标签:ati 不同 inf sof 手动 重分布 perm code entry
1、Weight 权重越大越优 思科私有
2、local-prefence 本地优先级默认100越大越优
3、本地优先 任何条目都没有本地优先
4、As-path越短越优,
5、origin 起源
6、med
7、ebgp优于ibgp
8、优选next-hop最近的路由
9、BGP负载均衡 //不做为选路原则
10、old bgp 关系越老越优
11、rid越小越优
12、cluster-list越短越优
13、neighbor的ip越小的越优
首先你要明白,什么时候需要选路,如果就有一条链路中更新过来的东西,还有必须选吗?当然没有必要,这是必须要先搞清楚的,当有多条线中更新过来有重复的条目时,就要进行选取最优条目,这13条原则,就是帮助/执行决策,然后放入路由的。
权重,本地设备有效,默认值为0,【cisco私有】
具体的配置思路要使用route-map进行调用
思路,既然只能设置本地有效,且只能是in方向,肯定是在有路由有基础之上才可以做
1 ACL/prefix-list抓取相应的条目
1 route-map 条目
2 给特定的邻居定义策略并指定应用方向
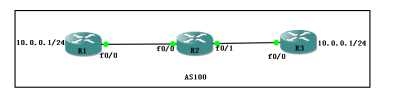
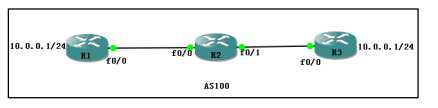
全网支持bgp,使用as100,建立IBGP关系,另外由R1和R3分别宣告两个条目,方式要相同。
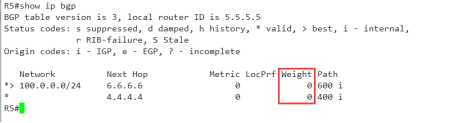
配置方面直接略过,直接 在R2上查BGP表,
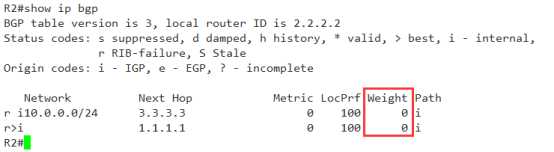
这时你会发现 两个条目的weight都是0,如果不参照其它因素,肯定是无法进行比较的,
那怎么办呢?
好办,现在它优选的是R1更新过来的条目,我们通过配置策略,把这个优选改成R3的
R2(config)#access-list 1 per 10.0.0.0 //抓取路由前缀 R2(config)#route-map weight per 10 //明明weight的条目 R2(config-route-map)#ma ip add 1 //指定ACL列表序号 R2(config-route-map)#set weight 30 //设置权重值—30,<-65535> R2(config-route-map)#exit R2(config)#route-map weight per 20 //千万不要忘了,要放行其它条目,因为现实中不可能就你这一条 R2(config)#router bgp 100 ///进入BGP进程 R2(config-router)#nei 3.3.3.3 route-map weight in //针对3.3.3.3调用策略应用在in 方向
再来查看一下是否生效了呢~
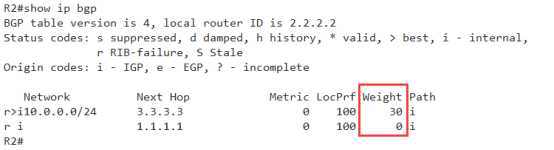
有了,没问题
数值改了,best也过去了,
如果是应用在out方向上会怎么样呢?之前说过,这个weight是本地设备有效,不可能去传递给其它设备,所以,只能配置在in 方向上,不信咱们可以试一下
加深一下印象而已嘛~
针对于1.1.1.1 应用out策略

看到了吧,直接就报错,not supported,不支持这样操作。
这也充分验证了,weight属性是可选非传递的,设备不一定认识,而且也可以不传递,看来只有针对于本地才有效的。
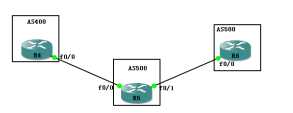
其实换汤不换药,还是一样的道理,只不过就是EBGP的配置与IBGP的配置不相同而已,策略部份全都一样的.
咱们直接应用策略
可以看到ebgp环境下,weight同样默认是为0,还是那句话,这是本地,本设备有效的,不会传递给其它设备的,
我们来配置一下策略,让4.4.4.4 成为最优,那么就直接给4.4.4.4 这个peer设置route-map即可,set weight
R5(config)#do show ip access Standard IP access list 1 10 permit 100.0.0.0 (4 matches) R5(config)#do show run | se route- route-map weight permit 10 match ip address 1 set weight 10
route-map weight permit 20 R5(config)#router bgp 500 R5(config-router)#nei 4.4.4.4 route-map weight in
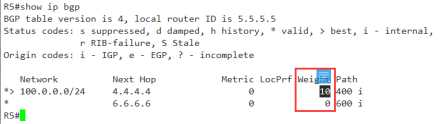
OK,no problem,不管你是ibgp,还是ebgp,只要是我在本地进行设置weight就可以对你这个条目生效。
默认数据100,越大越优。
本地优先级,这里的本地指的是本AS内部,也就可以理解为在AS内部生效,在外部的话就是不生效的。也可以直接理解为在as内部不管是In/out 都应该生效,而对于EBGP只有IN是生效的
行不行的,咱们来测试一下,就知道了,用事实说话
惯例,先运行ibgp(之前的所有策略均已清除)
清除所有的策略

