标签:enum 存在 标签 rmi seq 验证 分数 lob state
一年前的这个时候,我逃课了一个星期,从澳洲飞去上海观看电竞比赛,也顺便在上海的一个公司联系了面试。当时,面试官问我对RNN的了解程度,我回答“没有了解”。但我把这个问题带回了学校,从此接触了RNN,以及它的加强版-LSTM。
时隔一年,LSTM好像已经可以退出历史舞台。BERT站在了舞台中间,它可以更快且更好的解决NLP问题。我打算以边学习边分享的方式,用BERT(GTP-2)过一遍常见的NLP问题。这一篇博客是文本分类的baseline system。
如果你熟悉transformer,相信理解bert对你来说没有任何难度。bert就是encoder的堆叠。
如果你不熟悉transformer,这篇文章是我见过的最棒的transformer图解,可以帮助你理解:http://jalammar.github.io/illustrated-transformer/
当然这个作者也做出了很棒的bert图解,链接在此:http://jalammar.github.io/illustrated-bert/
bert是encoder的堆叠。当我们向bert输入一句话,它会对这句话里的每一个词(严格说是token,有时也被称为word piece)进行并列处理,并为每个词输出对应的向量。我们给输入文本的句首添加一个[CLS] token(CLS为classification的缩写),然后我们只考虑这个CLS token的对应输出,用它来做classifier的输入,最终输出具体的分类。
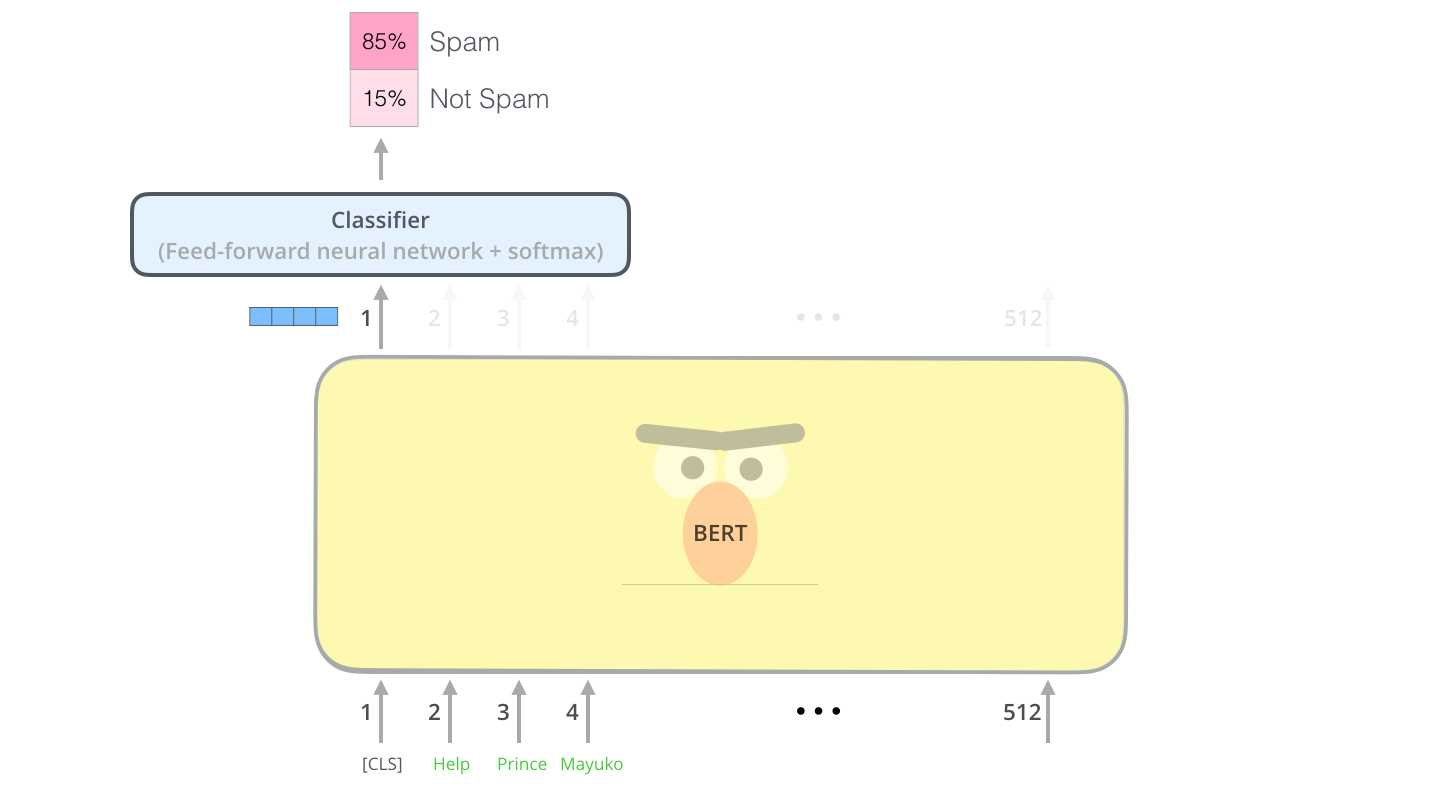
Huggingface可以帮助我们轻易的完成文本分类任务。
通过它,我们可以轻松的读取预训练语言模型,以及使用它自带的文本分类bert模型-BertForSequenceClassification。
数据来自Kaggle的competition:Real or Not? NLP with Disaster Tweets 链接:https://www.kaggle.com/c/nlp-getting-started
这是推特的数据集,数据的格式如下:
| id | location | keyword | text | target |
| 1 | 圣地亚哥 | 大火 | 圣地亚哥国家公园出现严重森林大火 | 1 |
| 2 | 硅谷 | 沙滩 | 今天在硅谷的沙滩晒太阳真开心 | 0 |
我们需要做的,就是根据推文的location、keyword 以及 text 来判断这篇推文是否和灾难有关。
它的现实意义在于,如果我们能够根据推文来第一时间发现灾难,有关部门就可以快速做出反应,将灾难的损失降低到最小。就像前段时间温岭油罐车爆炸,群众第一时间就把信息、视频上传到了微博,消防部门可以通过微博获取信息。
在拿到数据后,我们需要进行探索式资料分析。由于这不是本篇博客最重要的部分,这里我只给出大体轮廓和结论。在我的kaggle notebook上有详细的代码及plot。https://www.kaggle.com/jianweitang/nlp-with-disaster-tweets-eda
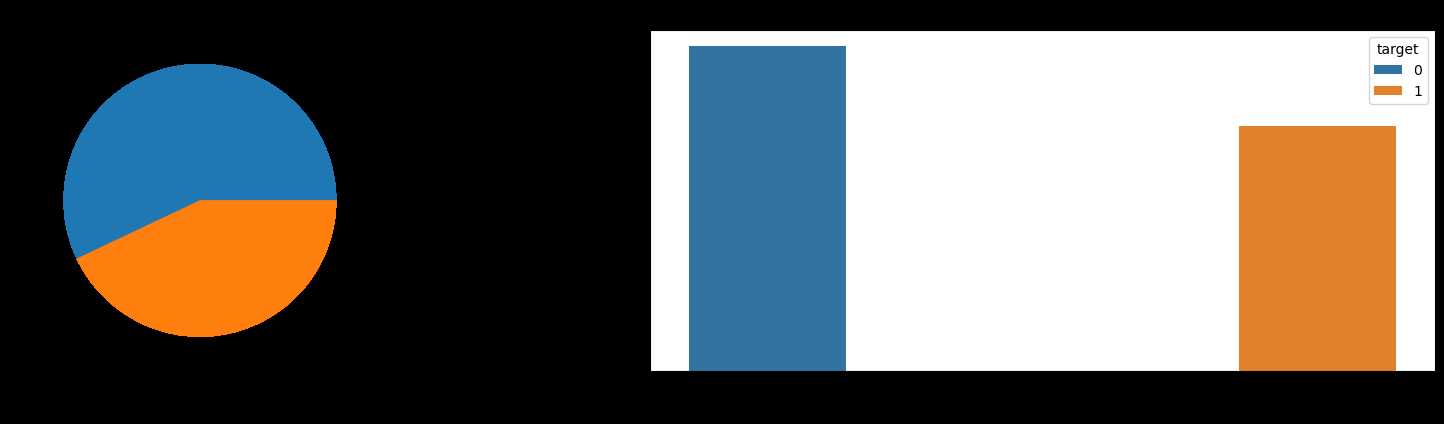
有标签的训练数据有7613条,无标签的测试数据有3263条
Training Set Shape: (7613, 5) Test Set Shape: (3263, 4)
对于location这一列,它具有较多的缺失值,并且有非常多的unique values,暂且认为很难将他与灾难直接联系到一起,我们直接把location这一列摒弃。
Number of unique values in keyword = 222 (Training) - 222 (Test) Number of unique values in location = 3342 (Training) - 1603 (Test)

而对于keyword这一列,它的缺失值很少,unique values有222个。同时它与label之间有可见的相关性,有些词只在灾难推文中出现,有些词只在非灾难推文中出现。如下图:

在数据中我们发现了重复的text被标记成了不同的标签,大概有十几个样本。这些样本可能是有争议,也可能是单纯的标记错误,在这里我们直接删掉这些样本。
