标签:工作原理 参与 机制 理解 报文 vat 影响 技术 xss
首先来看一下“从输入URL到页面展示完整流程的示意图”
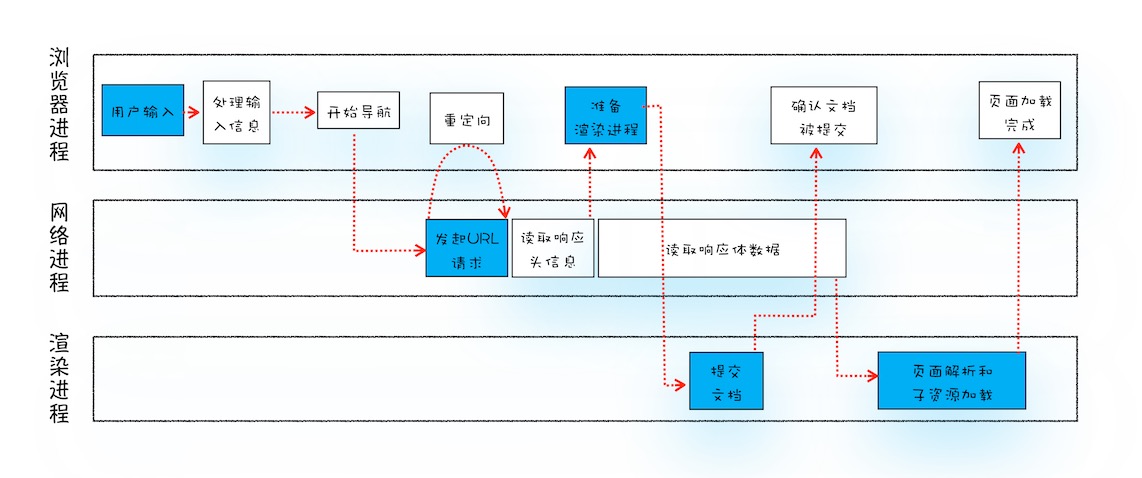
该图是浏览器多进程配合从而完成浏览器的页面跳转、渲染,主要有三个浏览器进程相互配合。
再来看一下其中“页面渲染流程图”
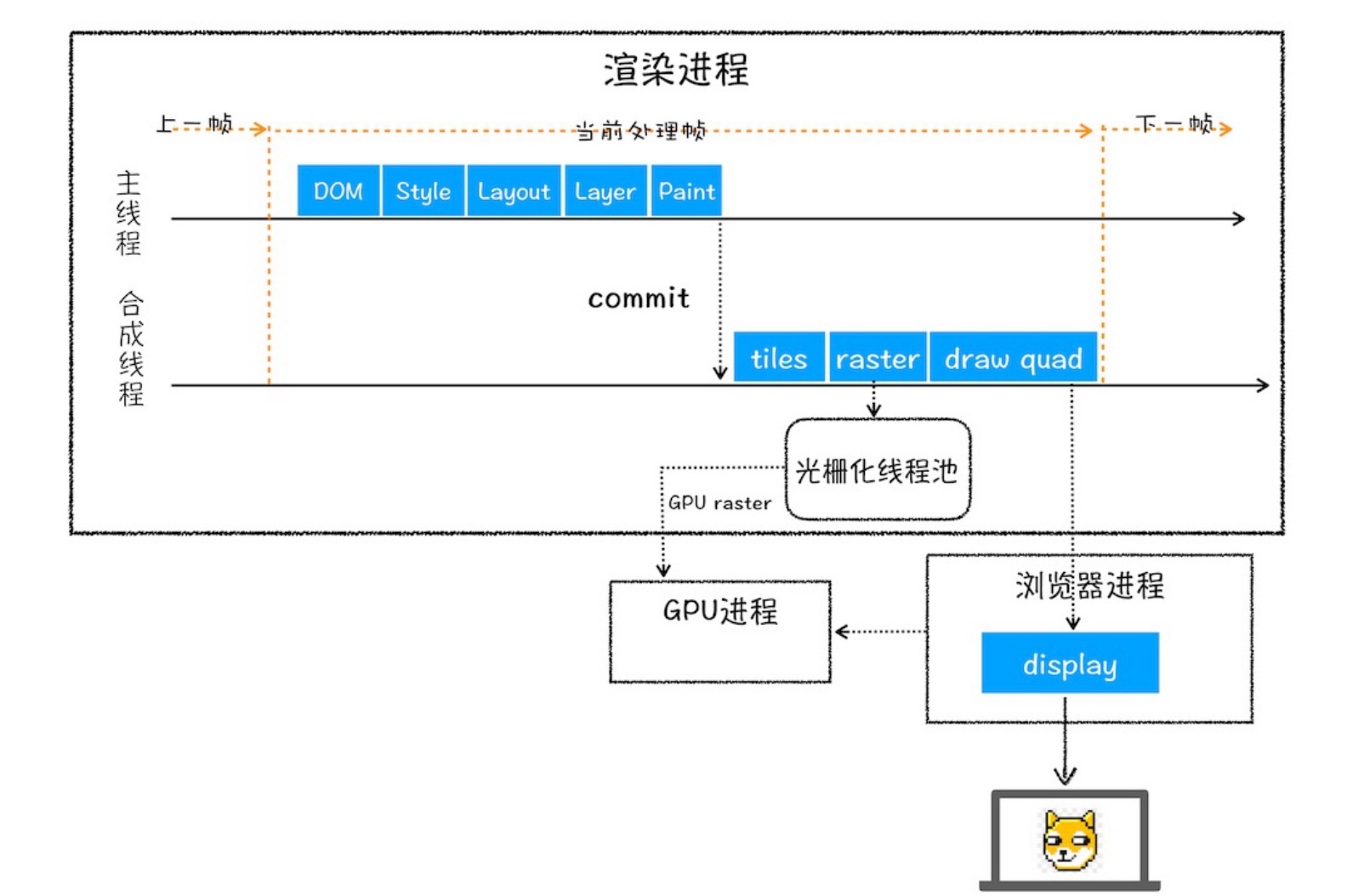
渲染流程:
将浏览器无法直接理解和使用的HTML转换为浏览器理解的DOM树
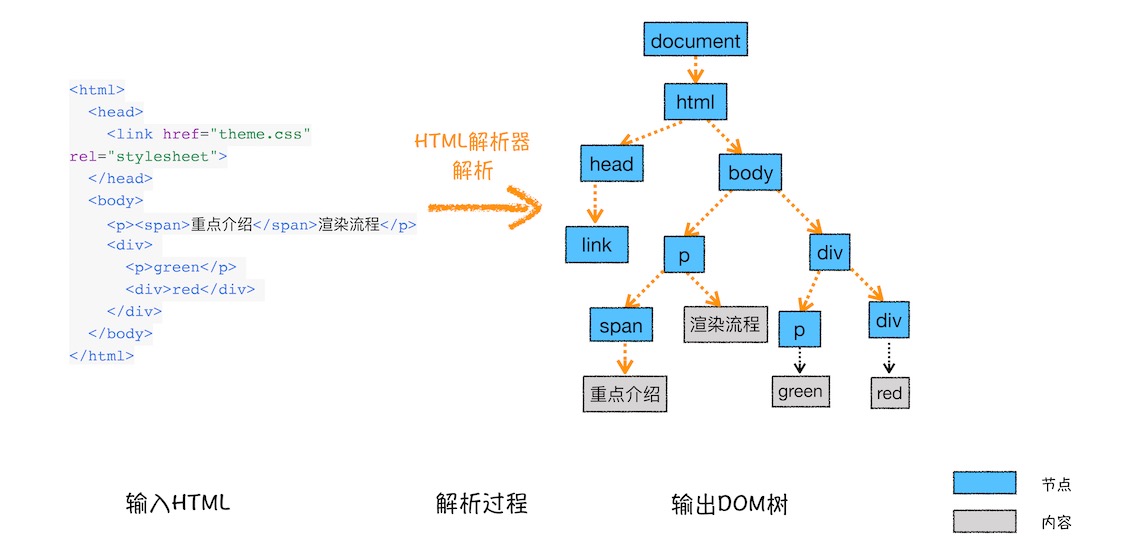
样式计算(Recalculate Sytle)