现在系统选取的是1.1.1.1为最优,那我们通过对3.3.3.3的localpre进行修改,看看能不能将最优改过来
Standard IP access list 1 10 permit 10.0.0.0 (2 matches) R2(config)#route-map local per 10 R2(config-route-map)#ma ip add 1 R2(config-route-map)#set local-preference 200 R2(config-route-map)#exit R2(config)#route-map local per 20 R2(config)#router bgp 100 R2(config-router)#nei 3.3.3.3 route-map local in
Clear ip bgp * soft 加快BGP的收敛速度,触发更新

IBGP的IN方向没有任何的问题,数值也变了,BEST也变了,生效了
再来看一下IBGP的out方向是否可以
现在最优的是3.3.3.3,那我们再把1.1.1.1的条目加大local-pre,应用在out,上看能否生效
R1(config)#access-list 1 per 10.0.0.0 //抓取前缀 R1(config)#route-map local1 per 10 //定义名字为local1 R1(config-route-map)#ma ip add 1 R1(config-route-map)#set local 300 //配置local-pre为300 R1(config-route-map)#exit R1(config)#route-map local1 per 20 //允许其它 R1(config-route-map)#exit R1(config)#router bgp 100 //进入进程 R1(config-router)#nei 2.2.2.2 route-map local1 out //在out方向对2.2.2.2 应用策略
看看是否会生效呢~

OK ,同样是生效的,证明我们之前的推断是正确的。
首先先要明确一点,对于EBGP而言,更新到本地的路由,默认localpre是空的,空的,不是零,是空的,证明什么?LOCAL-pre是本地AS的优先级,和EBGP关系不大,你在AS内部就算再大,到了我EBGP的那里,也是空的。
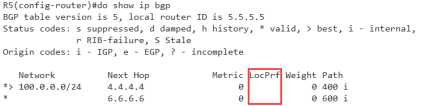
现在优选于4.4.4.4 的条目,我们通过对6.6.6进行策略部署,看能否生效,现在是in方向
R5(config)#do show ip access Standard IP access list 1 10 permit 100.0.0.0 (5 matches) R5(config)#route-map local per 10 R5(config-route-map)#ma ip add 1 R5(config-route-map)#se local-preference 200 R5(config-route-map)#exit R5(config)#route-map local per 20 R5(config-route-map)#exit R5(config)#router bgp 500 R5(config-router)#nei 6.6.6.6 route-map local in
查看配置是否生效

没问题,数值可以修改,且策略也生效,看来EBGP的IN方向是没有问题的
那么Out方向呢?在4.4.4.4 上做,配置out方向为300看会怎么样
R4(config)#access-list 1 per 100.0.0.0 R4(config)#route-map local per 10 R4(config-route-map)#ma ip add 1 R4(config-route-map)#set local 300 R4(config-route-map)#exit R4(config)#route-map local per 20 R4(config)#router bgp 400 R4(config-router)#nei 5.5.5.5 route-map local out R4(config-router)#end 哎呀,可以配置,没问题啊,生效吗?

好像并不生效,
嘿嘿,没错,就是不生效,配置是一方面,但是策略能否生效,又是另一回事儿了,
记住,local-pre只在本AS内部进行传递,不会在update信息中包含这一属性到达别的AS中,所在EBGP关系中,local-pre只对in 生效,因为Local prefen不会被放到update信息中来进行更新到其它AS,所以就得到上了面的结果
无论你是ebgp,还是ibgp,都不可能有我的本地network条目优先,是这为什么?
咱们可以看一下,
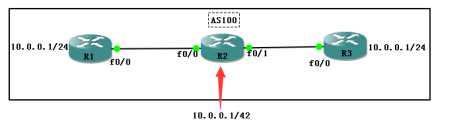
全网为IBGP邻居关系,R1和R3分别向BGP网络中宣告10.0.0.0/24条目,
在R2上也宣告一个同样的BGP条目,看看效果会怎么样?
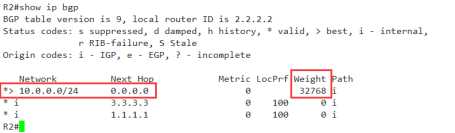
如果在本设备上宣告同网段后,肯定会出现这样的现象,
1 next-hop 0.0.0.0 ,本地为下一跳地址,
2 weight 权重值,本地的为32768
如果你想要比这个还优的话,可以进行修改其它条目的weight,但是真的会管用吗?
行不行的咱们试一下就知道了
比如我们修改一个来自于R1的weight为32769(只要比32768大就可以了)