import random import torch from torch.utils.data import TensorDataset, DataLoader, random_split from transformers import BertTokenizer from transformers import BertForSequenceClassification, AdamW from transformers import get_linear_schedule_with_warmup seed = 42 random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True device = torch.device(‘cuda‘)
我们先读取预训练的 bert-base-uncased 模型,用来进行分词,以及词向量转化
# Get text values and labels text_values = train[‘final_text‘].values labels = train[‘target‘].values # Load the pretrained Tokenizer tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased‘, do_lower_case=True)
来用这个tokenizer切分数据里的第一条推文试试看
print(‘Original Text : ‘, text_values[1]) print(‘Tokenized Text: ‘, tokenizer.tokenize(text_values[1])) print(‘Token IDs : ‘, tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text_values[1])))
输出:
Original Text : Forest fire near La Ronge Sask. Canada Tokenized Text: [‘forest‘, ‘fire‘, ‘near‘, ‘la‘, ‘ron‘, ‘##ge‘, ‘sas‘, ‘##k‘, ‘.‘, ‘canada‘] Token IDs : [3224, 2543, 2379, 2474, 6902, 3351, 21871, 2243, 1012, 2710]
除了分词以外,我们需要给它添加[CLS]和[SEP],以及[PAD],其中CLS在句首,SEP在句尾,PAD为统一句子长度的padding。这里看看tokenizer会给他们分别怎样的index。
text = ‘[CLS]‘ print(‘Original Text : ‘, text) print(‘Tokenized Text: ‘, tokenizer.tokenize(text)) print(‘Token IDs : ‘, tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))) print(‘\n‘) text = ‘[SEP]‘ print(‘Original Text : ‘, text) print(‘Tokenized Text: ‘, tokenizer.tokenize(text)) print(‘Token IDs : ‘, tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))) print(‘\n‘) text = ‘[PAD]‘ print(‘Original Text : ‘, text) print(‘Tokenized Text: ‘, tokenizer.tokenize(text)) print(‘Token IDs : ‘, tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text)))
输出:
Original Text : [CLS] Tokenized Text: [‘[CLS]‘] Token IDs : [101] Original Text : [SEP] Tokenized Text: [‘[SEP]‘] Token IDs : [102] Original Text : [PAD] Tokenized Text: [‘[PAD]‘] Token IDs : [0]
实际使用中,我们用tokenizer.encode()这个function来直接把文本转化为token_id 并添加special tokens。
我们定义一个encode_fn把数据集的整个文本都转化为tokens。