css文本转换成浏览器可以理解的结构styleSheetsDOM树将继承的样式以及自身样式合并布局(Layout)
创建一个只含可见元素的DOM布局树
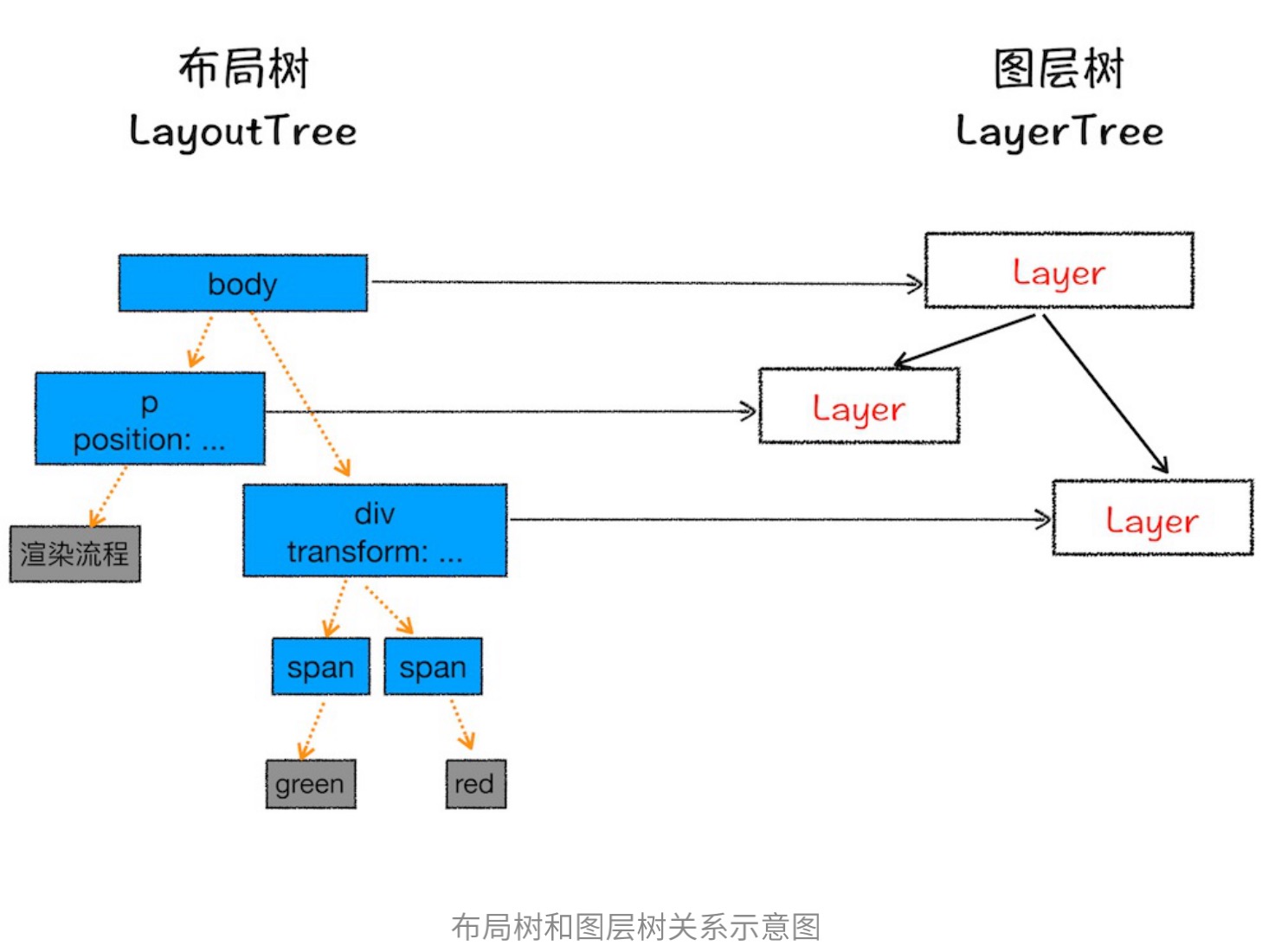
分层(Layer)
为了得到一些复杂的效果,需要对布局树进一步得到图层树,以下是会被单独提升为一层的情况
图层绘制(Paint)
渲染引擎会将各图层的绘制分成一个个小的绘制指令进行绘制
栅格化(raster)
此时渲染进程中的主线程会将绘制列表提交给合成线程,合成线程会按视口(viewport)附近图块来优先生成位图,这个过程就是栅格化来执行的。所谓的栅格就是指:将图块转换为位图。栅格化的过程回调用GPU,所以也会调用GPU进程
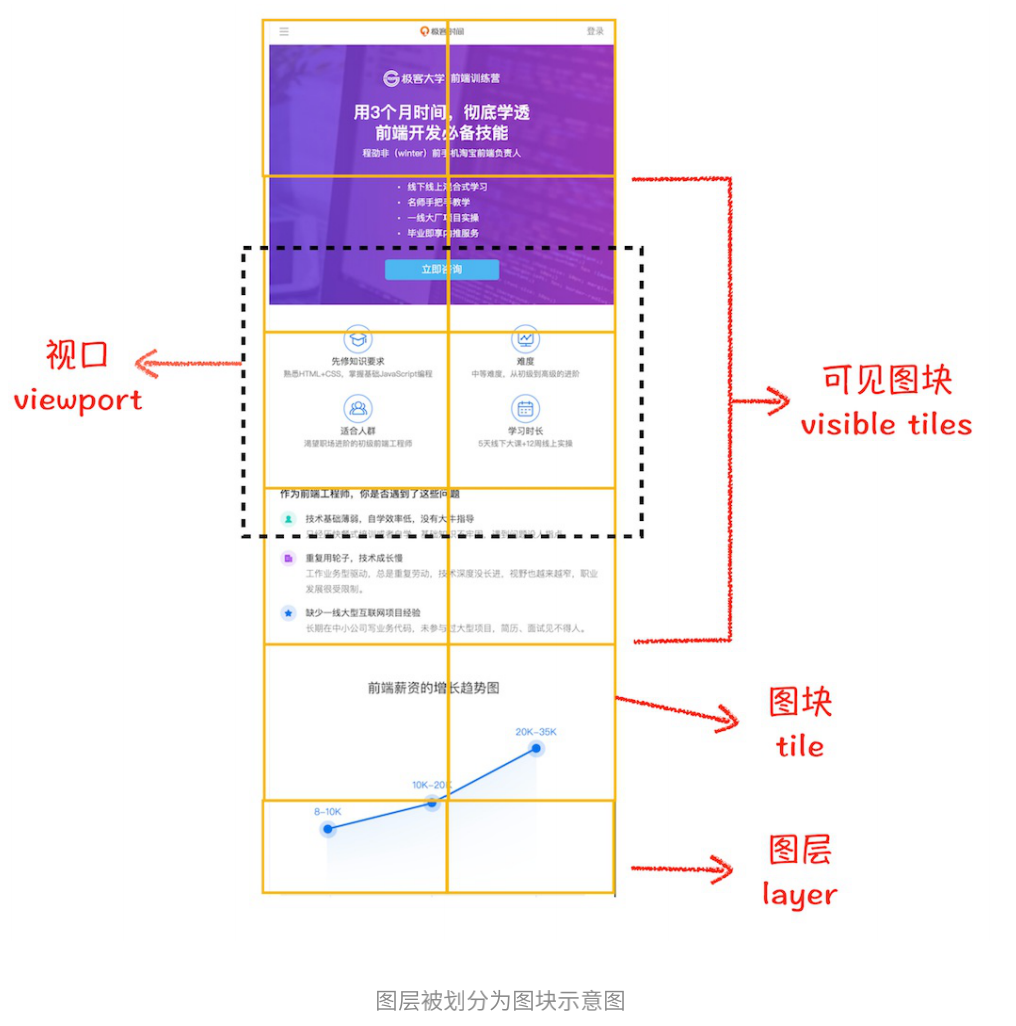