OK ,可以改啊,之前也作过关于weight的配置,完全没有问题
但是会发现有些不对,条目的最前边,由原来的* 变成了r,
小r的意思,是rib-failure,放入路由表失败,这个就有点儿意思了,
你是在BGP表里最优的,但是你不是路由表里最优的,
不要忘了,我本地可是有这个条目存在的。
所以根本就不会把你放到我的路由表中。
各种协议的AD值还记得吗?回忆一下?
直连Connect AD=0
静态 Static AD=1
RIP AD=120
EIGRP AD=90/170
OSPF AD=110
IBGP=200
EBGP=20
相同路由不同路径比协议,相同路由相同协议比度量值,稍微一比,BGP就被C甩了几条街。没有可比性。
其实无论是EBGP,还是IBGP,修改比本地优先的办法就是去调整weight值,
然而,并没有什么用。
EBGP我们就不试验了,等于是重复操作。有兴趣的可以自己测试一下
AS-path,这一路径属性,之前提到过,现在再次重申,
AS-PATH有两个作用, 用于标记所经过的AS号
用于IBGP防环
其实对于EBGP同样奏效
这一路径属性,只针对于EBGP而定的,因为只有EBGP才会牵扯到经过AS
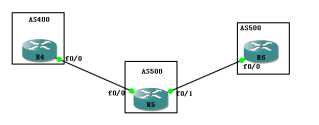
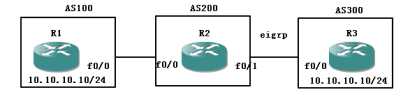
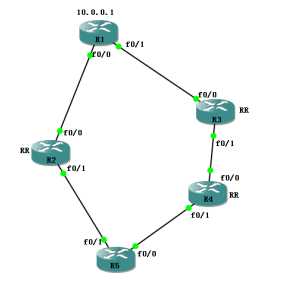
还记得我在最开始画下的那个图吗?
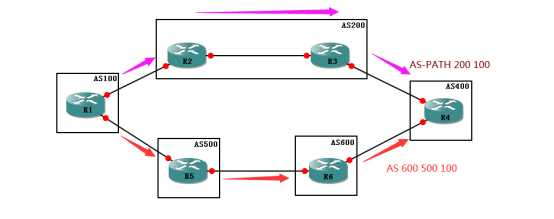
如图中所求,R1有一个更新发往R4,请问哪条线路最好呢?
答案无可厚非,肯定是上面,
为什么?
因为上面只经过了两个AS就到了,
而下面要经过三个AS才可以,
再次重申,BGP协议看的不是经过的路由设备个数,而是经过的AS个数。
所谓越短越优,就是经过的AS越少,则被BGP视为最优路径
当然也可以通过set命令来进行修改,但是修改的时候有一个小技巧,咱们来看一下实验
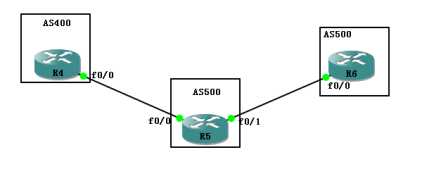
此时不做任何的配置,R4和R6发布相同路由前缀到EBGP中,在R5上看到的是有两条相同的条目

这里比的是个数、数量,而不是序号的大小,请注意哦~
现在优选6.6.6.6 ,那我们可以对这个条目的6.6.6.6进行策略控制,让它经过的AS变多,从而使4.4.4.4发过来的条目变成best
怎么做呢?
前文提过,AS-PATH为公认必遵的属性,那么任何一个update包中必须包含的,那么应该说无论是in 还是out,都应该是没问题的
配置思路
ACL抓取条目
定义route-map 关联条目
set as-path
允许其它条目经过
调整用策略(in/out方向)
配置如下
R5(config)#route-map as per 10 R5(config-route-map)#ma ip add 1 R5(config-route-map)#set as-path prepend 600 600 //为了防止和其它AS冲突,使用自己本地的,当然可以多加几个 R5(config-route-map)#exit R5(config)#route-map as per 20 R5(config)#router bgp 500 R5(config-router)#nei 6.6.6.6 route-map as in
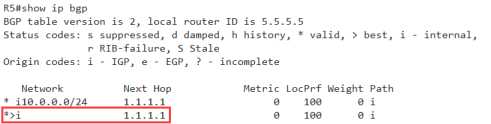
再到R5上查看一下BGP表

两点结果,
1 可以看到6.6.6.6的条目上,经过了3个600AS
2 best条目也已经变成了4.4.4.4
至此证明IN方向部署策略是没有问题的。
接上面的配置
我们在4.4.4.4的设备上进行配置,经过5个400,使6.6.6.6成为best
R4#show ip access Standard IP access list 1 10 permit 100.0.0.0 (4 matches) R4(config)#route-map as per 10 R4(config-route-map)#ma ip add 1 R4(config-route-map)#set as-path prepend 400 400 400 400 400 R4(config-route-map)#exit R4(config)#route-map as per 20 R4(config-route-map)#exit R4(config)#router bgp 400 R4(config-router)#nei 5.5.5.5 route-map as out
再到R5上看一下

同样也是没问题的,
OK ,看来,in/out都是OK的
5 origin 起源
起源属性,属于公认必遵,所有的BGP设备都必须要支持的,那么就很好理解了,对于策略的部署,可以使用out,也可以使用in了,因为update包是必须携带这个属性值的。
当然,除了通过配置策略来使它的类型变成incomplete,还有一种可能,就是在将路由宣告进 BGP时就是使用的重分布,这样直接 就是incomplete形式的,
起源的类型
i—IGP BGP内部,这可不是IGP协议啊~你可以理解为internal
e—egp EGP,BGP的前身,现在已经被淘汰了
?—incomplete 重分布形式
具体的关键字提醒,,在show ip bgp 的时候可以很清楚的看到

Origin 属性如果需要设置,需要和route-map进行关联
配置思路
ACL抓取
Route-map定义
Set origin

针对于邻居调用,因为是公认必遵属性,所以in/out都无所谓的,但要注意所在位置
实验IBGP部份
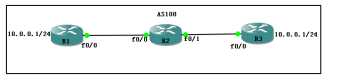
此时在R2上看到的条目是这样的

现在我们要做的是将1.1.1.1这个条目的起源类型改成e,使用in 方向进行调用策略
Standard IP access list 1 10 permit 10.0.0.0 (5 matches) R2(config)#route-map origin per 10 R2(config-route-map)#ma ip add 1 R2(config-route-map)#set origin egp 500 //配置EGP时,要加上AS号 R2(config)#route-map origin per 20 R2(config)#router bgp 100 R2(config-router)#nei 1.1.1.1 route-map origin in
那么再到R2上查看一下BGP表,看会是什么样的
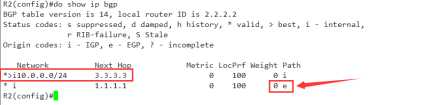
发现1.1.1.1的条目,起源变成了e,那么i>e>?
此时我们在到R3上设置out方向的策略,将它改成incomplete,来看一下会发生什么.