# Function to get token ids for a list of texts def encode_fn(text_list): all_input_ids = [] for text in text_values: input_ids = tokenizer.encode( text, add_special_tokens = True, # 添加special tokens, 也就是CLS和SEP max_length = 160, # 设定最大文本长度 pad_to_max_length = True, # pad到最大的长度 return_tensors = ‘pt‘ # 返回的类型为pytorch tensor ) all_input_ids.append(input_ids) all_input_ids = torch.cat(all_input_ids, dim=0) return all_input_ids
all_input_ids = encode_fn(text_values)
labels = torch.tensor(labels)
接下来,我们把数据分为训练集与验证集,并构建dataloader。
epochs = 4 batch_size = 32 # Split data into train and validation dataset = TensorDataset(all_input_ids, labels) train_size = int(0.90 * len(dataset)) val_size = len(dataset) - train_size train_dataset, val_dataset = random_split(dataset, [train_size, val_size]) # Create train and validation dataloaders train_dataloader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True) val_dataloader = DataLoader(val_dataset, batch_size = batch_size, shuffle = False)
加载与训练的bert模型, 并定义optimizer与learning rate scheduler
# Load the pretrained BERT model model = BertForSequenceClassification.from_pretrained(‘bert-base-uncased‘, num_labels=2, output_attentions=False, output_hidden_states=False) model.cuda() # create optimizer and learning rate schedule optimizer = AdamW(model.parameters(), lr=2e-5) total_steps = len(train_dataloader) * epochs scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
定义一个计算accuracy的方法,方便在训练的时候print出精确度的变化
from sklearn.metrics import f1_score, accuracy_score def flat_accuracy(preds, labels): """A function for calculating accuracy scores""" pred_flat = np.argmax(preds, axis=1).flatten() labels_flat = labels.flatten() return accuracy_score(labels_flat, pred_flat)
for epoch in range(epochs): model.train() total_loss, total_val_loss = 0, 0 total_eval_accuracy = 0 for step, batch in enumerate(train_dataloader): model.zero_grad() loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device)) total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() scheduler.step() model.eval() for i, batch in enumerate(val_dataloader): with torch.no_grad(): loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device)) total_val_loss += loss.item() logits = logits.detach().cpu().numpy() label_ids = batch[1].to(‘cpu‘).numpy() total_eval_accuracy += flat_accuracy(logits, label_ids) avg_train_loss = total_loss / len(train_dataloader) avg_val_loss = total_val_loss / len(val_dataloader) avg_val_accuracy = total_eval_accuracy / len(val_dataloader) print(f‘Train loss : {avg_train_loss}‘) print(f‘Validation loss: {avg_val_loss}‘) print(f‘Accuracy: {avg_val_accuracy:.2f}‘) print(‘\n‘)
输出:
Train loss : 0.441781023875452 Validation loss: 0.34831519580135745 Accuracy: 0.86 Train loss : 0.3275374324204257 Validation loss: 0.3286557973672946 Accuracy: 0.88 Train loss : 0.2503694619696874 Validation loss: 0.355623895690466 Accuracy: 0.86 Train loss : 0.19663514375973207 Validation loss: 0.3806843503067891 Accuracy: 0.86
这里比较特别的一点是,即使只有4个epochs,validation loss也是一直在增大的。我看了下其他人使用pytorch和huggingface的训练部分,也存在这个问题,反而使用tensorflow和TFhub的稍微好一点。我猜测这里的原因是过拟合。
这里与训练类似,把测试集构建为dataloade,然后将预测结果输出到csv文件。到这里整个流程就结束了。
# Create the test data loader text_values = df_test[‘final_text‘].values all_input_ids = encode_fn(text_values) pred_data = TensorDataset(all_input_ids) pred_dataloader = DataLoader(pred_data, batch_size=batch_size, shuffle=False)
model.eval() preds = [] for i, (batch,) in enumerate(pred_dataloader): with torch.no_grad(): outputs = model(batch.to(device), token_type_ids=None, attention_mask=(batch>0).to(device)) logits = outputs[0] logits = logits.detach().cpu().numpy() preds.append(logits) final_preds = np.concatenate(preds, axis=0) final_preds = np.argmax(final_preds, axis=1)
# Create submission file submission = pd.DataFrame() submission[‘id‘] = df_test[‘id‘] submission[‘target‘] = final_preds submission.to_csv(‘submission.csv‘, index=False)
我把预测结果上传后,score是0.83,在kaggle上排名100多。考虑到排名靠前的60位使用的不是NLP方法,他们找到了正确答案并直接上传得到了100%的正确率,我对这个简单模型的结果还是挺满意的。
也希望我对这个学习过程的分享,能够帮助到一同学习NLP的人。
pytorch+huggingface实现基于bert模型的文本分类(附代码)
标签:enum 存在 标签 rmi seq 验证 分数 lob state
原文地址:https://www.cnblogs.com/tangjianwei/p/13334327.html