最后的合成与显示
如果所有的图块都被栅格化后,合成线程会生成一个绘制图块的命令--DrawQuad,并且将该命令提交给浏览器中的一个viz组件进行绘制
接下来就大致描述下这个过程:
首先,用户输入URL
浏览器检查的是否为URL,如果是URL则根据规则,在这段内容加上协议,合为完整的URL
浏览器进程通过进程间通信(IPC)将URL发送给网络进程。
网络进程请求后检查本地缓存是否缓存了该请求的资源,如果有则返回该资源给浏览器进程。
如果没有就向服务器发送http请求,请求流程如下:
HTTPS则还会建立TLS连接网络进程解析响应内容的流程
Location字段里读区重定向地址,然后重新再来。例如:在当你使用HTTP请求使用HTTPS的网站时,会给你重定向至HTTPS的网址Content-Type响应头类型处理的流程不同。准备渲染进程
提交文档
提交文档开始渲染
HTML转化成浏览器能读懂的DOM树CSS样式表转化成浏览器可以理解的styleSheets,计算DOM节点的样式同源策略是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSRF等攻击。所谓同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源。

但是有三个标签是允许跨域加载资源的
<img src=XXX><link href=XXX><script src=XXX>当协议、子域名、主域名、端口号任意一个不相同时,都算作不同域。不同域之间请求资源就算作“跨域”。