这时发现1.1.1.1的优先权又回来了,
R3(config)#access-list 1 per 10.0.0.0 R3(config)#route-map origin per 10 R3(config-route-map)#ma ip add 1 R3(config-route-map)#set ori incomplete R3(config-route-map)#exit R3(config)#route-map origin per 20 R3(config-route-map)#exit R3(config)#router bgp 100 R3(config-router)#nei 2.2.2.2 route-map origin out
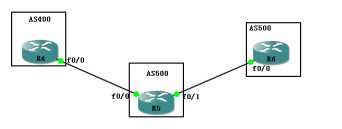
默认情况下不进行任何的属性修改,在R5上查看配置是这样儿的

Standard IP access list 1 10 permit 100.0.0.0 (9 matches) R5(config)#route-map ori per 10 R5(config-route-map)#ma ip add 1 R5(config-route-map)#set ori egp 100 //配置EGP时也要加上AS号 R5(config-route-map)#exit R5(config)#route-map ori per 20 R5(config)#router bgp 500 R5(config-router)#nei 6.6.6.6 route-map ori in
查看配置

对于ebgp而言,in方向测试成功
再来测试一下out方向,我们再将4改成?
R4(config)#route-map ori per 10 R4(config-route-map)#ma ip add 1 R4(config-route-map)#set ori incomplete //修改起源为重分布方式 R4(config-route-map)#exit R4(config)#route-map ori per 20 R4(config-route-map)#exit R4(config)#router bgp 400 R4(config-router)#nei 5.5.5.5 route-map ori out
再到R5上看一下配置

没有任何的问题
总结:
可以再次的确认,这种公认必遵属性的好处就是无认你是in 还是out方向上部署策略,都很灵活.
Med,说白了就是BGP的metric值,如果是本地宣告的话,那么默认就是0,越小越优
但如果是由IGP学习到的条目再进行宣告,会继承IGP的metric
如下图
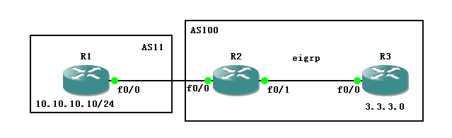
此时,R2—R3运行eigrp和BGP,且关系为IBGP,
那么在R2上show ip route 可以看到3.3.3.0为D的条目
那么在R2上,进入BGP宣告这条路由,会是什么样的后果呢?
我们到R1上看一下BGP表

409600,好眼熟的数字 ,我们到R2上查看一下EIGRP的路由表

在R2上看到的metric,IGP 条目 eigrp协议的metric就是409600
所以验证了我们刚才所说的,如果条目是从IGP学到的,再宣告到BGP中,那么MED会继承IGP的metric。无论你是 static, ospf eigrp rip,都是一样,因为他们都属于IGP协议。
还是一样的方式带着思考往下走,
可选非传递的路由属性,那么是否可以认为 out方向不可以呢?
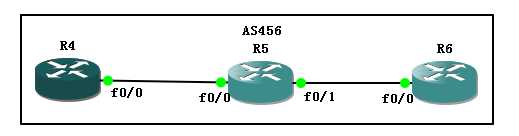
R4-R5-R6同时运行BGP,关系为IBGP,
由R4和R6同时宣告10.0.0.0/24条目,在R5上进行测试
先来看一下R5的BGP表

