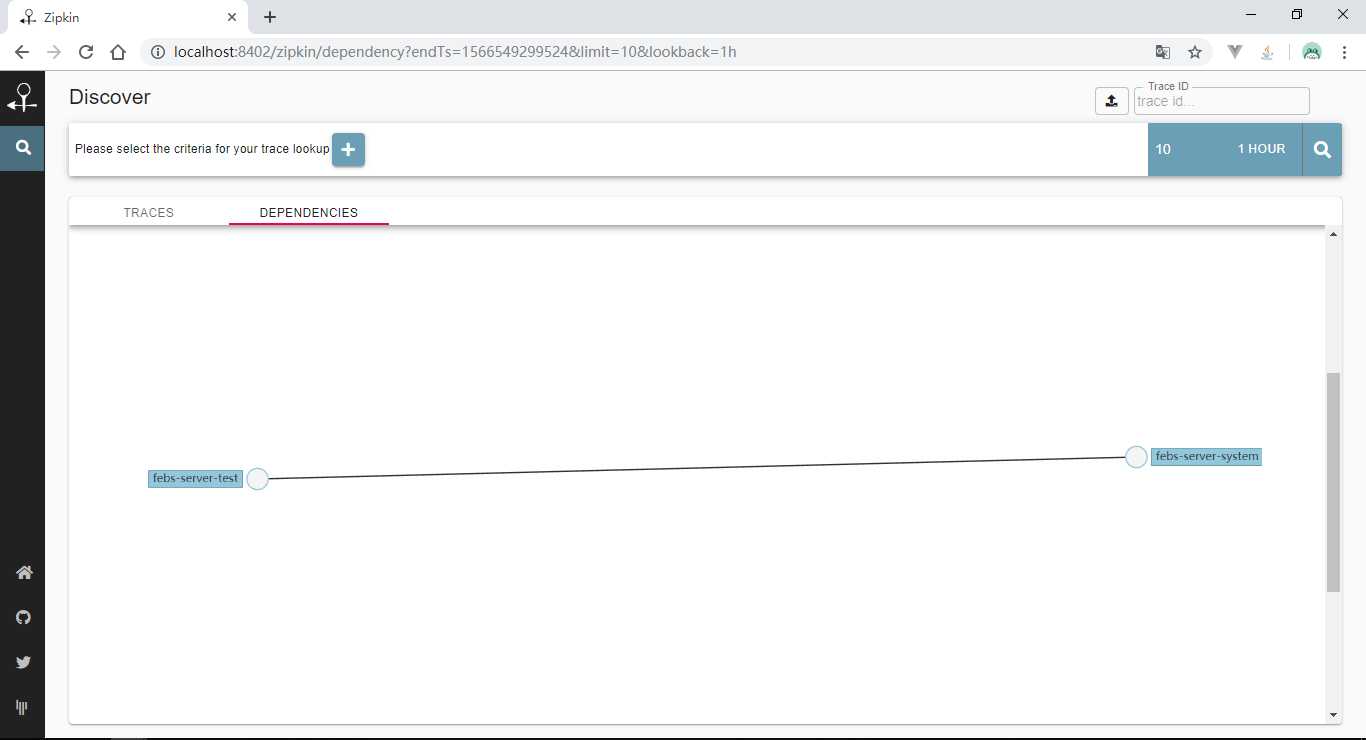
查看数据表,看是否存储了信息:
公众号:良许Linux

rabbitmq+sleuth+zinkip 分布式链路追踪
标签:sed 转移 目录 value 文章 源码 rac 客户 集成
原文地址:https://www.cnblogs.com/yychuyu/p/13324532.html