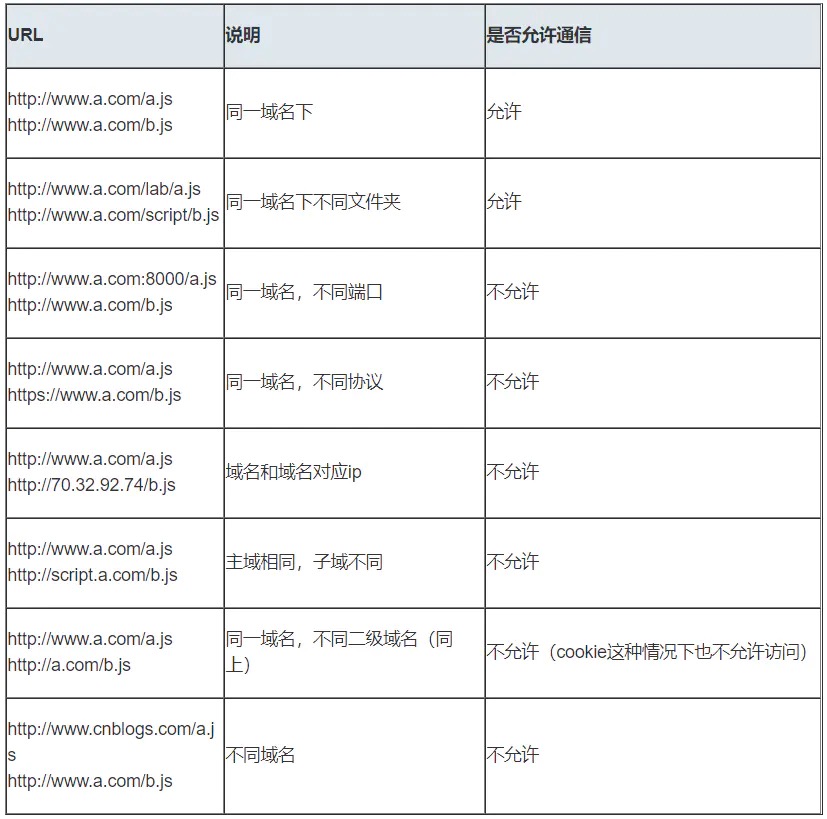
注:跨域请求并不是请求发不出去,请求是可以发送的,服务端也可以收到请求并正常返回,但由于浏览器的同源策略,响应结果被拦截了
JSONP的原理:
利用 <script> 标签没有跨域限制的漏洞,网页可以得到从其他来源动态产生的 JSON 数据。JSONP请求一定需要对方的服务器做支持才可以。
JSONP的实现流程:
比如,有个a.html页面,它里面的代码需要利用ajax获取一个不同域上的json数据,假设这个json数据地址是http://damonare.cn/data.php,那么a.html中的代码就可以这样:
?