都是本地始发的,也没有从其它的IGP协议中学习到,那么此时的metric默认就是0,
之前说过,默认为0 ,越小越优,
现在最优的为4.4.4.4,那么我们通过策略来给4.4.4.4发来的条目增加metric,看看会有什么样的后果。
配置思路
ACL抓取条目
Route-map定义
Set metric
进程调整用(in/out)
R5(config)#access-list 1 per 10.0.0.0 R5(config)#route-map med per 10 R5(config-route-map)#ma ip add 1 R5(config-route-map)#set metric 10 //加大MED值 R5(config-route-map)#exit R5(config)#route-map med per 20 R5(config)#router bgp 456 R5(config-router)#nei 4.4.4.4 route-map med in
再来查看R5的BGP表,发现4.4.4.4条目的metric值 被修改了,变成了10,10比0大,那么0优先,所以6.6.6.6的条目更优先,至于前面的r,先不用管,是因为我在宣告eigrp的时候使用的是network 0.0.0.0,eigrp比ibgp更优。所以写入路由表失败了。但这不是我们现在要说的重点,请忽略。
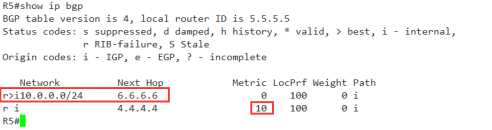
In 方向没有问题那么out方向呢?试一下,我们再把R6的metric改成20看一下
R6(config)#access-list 1 per 10.0.0.0 R6(config)#route-map med per 10 R6(config-route-map)#ma ip add 1 R6(config-route-map)#set metric 20 R6(config-route-map)#exit R6(config)#route-map med per 20 R6(config-route-map)#exit R6(config)#router bgp 456 R6(config-router)#nei 5.5.5.5 route-map med out
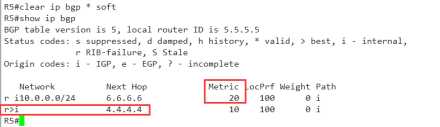
哦,看起来同样的奏效,,对于IBGP而言,无论是in 还是out,都生效的,
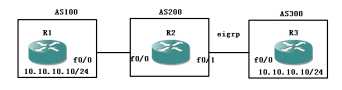
在EBGP的环境中去修改metric,看能不能是IBGP的效果
R2(config)#access-list 1 per 10.0.0.0 R2(config)#route-map med per 10 R2(config-route-map)#ma ip add 1 R2(config-route-map)#set metric 10 R2(config-route-map)#exit R2(config)#route-map med per 20 R2(config-route-map)#exit R2(config)#router bgp 200 R2(config-router)#nei 1.1.1.1 route-map med in
照常一样的配置,那么会生效吗/
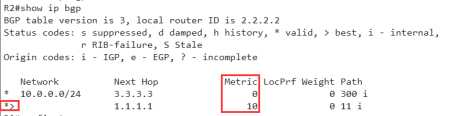
可以看到,虽然metric值已经被修改过来了,但是你会发现,并没有对best条目进行干预,
为什么?
因为在ebgp的环境中,如果想要让metric起做用,还要有一条特殊的命令。
R2(config-router)#bgp always-compare-med //总是比较med,这一点有点特殊,请记住
输入完命令以后会怎么样呢?
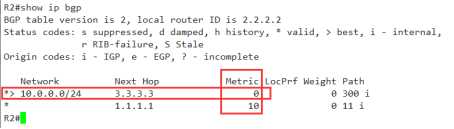
OK,没有问题,metric值也改变了,best条目也发生了变化
看来ebgp的关系下,修改metric是需要特殊命令,但是也可以生效
再来看一下out方向
由于metric越小越优,那我们再把3.3.3.3的条目metric值加大到20
看下效果,always-compare-med肯定是要跟上的
R3(config)#access-list 1 per 10.0.0.0 R3(config)#route-map med per 10 R3(config-route-map)#ma ip add 1 R3(config-route-map)#set me 20 R3(config-route-map)#exit R3(config)#route-map med per 20 R3(config-route-map)#exit R3(config)#router bgp 300 R3(config-router)#nei 2.2.2.2 route-map med out //针对于邻居2.2.2.2应用out方向策略
R3(config-router)#bgp always-compare-med
在R2上查看一下BGP表
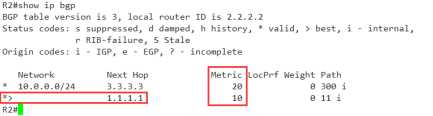
OK,妥妥的,没问题。
看来无认是IBGP,还是EBGP,对于bgp的med值(metric)来说,都是适用的,它是一个可选非传递的路径属性。
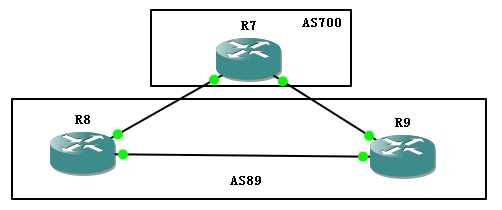
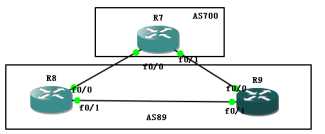
如图所示,R7和R8R9都是ebgp邻居关系,
R8R9为IBGP关系,现在在R7上network一个条目,
R8R9都会收到,且会转给自己的IBGP邻居。
我们在R9上查看BGP表,看看会发生什么
R7(config-router)#network 100.1.1.0 mas 255.255.255.0
只在R7上宣告100.1.1.0网段,
此时R8 会将从EBGP学来的条目发给自己的IBGP邻居,R9,但是下一跳地址同样是R7,这个之前讲过,是IBGP的next-hop特性,
我们还可以在R8上设置一个self,看看会有什么影响

无论你改成什么,效果都是一样的,EBGP就是比IBGP更优。且会被放入到路由表中。
注意,此时比较的并不是管理距离,因为还没有到路由表那一步,
这是BGP在设计的时候就这么安排 的,因为BGP 的主要作用就是在AS之间传递。
这里说到的next-hop,其实指的是IGP协议的度量值 ,IGP的各协议参考依据是否还记得起来?
举例来说明
实验IBGP部份
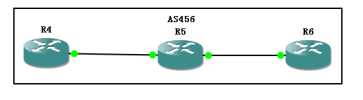
R4R5R6全部运行EIGRP协议,
然后由R4和R6分别宣告BGP条目,
到R5上查看,