<script type="text/javascript">
function dosomething(jsondata){
//处理获得的json数据
}
</script>
<script src="http://example.com/data.php?callback=dosomething"></script>
我们看到获取数据的地址后面还有一个callback参数,按惯例是用这个参数名,但是你用其他的也一样。当然如果获取数据的jsonp地址页面不是你自己能控制的,就得按照提供数据的那一方的规定格式来操作了。
因为是当做一个js文件来引入的,所以http://damonare.cn/data.php返回的必须是一个能执行的js文件,所以这个页面的php代码可能是这样的(一定要和后端约定好哦):
?
<?php
$callback = $_GET[‘callback‘];//得到回调函数名
$data = array(‘a‘,‘b‘,‘c‘);//要返回的数据
echo $callback.‘(‘.json_encode($data).‘)‘;//输出
?>
最终,输出结果为:dosomething([‘a‘,‘b‘,‘c‘]);
如果你的页面使用jquery,那么通过它封装的方法就能很方便的来进行jsonp操作了。
?
<script type="text/javascript">
$.getJSON(‘http://example.com/data.php?callback=?,function(jsondata)‘){
//处理获得的json数据
});
</script>
jquery会自动生成一个全局函数来替换callback=?中的问号,之后获取到数据后又会自动销毁,实际上就是起一个临时代理函数的作用。$.getJSON方法会自动判断是否跨域,不跨域的话,就调用普通的ajax方法;跨域的话,则会以异步加载js文件的形式来调用jsonp的回调函数。
JSONP的优缺点
JSONP的优点是:它不像XMLHttpRequest对象实现的Ajax请求那样受到同源策略的限制;它的兼容性更好,在更加古老的浏览器中都可以运行,不需要XMLHttpRequest或ActiveX的支持;并且在请求完毕后可以通过调用callback的方式回传结果。
JSONP的缺点则是:它只支持GET请求而不支持POST等其它类型的HTTP请求;它只支持跨域HTTP请求这种情况,不能解决不同域的两个页面之间如何进行JavaScript调用的问题。
CORS原理
CORS(Cross-Origin Resource Sharing)跨域资源共享,定义了必须在访问跨域资源时,浏览器与服务器应该如何沟通。CORS背后的基本思想就是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功还是失败。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
两种请求
简单请求
只要同时满足以下两大条件,就属于简单请求
条件1:使用下列方法之一:
条件2:Content-Type 的值仅限于下列三者之一:
请求中的任意 XMLHttpRequestUpload 对象均没有注册任何事件监听器; XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问。
复杂请求
复杂请求是对服务器有特殊要求的请求,比如请求方法是PUT、DELETE,或者Content-Type的字段类型是application/json。
复杂请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求,该请求是 OPTION 方法的,通过该请求来知道服务端是否允许跨域请求。
预检请求的HTTP头信息:
OPTIONS /cors HTTP/1.1 Origin: http://api.bob.com Access-Control-Request-Method: PUT /浏览器CORS请求用到的HTTP方法 Access-Control-Request-Headers: X-Custom-Header /CORS额外发送的透信息字段 Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...
服务端收到预检请求以后,检查完信息允许跨源请求,作出回应。
TTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://api.bob.com //表示该接口可以请求
Access-Control-Allow-Methods: GET, POST, PUT //返回支持的跨域请求方法
Access-Control-Allow-Headers: X-Custom-Header //支持所有头信息字段,不限于浏览器“预检”中请求的字段
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
使用nginx反向代理实现跨域,是最简单的跨域方式。只需要修改nginx的配置即可解决跨域问题,支持所有浏览器,支持session,不需要修改任何代码,并且不会影响服务器性能。
实现思路:通过nginx配置一个代理服务器(域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域登录。
先下载nginx,然后将nginx目录下的nginx.conf修改如下:
// proxy服务器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名
index index.html index.htm;
# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用
add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*
add_header Access-Control-Allow-Credentials true;
}
}
复制代码
最后通过命令行nginx -s reload启动nginx
// index.html
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问nginx中的代理服务器
xhr.open(‘get‘, ‘http://www.domain1.com:81/?user=admin‘, true);
xhr.send();
复制代码
// server.js
var http = require(‘http‘);
var server = http.createServer();
var qs = require(‘querystring‘);
server.on(‘request‘, function(req, res) {
var params = qs.parse(req.url.substring(2));
// 向前台写cookie
res.writeHead(200, {
‘Set-Cookie‘: ‘l=a123456;Path=/;Domain=www.domain2.com;HttpOnly‘ // HttpOnly:脚本无法读取
});
res.write(JSON.stringify(params));
res.end();
});
server.listen(‘8080‘);
console.log(‘Server is running at port 8080...‘);
MDN解释:
A browser cache holds all documents downloaded via HTTP by the user ... without requiring an additional trip to the server.