此时优选走的是4.4.4.4
那么如何来查看哪边是到达next-hop的最近呢?
在BGP中可以查看一下具体条目的明细
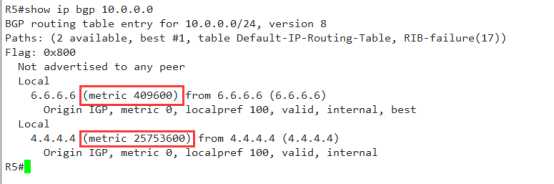
Show ip bgp 10.0.0.0(具体条目的明细信息)
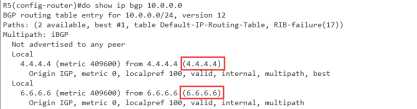
R5#show ip bgp 10.0.0.0 BGP routing table entry for 10.0.0.0/24, version 7 Paths: (2 available, best #2, table Default-IP-Routing-Table, RIB-failure(17)) Flag: 0x4800 Not advertised to any peer Local 6.6.6.6 (metric 409600) from 6.6.6.6 (6.6.6.6) 下一跳地址 metric值 来自6.6.6.6的更新RID为6.6.6.6 Origin IGP, metric 0, localpref 100, valid, internal 起源 IGP,i, med=0 本地优先级100 ,有效 ibgp Local 4.4.4.4 (metric 409600) from 4.4.4.4 (4.4.4.4) 来自4.4.4.4(RID4.4.4.4)的条目,下一跳为4.4.4.4 Origin IGP, metric 0, localpref 100, valid, internal, best //最优,不是在这比出来的
到这里你会发现,前面的都一样,到第8个选路原则的时候同样是比不出来的,
因为两条链路的metric是相同的,都是409600
我们这样做,针对于eigrp协议,我们可以人为的干预其metric的数值,针对于接口修改bandwith
现在最优的是4.4.4.4,那我们就把它这个接口的metric改大。
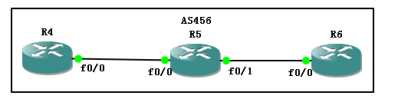
图中所示,和R4相连的是f0/0口,
OK
R5(config)#inter f0/0 R5(config-if)#bandwidth 100 //不是修改的实际带宽,只是用做选路用
再来看一下BGP表,有没有其它的变化
可以看到4.4.4.4 条目的metric值变大了,
在eigrp中,参考的主要有带宽和延迟,metric越大,说明带宽越小,
带宽越小,在eigrp中才不会被优选,
所以EIGRP就会认为这是一个相对于R6而言较远的路径,
而对于BGP而言,next-hop也就更远,
谁近我就选择谁
还是一样的情况,三个设备都运行了eigrp的底层协议,
然后,在其基础之上再运行ebgp,
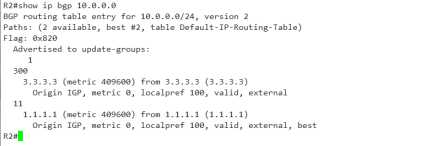
可以看到在R2上查看BGP表,两个EBGP邻居发来的metric值 都是一样的.
其修改方式是一样的
就不在赘述了
首先声明,这一条就不是用于做决策的,
当有两条全完一样的条目,(这里指的完全一样是有条件的),会将两个条目都放到路由表中,
实现负责均衡(当然,默认还是基于cef的负载均衡)
必须相同的路径属性包括
weight
Local prefen
As-path(不仅是长度相同,就连号码都要相同)
Origin
Med
IGP distance IGP的距离
只有以上条件都一样时,才可以成为BGP 的负载均衡
当然还有一条比较废话的要求 ,
就是每条路由的next-hop不相同,//是不是很费话,一个人也不可能给我发两条同样的啊
这里面的条件中包含了一个as-path,有了这个数据,就会很容易的想到,这是一个ebgp的关系,那IBGP会存在吗?当然会存在负载
由R8和R9同时向R7宣告一个相同的网段,
看看会是什么样儿的,(其它的什么配置都不要做)
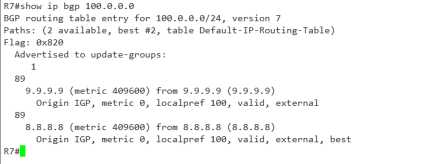
这是正常情况下R7所收到的100.0.0.0的条目
我们可以对比一下之前所提到的值 ,
weight=0 localpre=空 as-path=89,号码相同,距离相同
origin code=i, med=0 IGP metric 都是 409600
条件满足,且不是一个next-hop地址
所以可以实现负载均衡
但是功能默认是关闭的,需要我们手动的进行开启才OK
R7(config-router)#maximum-paths 2 ///后面的2表示两条,最大可以有16条 在maximun-path后面还可以加ibgp关键字,如果不加默认只对EBGP有效
来看一下效果吧
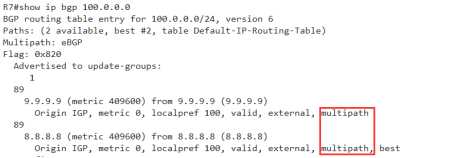
其它没有什么变化,
但是你会发现,在条目详细信息的最后面,出现了一个关键字,multipath,多路径
查看一下路由表,看看传说中的负载均衡.

出来了,出来了,
可是,这里必须要加一个可是
有没有发现,即使是在路由表中出现了负责均衡,可是在BGP表中,只有一条被选为BEST,
那条没有被选中的条目,是不会传递给别人的.
对于IBGP的负责,和之前是一样的条件,
但唯独不同的就是最后的命令有些不同
R5(config-router)#maximum-paths ibgp 2
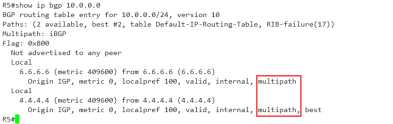
No problem,妥妥的,出现了multipath关键字。
但由于IBGP的AD=200,eigrp=90,所以没能该条目放到路由表中。遗憾啊
OLD 老的意思,越老越优先,越老交情越好,这里指的老,并不是设备老,而是建立BGP邻居的时间相对较老。
注意,这一条原则,IBGP的环境是不支持的。
不过通常我们是不让它选择这个的,因为不确认因素太多,
一般都是跳过,
只要咱们知道有这个事儿就行,
配置让其跳过这个选项,直接进入下一个
R5(config-router)#bgp bestpath compare-routerid
BGP最优路径比较router-id (也就是第十一条)
先声明一下在BGP中的router-id,其实和OSPF的一样一样的,
可以自动选举,也可以手动指定,通常我们都是手动指定的,用于标记设备用
那么当出现两条相同路径进行比较时,rid也是一项参考依据,RID越小的越优。


可以看目前优选的是4.4.4.4,具体是因为什么呢?
我们可以查看一下详细信息
在bgp表中的是下一跳地址(也就是所谓的更新源地址,因为我们使用的是loopback接口)
而在详细信息中显示的更加直接 ,()内的ID,是设备的RID。
那我们此时把4.4..4.4的rid改大,看会怎么样
R4(config)#router bgp 456 R4(config-router)#bgp rou 40.40.40.40
再到R5上来看看吧
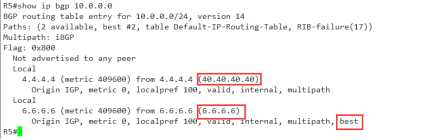
此时发现,修改过RID以后,就会出现神奇的一幕,
原来的best,变成了6.6.6.6
Cluster-list,即路由器射器所经过的ID数量 ,
与cluster-list共生存在的还有一个属性,那就是orignitor,发起者。
我们先来了解一下什么是路由器射器
路由反射器的定义,
由于IBGP关系中存在防环机制(水平分割),也就是说一个BGP路由器从邻居处学习到的条目,不会发给它的IBGP邻居,
而路由反射器的出现,得以破解这个限制,
但是破解了,还要再加上自己的限制
1、 如果接收到条目中,会进行originator的地址,
如果和自己的想同,则拒收,
如果和自己的不同,则接收
2、cluster-list中显示的是每经过一个RR反射器就会加一个标记(用RID进行标记),和AS-PATH的方式一样,每经过一个都要加一个
通过一个实验来进行理解
说到这里也大概能知道了,这玩意儿,只出现在IBGP的环境中,因为EBGP根本就不存在反射器的必要。
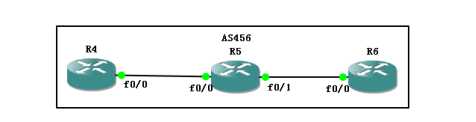
全网运行BGP
R4-R5为IBGP R5—R6为IBGP,
那么如果此时R4有一个新的网段宣告进来,会怎么样?
R5上可不可以收到?
R6上可不可以收到?
用事实说话
R4(config)#router bgp 456 R4(config-router)#network 4.4.4.0 mas 255.255.255.0
可以看到4.4.4.0/24的这个条目,R5是没有问题的,
R6呢?