浏览器缓存者用户通过HTTP获取的所有资源,在下一次请求时可以避免重复向服务器发送出多余请求
一般浏览器缓存可以分为两类:
浏览器在加载资源时,会先判断是否命中强缓存再验证是否命中协商缓存。
强制缓存是向浏览器缓存查找缓存,根据缓存规则决定是否使用缓存结果的过程。强制缓存有三种情况
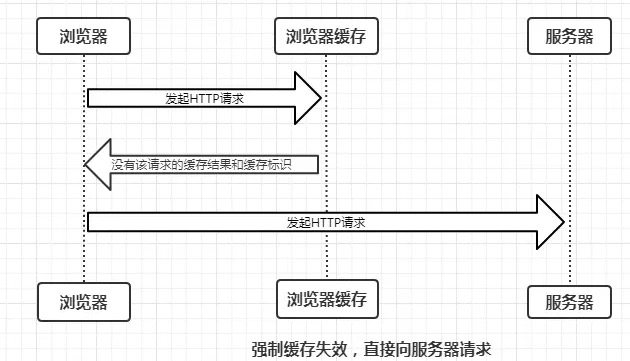
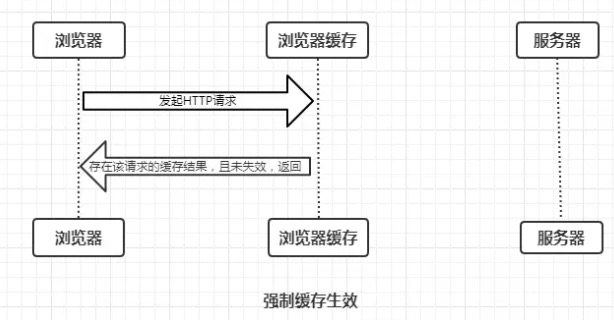
那么缓存规则是如何的?
当浏览器向服务器发起请求时,服务器将缓存规则放入HTTP响应报文的HTTP和请求结果一起返回给浏览器,控制强制缓存的字段时Expires、Cache-Control
Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。也就是说,Expires=max-age + 请求时间,需要和Last-modified结合使用。Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
Expires 是 HTTP/1 的产物,受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为:
Cache-Control的默认取值需要注意的是,
no-cache这个名字有一点误导。设置了no-cache之后,并不是说浏览器就不再缓存数据,只是浏览器在使用缓存数据时,需要先确认一下数据是否还跟服务器保持一致,也就是协商缓存。而no-store才表示不会被缓存,即不使用强制缓存,也不使用协商缓存
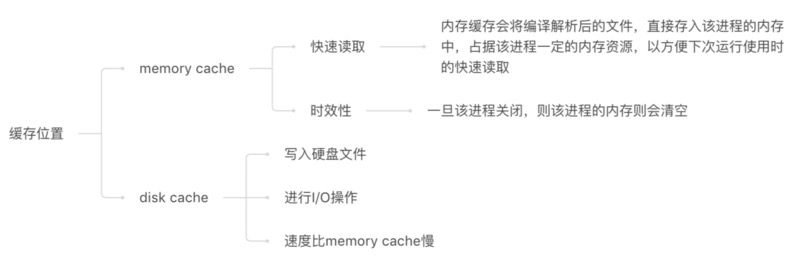
浏览器的缓存存放在哪里,如何在浏览器中判断强制缓存是否生效?这就是下面我们要讲到的from disk cache和from memory cache。
Chrome的网络请求的Size会出现三种情况from disk cache(磁盘缓存)、from memory cache(内存缓存)、以及资源大小数值。
| 状态 | 类型 | 说明 |
|---|---|---|
| 200 | form memory cache | 不请求网络资源,资源在内存当中,一般脚本、字体、图片会存在内存当中 |
| 200 | form disk ceche | 不请求网络资源,在磁盘当中,一般非脚本会存在内存当中,如css等 |
| 200 | 资源大小数值 | 从服务器下载最新资源 |
| 304 | 报文大小 | 请求服务端发现资源没有更新,使用本地资源 |
简单的对比一下
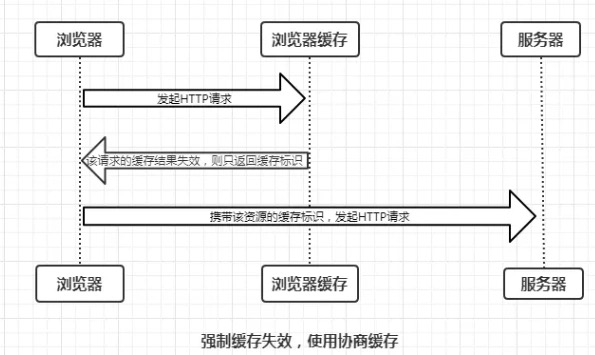
协商缓存就是浏览器存在缓存但缓存已失效,于是浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存。主要有两种情况:
304或者Not Modified,协商缓存生效
200以及请求结果,协商缓存失效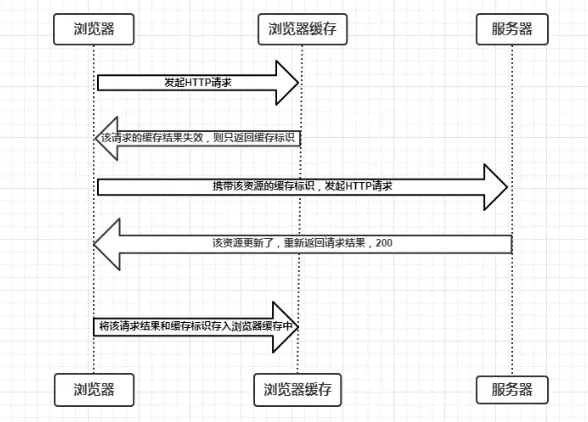
那么服务端是如何验证资源是否更新呢
Last-Modified和If-Modified-Since验证流程:
Last-Modified字段,表示资源最后修改时间。If-Modified-Since(保存Last-Modified的值)字段。服务端收到这个请求后,将If-Modified-Since与当前的最后修改时间进行对比。如果相等则可以协商缓存。不相等则将资源重新响应。由于last-modified依赖的是保存的绝对时间,还是会出现误差的情况:
etag。ETag和If-None-Matchetag是http协议提供的若干机制中的一种Web缓存验证机制,并且允许客户端进行缓存协商。生成etag常用的方法包括对资源内容使用抗碰撞散列函数,使用最近修改的时间戳的哈希值,甚至只是一个版本号。 和last-modified一样.
etag的值,然后再下一次请求在request header中带上if-none-match:[保存的etag的值]。etag的值和服务端重新生成的etag的值进行比对,如果一致代表资源没有改变,服务端返回正文为空的响应,告诉浏览器从缓存中读取资源。etag能够解决last-modified的一些缺点,但是etag每次服务端生成都需要进行读写操作,而last-modified只需要读取操作,从这方面来看,etag的消耗是更大的。
二者对比
Etag要优于Last-Modified。Etag。Etag要逊于Last-Modified当浏览器再次访问一个已经访问过的资源时,它会这样做:
304 告诉浏览器使用本地缓存;标签:工作原理 参与 机制 理解 报文 vat 影响 技术 xss
原文地址:https://www.cnblogs.com/chuncode/p/13336667.html