连毛都没有,这就是IBGP水平分割的魔性,就是不给你.
好,我们现在使用路由反射器
反射器共有两个角色
中转设备: 就是执行中转任务的设备
客户端 : 中转设备的IBGP邻居
如上图所示,R5就成为了路由反射器,他需要将R4的更新过来的条目反射给R6
怎么操作呢?
其实很简单,就一条命令
R5(config)#router bgp 456 R5(config-router)#nei 4.4.4.4 route-reflector-client //将4.4.4.4 设置为我的客户端
此时再到R6上查看一下BGP表
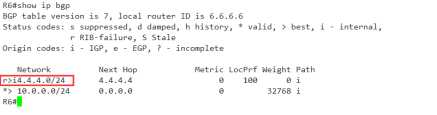
有了,有了
但是别急,
这个条目可不一般哦~
来看一下它的详细信息
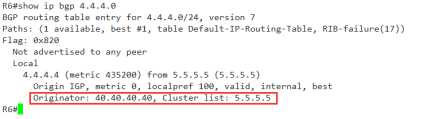
可以看到originator: 发起者为40.40.40.40,是R4,
而cluster list 是5.5.5.5,经过的反射器只有5.5.5.5一台
那么问题来了
如果拓扑图是这样的,
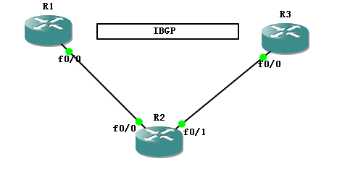
R1—R2直连,建立IBGP关系
R2—R3直连,建立IBGP关系
R1—R3非直连,建立 IBGP关系
由R1宣告一个网段进来,R2做反射器,
看R3会选择谁是最优路径
R1(config-if)#router bgp 100 R1(config-router)#network 10.10.10.0 mas 255.255.255.0
R3上查看
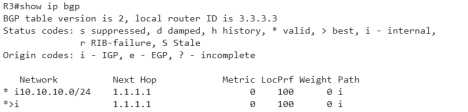
看到了两条,有点一时间摸不到头脑有没有,
因为两个next-hop是一样的,
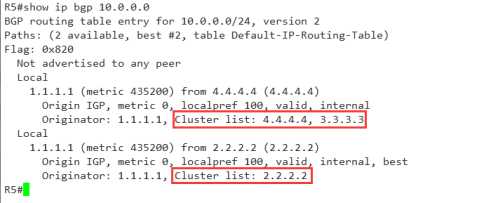
没关系,咱们进到详细信息里面看一下就知道了
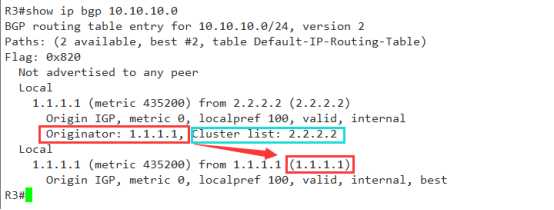
如果一个路径中携带了originator属性(始发者),那么就要用这条路径的originator值 和另一条路径的RID进行比较,,此时originator充当的是RID,
如果二者不相同,则遵循第十一条原则,RID小的优选
如果二者相同,则需要对比第十二项,cluster-list,
可以看到图中我进行了标记,
Cluster-list = 2.2.2.2,这说明两个问题,
1 经过了反射器它的RID是2.2.2.2
2 它只经过了这一个反射器
那么对比这个cluster-list后,不难发现,上面那条是经过反射学来的,
而下面这条根本就没有cluster-list的值 ,所以,被best了.当然会被优选.
此图中R2为反射器,client---R1
R3为反射器,clent---R1
R4为反射器client---R3
R1更新条目,请问哪边为最优线路
R2(config-router)#nei 1.1.1.1 route-reflector-client R3(config-router)#nei 1.1.1.1 route-reflector-client R4(config-router)#nei 3.3.3.3 route-reflector-client
在BGP表中啥也看不出来,我们必须要看详细列表
这里就是所提到的,每经过一个cluster-list,就会有一个标记,其实学到这里,越来越觉得bgp是根据RIP来开发的,(开个玩笑)
实验1
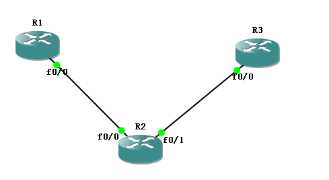
R2和R1,R3互为IBGP邻居,
此时,假设前面12条都比不出来,那么就要比较谁的IP小了
这时的IP,有些特殊,是在配置bgp时,neighbor指定的那个IP,
我们先把RID去掉,以确保能够达成实验效果
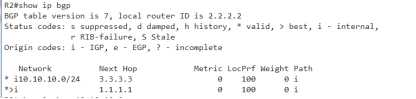
为什么会是1呢?
咱们逐一来看,
因为之前并没有配置过任何的策略,
那我们也要从头到尾的看一下,
1weight ,都是0
2local pre 都是100
3本地优先,此时没有本地条目
4as-path,这是IBGP的环境不存在as-path
5origin 都是i的,
6med,没动过都是0
7ebgp优于ibgp,现在的环境没有EBGP
8next-hop最近的优选,此时并没有配置修改过metric,两端也是相同的
9BGP负载均衡,跳过,咱们都没有配置
10old bgp,这条咱们越过了
11 rid越小越优, ///唉,可以看一下RID,因为之前的RID,被我取消了,那么RID是可以自己选举出来的,看一下吧
会发现,两台设备过来的RID都是10.10.10.10,咋整,继续往下比,
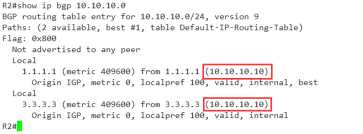
12cluster-list 此环境中不存在反射器
到了最后一条
13,neighbor的IP越小越优
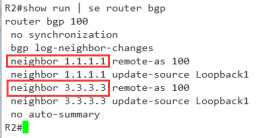
来看一下我们是怎么指的neighbor
噢 ,终于找到了,在这儿呢~ 1.1.1.1<3.3.3.3,所以它被优先了,
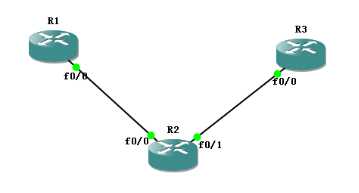
不指定更新源,不配置lo 接口,,全部用直连建立 IBGP关系
R1和R3宣告网段,看R2上看到底是谁优选
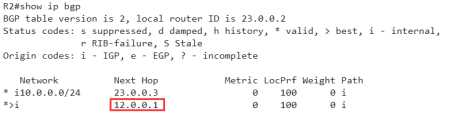
在BGP表中,可以看到是12.0.0.1 被选为最优,
再来看看详细的信息
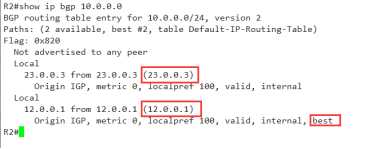
最后再看的话,只能是看配置了,不防再多看一眼吧
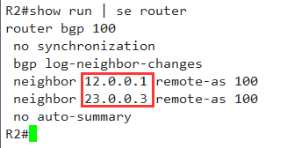
可以看到在建立邻居的时候,12.0.0.1就已经比23.0.0.3小了。所以才会优选它为最优

使用 45.0.0.4 ----45.0.0.5
54.0.0.4 ----54.0.0.5 进行直连,然后建立IBGP邻居
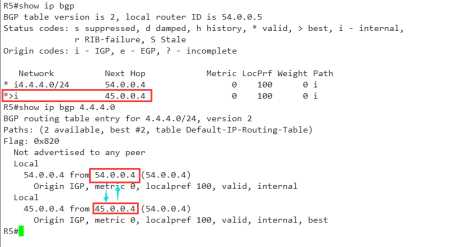
完全是遵照着我们的意思在前进,哈哈哈哈哈哈!!!
总结
13条选路原则,不是要你死记硬背,而是要熟练的掌握里面的奥妙,
而且它们是从上至下的顺序,如果说你要进行策略修改的话,最好是先从公认必遵的属性开始,这是个人的一个看法.因为相对要灵活一些,无论是in 还是out,都是OK 的.
--------------------------------------
CCIE成长之路 --- 梅利
标签:ati 不同 inf sof 手动 重分布 perm code entry
原文地址:https://www.cnblogs.com/meili333/p/13334493.html